企业级多智能体设计实战
3951 人已学习
新⼈⾸单¥59
课程目录
已更新 25 讲/共 42 讲
课程介绍 (1讲)

时长 26:34
架构思维篇:AI 时代的设计模式 (4讲)
时长 27:35
时长 35:17
时长 28:09
工程落地篇:从0构建生产级多智能体系统 (2讲)
时长 20:14
时长 29:49
模块一:运行你的第一个企业级 Multi-Agent (5讲)
时长 38:37
时长 33:54
时长 32:50
时长 30:28
时长 42:50
模块二:工具大全,赋予Agent与物理世界交互的能力 (6讲)
时长 37:34
时长 34:07
时长 35:14
时长 36:40
时长 01:06:26
时长 40:09
模块三:上下文管理让Agent拥有记忆,突破Token限制 (5讲)
时长 22:13
时长 39:19
时长 38:12
时长 49:37
时长 28:57
直播回放 (2讲)
时长 01:38:40
时长 01:47:52
企业级多智能体设计实战
登录|注册
当前播放: 22|项目实战3:XiaoPaw记忆篇:打造懂你的长记忆助手
00:00 / 00:00
高清
- 高清
1.0x
- 3.0x
- 2.5x
- 2.0x
- 1.5x
- 1.25x
- 1.0x
- 0.75x
- 0.5x
付费课程,可试看

课程介绍|告别“野路子”:转型企业级多智能体架构师
01|拨开迷雾:AI 应用开发的四种架构范式
02|解构智能体:Agent 的解剖学与 ReAct 范式
03|Multi-Agent系统:Agent、Task、Process的协作美学
04|架构师的决断:AI 应用开发选型工具
05|工程全景图:构建企业级多智能体系统的“施工蓝图”
06|工欲善其器:课程学习的基础代码环境准备
07|定义Agent:从“提示词工程”到“人设工程”
08|定义Task——从“步骤控制”到“契约驱动”
09|定义 Process——任务调度与信息传递
10|多模态模型:让你的 Agent 拥有“眼睛”
11|项目实践(一):小红书爆款笔记生成项目
12|工具设计哲学:从 API 到 Agent-Native 的范式跃迁
13|自定义工具封装:构建 Tools 的五步标准 SOP
14|MCP协议:标准化定义工具接口
15|王牌超能力:代码解释器与无头浏览器
16|Skills生态:让Agent接入大量工具
17|项目实战2:能力篇——XiaoPaw飞书本地工作助手
18|从 Prompt 到 Harness:记忆与上下文的设计范式
19|上下文的生命周期:Bootstrap、剪枝与压缩
20|文件系统记忆:让Agent自己写记忆、自己学技能
21|搜索驱动的记忆系统:企业级海量记忆管理方案
22|项目实战3:XiaoPaw记忆篇:打造懂你的长记忆助手
直播回放|爆火全网的OpenClaw强在哪儿?
直播回放|吃透 Claude Code 核心源码:架构设计与工程细节全解析
本节摘要
欢迎回来!上一节课,我们给 XiaoPaw 建立了搜索驱动的记忆系统——用 pgvector 把每一轮对话向量化入库,让 Agent 能精准召回几个月前的某次分析结论。至此,三层记忆的最后一块拼图落地了。
但学完 19、20、21 课,你心里可能有一个问题:这三层能力,怎么在一个真实产品里协同工作? 光懂原理不够,还得看得见、用得上。这就是今天这节课要做的事:我们把 L19 上下文层、L20 文件层、L21 搜索层全部集成进来,把 XiaoPaw 从一个工具升级成一个真正懂你的长记忆助手。
这是模块三的收官实战。把它跑通之后,你就拥有了一个可以真正交付的、带完整记忆系统的 AI 助手工程模板。
一、需求分析:模块三开篇留的坑,今天来填
还记得第 18 课吗?我们当时拿 XiaoPaw 做解剖,找出了它最致命的四个记忆缺陷。
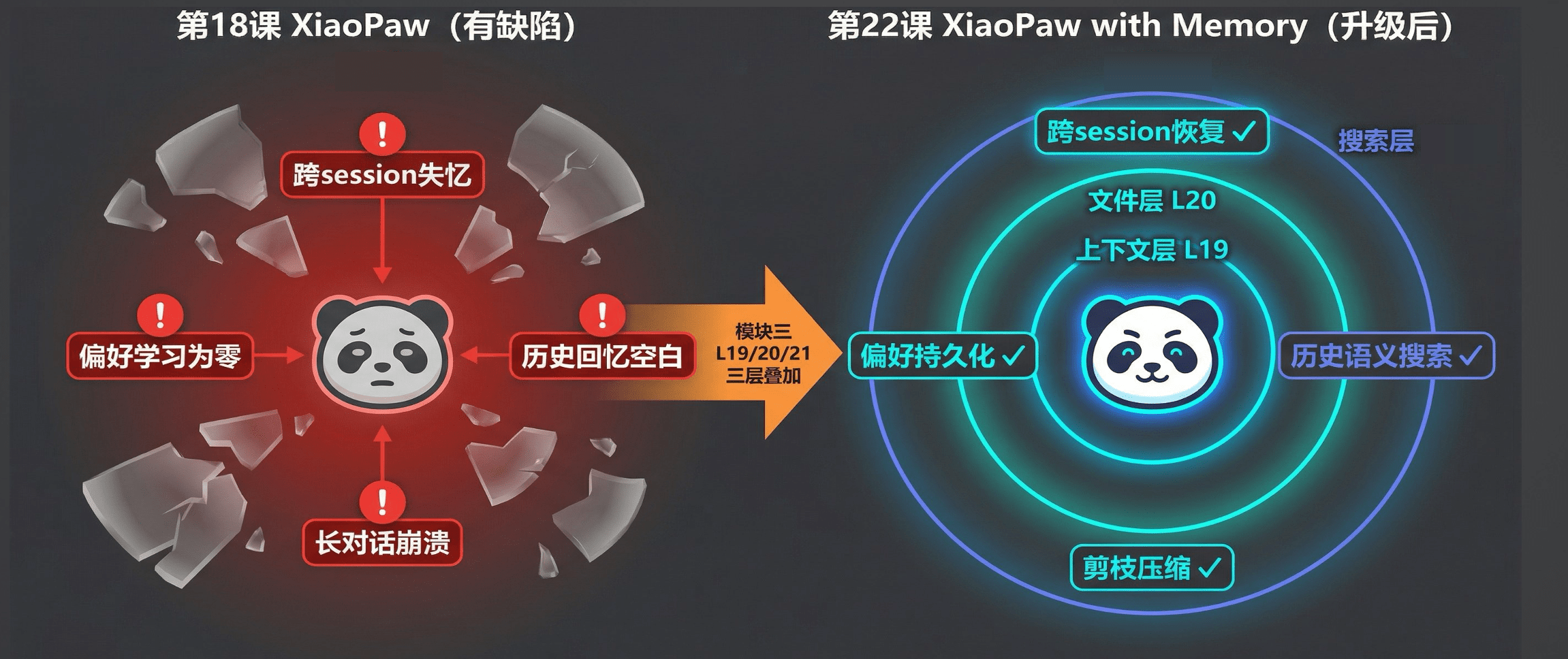
从图里可以看到,左边那只茫然的小爪子有四个硬伤:
-
跨 session 失忆:你昨天跟它说的所有话,今天重启之后全忘。每次对话都是从陌生人开始。
-
长对话崩溃:聊太久了,token 超限,直接报错。工具越强大,这个问题越刺眼。
-
偏好学习为零:你说了一百遍"别用表格",它下次还用。没有持久化写通道,说再多都白说。
-
历史回忆空白:问"我上次那个投资分析结论是什么",一问三不知。当时就算跟它聊过,它也完全想不起来。

登录 后留言
全部留言(1)
- 最新
- 精选
Aaaaaaaaaaayou
这门课真的学到了好多,太值了
2026-04-15
收起评论