企业级多智能体设计实战
3127 人已学习
新⼈⾸单¥59
课程目录
已更新 12 讲/共 42 讲
课程介绍 (1讲)

时长 26:34
架构思维篇:AI 时代的设计模式 (4讲)
时长 27:35
时长 35:17
时长 28:09
工程落地篇:从0构建生产级多智能体系统 (2讲)
时长 20:14
时长 29:49
模块一:运行你的第一个企业级 Multi-Agent (4讲)
时长 38:37
时长 33:54
时长 32:50
时长 30:28
直播回放 (1讲)
时长 01:38:40
企业级多智能体设计实战
登录|注册
当前播放: 10|多模态模型:让你的 Agent 拥有“眼睛”
00:00 / 00:00
高清
- 高清
1.0x
- 3.0x
- 2.5x
- 2.0x
- 1.5x
- 1.25x
- 1.0x
- 0.75x
- 0.5x
付费课程,可试看

课程介绍|告别“野路子”:转型企业级多智能体架构师
01|拨开迷雾:AI 应用开发的四种架构范式
02|解构智能体:Agent 的解剖学与 ReAct 范式
03|Multi-Agent系统:Agent、Task、Process的协作美学
04|架构师的决断:AI 应用开发选型工具
05|工程全景图:构建企业级多智能体系统的“施工蓝图”
06|工欲善其器:课程学习的基础代码环境准备
07|定义Agent:从“提示词工程”到“人设工程”
08|定义Task——从“步骤控制”到“契约驱动”
09|定义 Process——任务调度与信息传递
10|多模态模型:让你的 Agent 拥有“眼睛”
直播回放|爆火全网的OpenClaw强在哪儿?
本节摘要
欢迎回来!在前面的课程中,我们已经系统学习了 Task(任务)、Agent(智能体)以及 Process(流程)这“三剑客”,打通了多智能体协作的骨干框架。作为这个模块的最后一个单元环节,今天我们将做一些非常有意思的事情:让你的 Agent 拥有“眼睛”,去直观地感知这个具象的世界。
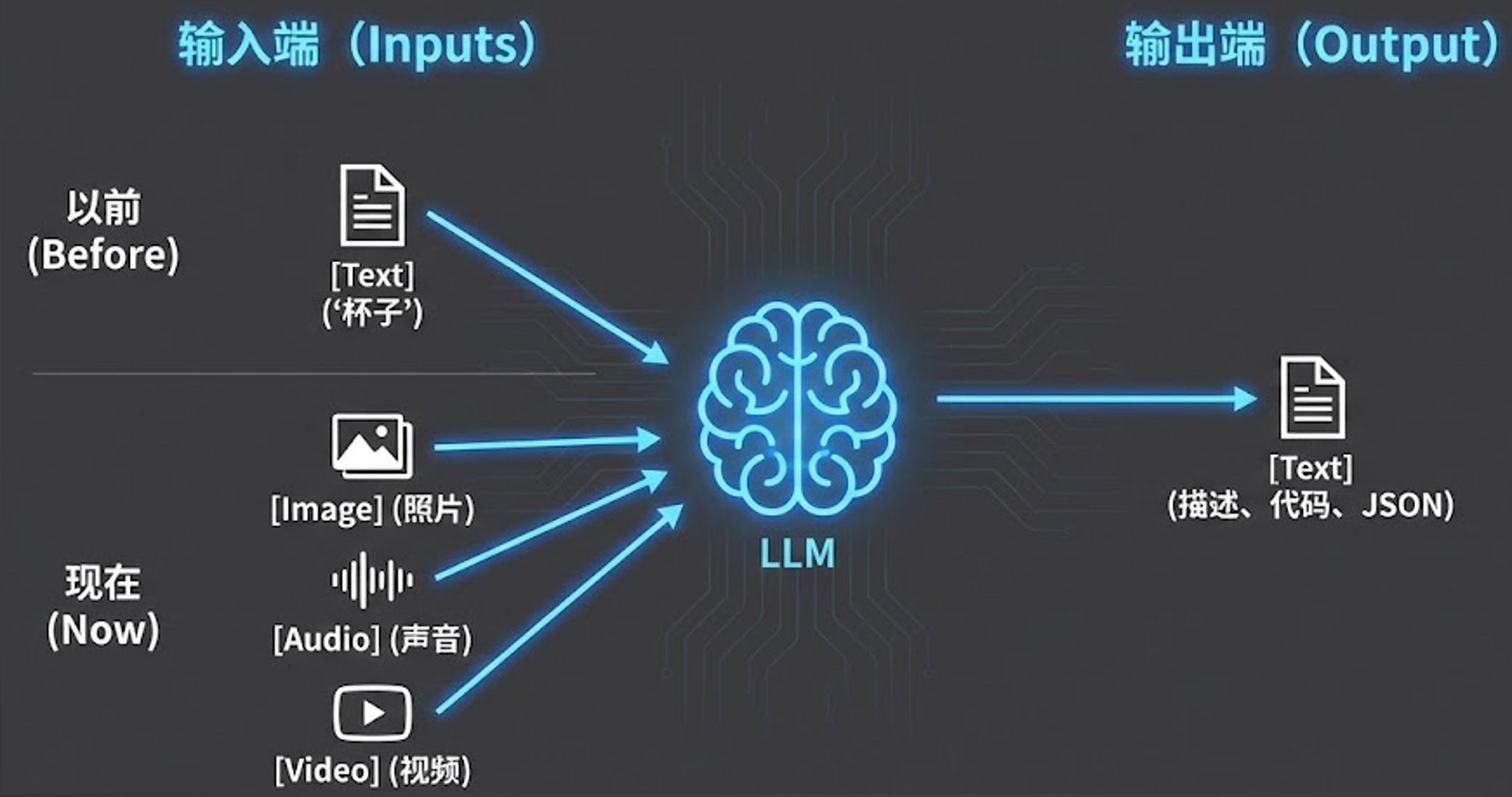
在真实的生产场景中,很多时候我们面对的不仅仅是纯文本信息,还包含大量其他模态的数据(如图片、视频、声音等)。如何让智能体跨越单一的文本模态,是构建复杂企业级 AI 应用的关键一步。
一、 认知原点:什么是多模态文本生成模型?
首先,我们需要明确一个核心概念的边界。一提到“多模态”或“图片大模型”,很多人脑海里第一反应是 Midjourney 或者 Stable Diffusion 这类“文生图”(Text-to-Image)工具。但我们这节课要讲的,是完全相反的方向——多模态的文本生成模型(Image-to-Text / Multimodal Understanding)。
我们的目标是输入图片、声音或视频等多模态素材,让模型进行处理和理解,最终输出我们需要的文字结果或结构化数据。
1. 底层原理解析:模型如何“看懂”图片?
大语言模型(LLM)的本质是在做 Token 的预测(Predict the next token)。那么,一个原本只能处理文本序列的模型,是如何看懂一张具象的图片的呢?

登录 后留言
精选留言
由作者筛选后的优质留言将会公开显示,欢迎踊跃留言。
收起评论