企业级多智能体设计实战
2223 人已学习
新⼈⾸单¥59
课程目录
已更新 7 讲/共 42 讲
课程介绍 (1讲)

时长 26:34
架构思维篇:AI 时代的设计模式 (4讲)
时长 27:35
时长 35:17
时长 28:09
工程落地篇:从0构建生产级多智能体系统 (1讲)
时长 20:14
直播回放 (1讲)
时长 01:38:40
企业级多智能体设计实战
登录|注册
当前播放: 05|工程全景图:构建企业级多智能体系统的“施工蓝图”
00:00 / 00:00
高清
- 高清
1.0x
- 3.0x
- 2.5x
- 2.0x
- 1.5x
- 1.25x
- 1.0x
- 0.75x
- 0.5x
付费课程,可试看

课程介绍|告别“野路子”:转型企业级多智能体架构师
01|拨开迷雾:AI 应用开发的四种架构范式
02|解构智能体:Agent 的解剖学与 ReAct 范式
03|Multi-Agent系统:Agent、Task、Process 的协作美学
04|架构师的决断:AI 应用开发选型工具
05|工程全景图:构建企业级多智能体系统的“施工蓝图”
直播回放|爆火全网的OpenClaw强在哪儿?
本节摘要
欢迎回来!在前面的四节课中,我们主要停留在“架构思维篇”,带领大家理清了四种核心范式以及选型决策模型。 那么从这第五节课开始,我们将正式跨入“工程篇”的大门,进入到极其硬核的实战落地环节。
在真正开始写代码之前,我们需要先完成一项极其重要的准备工作:画好施工蓝图。
一、 告别“野路子”:从玩具 Demo 到企业级生产
很多开发者在刚接触大模型应用时,通常会看几个网上的开源教程,用几行代码跑通一个 Demo。 在命令行里看到模型成功回复了一段话,就觉得非常有成就感。
但是,当你试图把这个 Demo 搬到真实的业务系统和企业生产环境中时,你会立刻遭遇无数“毒打”:
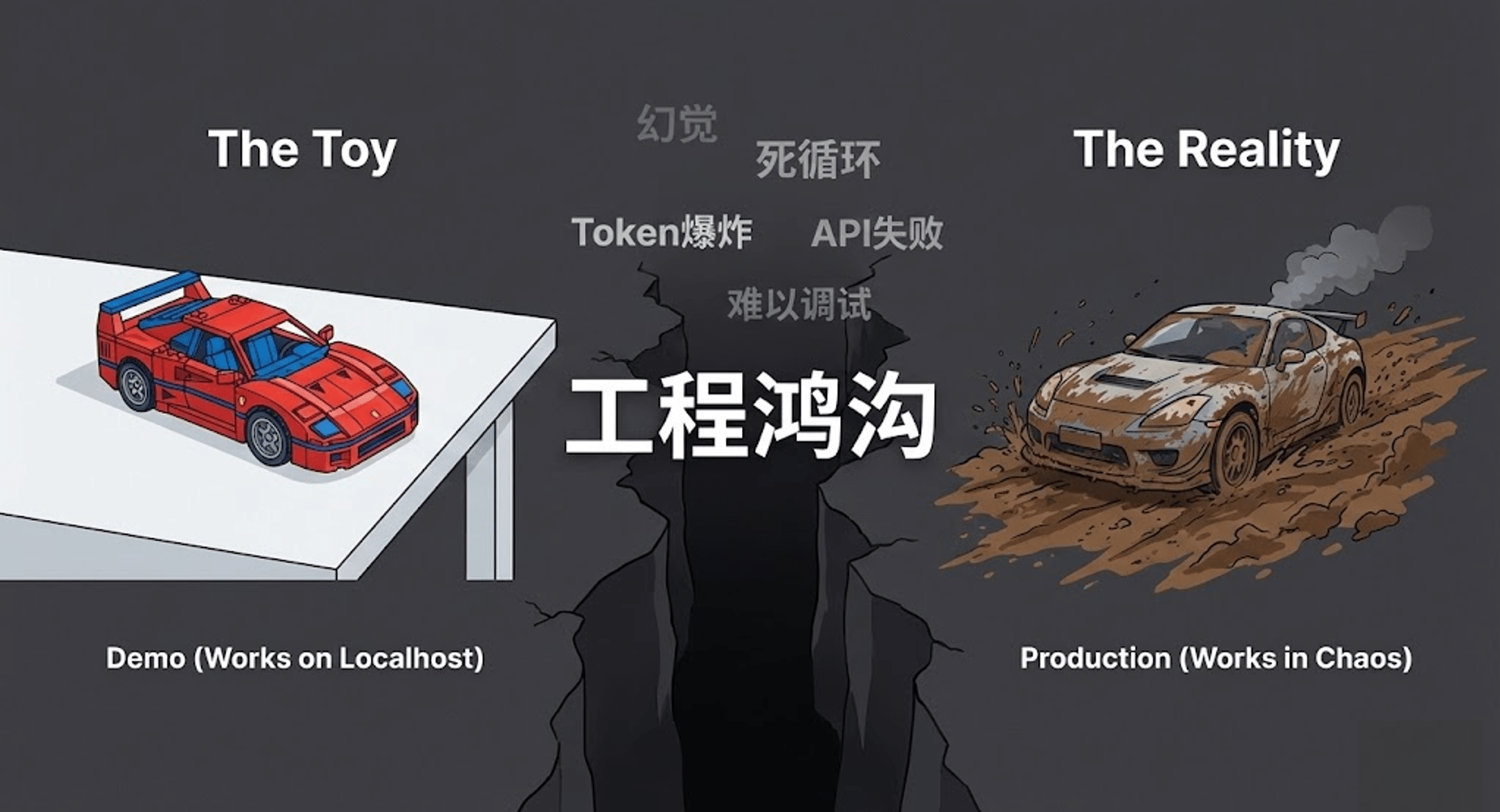
-
稳定性极差:大模型经常产生幻觉,或者格式输出错误导致代码崩溃。
-
上下文失控:多轮对话或工具调用后,上下文长度爆炸,模型开始胡言乱语。
-
不可观测与难以排查:一旦线上出错,由于整个系统是个黑盒,你根本不知道是哪一步的 Prompt 写坏了,还是哪个 Tool 返回了异常数据。
这些痛点的根源在于:我们用做玩具的思维,去盖企业级的大楼。 要想跨越这条鸿沟,我们就必须告别“野路子”,建立起“正规军”的工程化体系。
二、 穿透技术本质:“五步认知法”
在接下来的工程篇中,我们会接触到大量且高频迭代的 AI 概念(比如 Memory、Skill、RAG、Guardrails 等)。 其实这些的一切都是设计模式。从宏观的角度,会有 AI 应用的架构模式,而具体到每个技术点的设计,也会有很多微观的最佳实践。

登录 后留言
全部留言(2)
- 最新
- 精选
Bravemen
日常学习还是零碎为主,就像现在的AI模式一样,因为往往没有场景/精力,去彻底理解一个新概念,但有时间还是值得好好总结的,只有认真打结、消化后的才能转化为能输出的
2026-03-06
Bravemen
请教一个问题,上次听老师说PPT都是用notebookLM生成的,自测过程发现中文有很多错别字,老师的PPT是怎么优化的呢?求指点
2026-03-06
收起评论