

- 高清
- 3.0x
- 2.5x
- 2.0x
- 1.5x
- 1.25x
- 1.0x
- 0.75x
- 0.5x

欢迎回来!接下来我们将正式进入整套课程的重头戏——Multi-Agent(多智能体)系统。
在上一节课中,我们深入解剖了单 Agent 的 ReAct 算法,它看起来已经非常强大且优雅了。但我在课后留了一个悬念:既然 ReAct 这么好,为什么在实际落地中还会遇到诸多难以逾越的瓶颈?为什么我们一定要引入复杂的 Multi-Agent 系统?
这节课,我们就从单 Agent 的“崩溃时刻”讲起,带你一步步理解 Agent、Task 与 Process 之间精妙的协作美学。
一、单 Agent 的崩溃:当“上下文”变成“垃圾场”
单 Agent 在处理简单任务时游刃有余,但一旦面对复杂、长链路的企业级任务,它的上下文就会彻底崩溃,变成一个不堪重负的“垃圾场”。
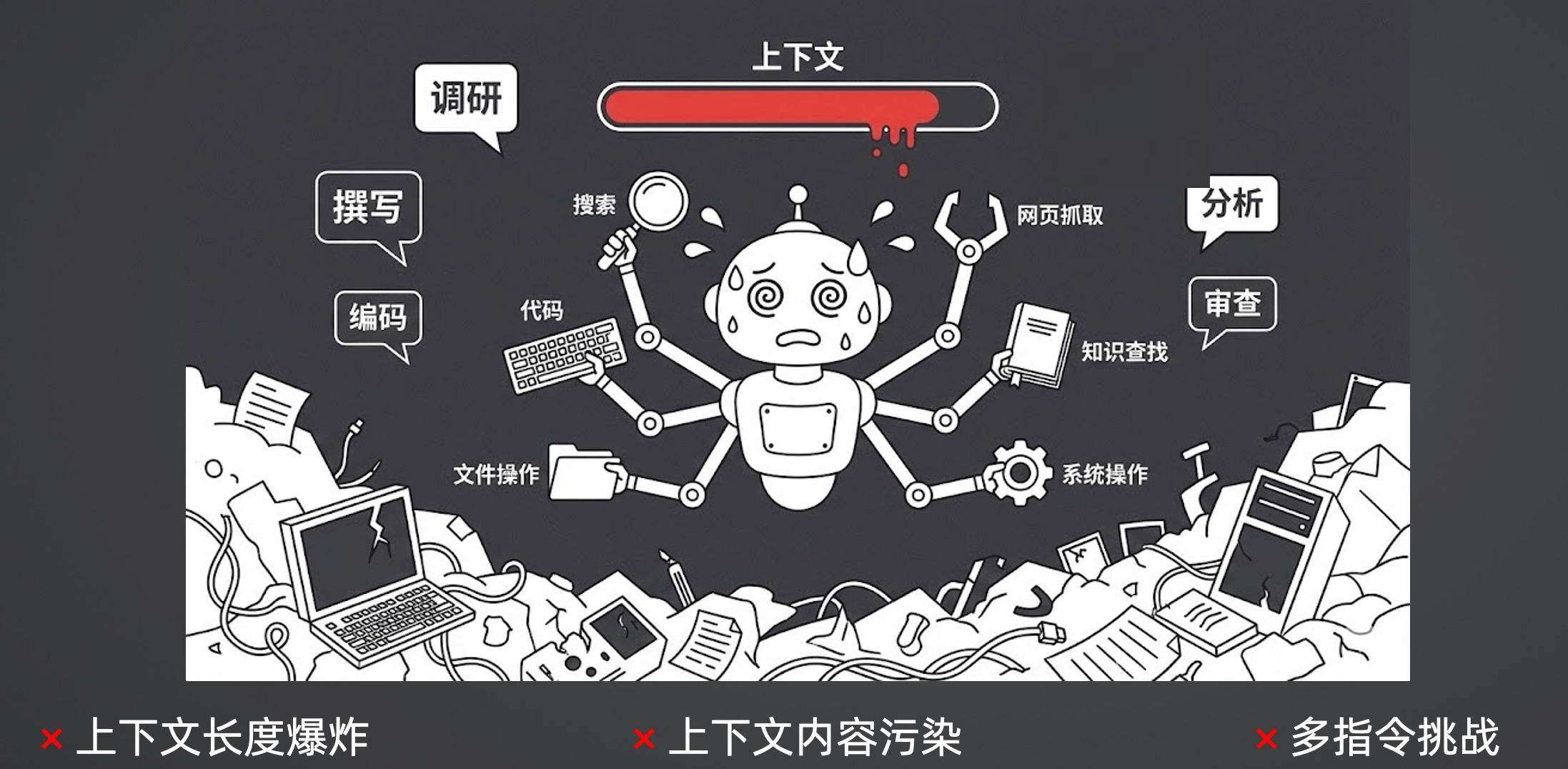
具体来说,单 Agent 面临着三大致命挑战:
-
上下文长度爆炸:ReAct 的核心逻辑是不断将工具执行的结果追加到上下文中。如果它进行了三次搜索、读取了五六个网页,上下文很容易突破五六万 Tokens。当上下文过长时,大模型的推理速度和指令遵循能力会断崖式下降。
-
上下文内容污染:这是很多人容易忽略的痛点。大模型基于 Transformer 架构,本质是预测下一个 Token,因此它极易受前文干扰。举个实战例子:如果你在一个上下文里先让模型开启
Thinking(思考过程)写了一份报告,接着直接在同一个上下文里让它“客观评价这份报告”,它往往会顺着自己之前的Thinking疯狂自夸,失去客观性。而如果新开一个干净的上下文,它的评价就会客观得多。 -
多指令挑战:单 Agent 就像一个全能打工人,如果你同时塞给它搜索、写代码、文件操作、知识检索等几十个工具,光是工具的 Schema 描述就会占满上下文。在执行过程中,它极容易因为注意力分散而选错工具或捏造错误参数,导致整个 ReAct 循环直接卡死。

全部留言(1)
- 最新
- 精选