

17 | 高性能缓存架构

该思维导图由 AI 生成,仅供参考
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

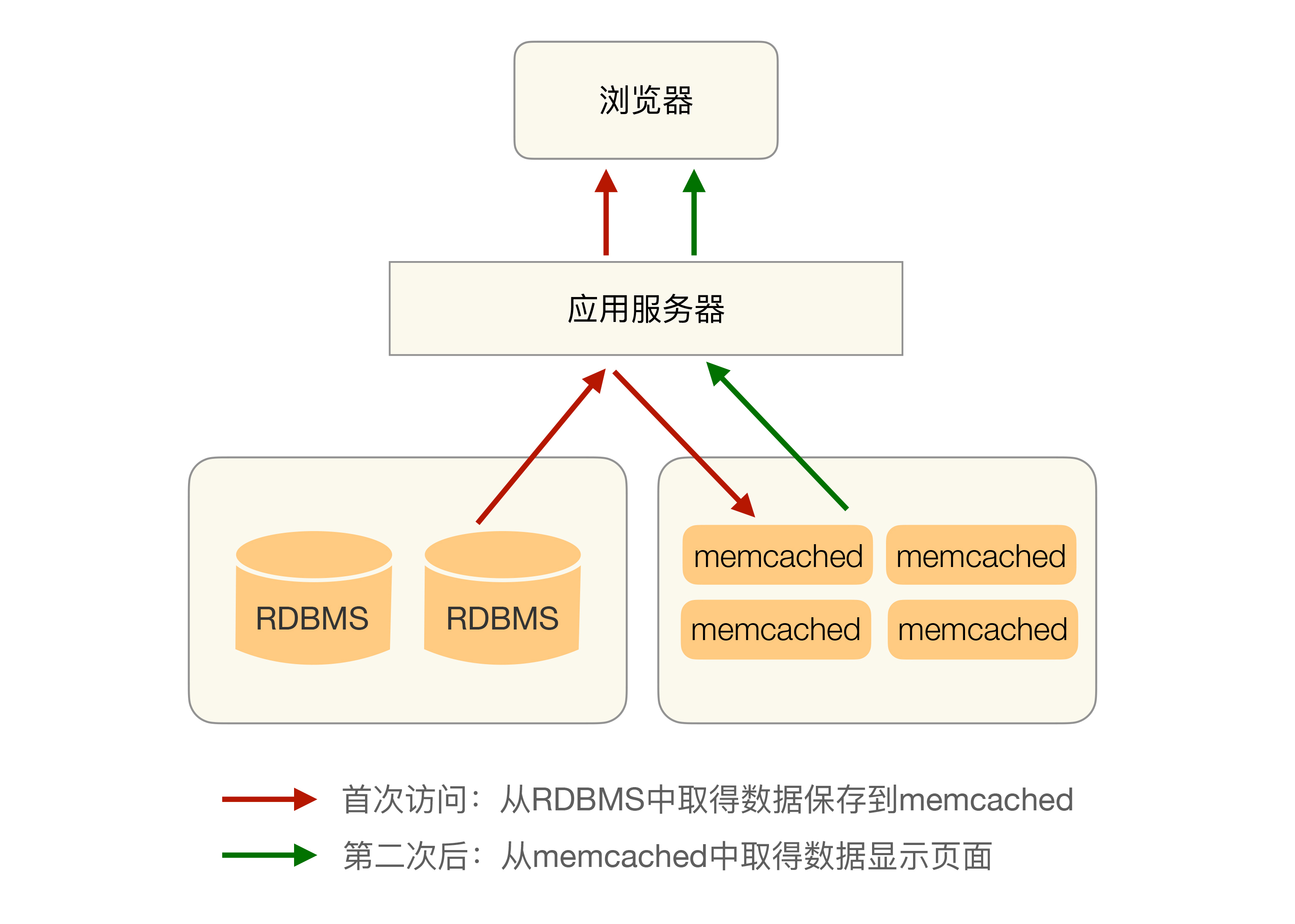
缓存在高性能架构设计中扮演着重要角色,然而缓存穿透和缓存雪崩等问题可能会影响系统性能。缓存穿透指的是缓存未命中,导致频繁查询存储系统,而缓存雪崩则是缓存失效导致系统性能急剧下降。解决这些问题的方法包括设置默认值、监控异常情况、更新锁机制和后台更新机制。此外,针对缓存热点问题,可以通过复制多份缓存副本并设置不同的过期时间范围来分散请求压力。在实现方式上,缓存设计通常集成在存储访问方案中,采用中间层方式或独立中间件实现。这些关键点虽然技术上不复杂,但对业务影响深远,架构师在设计架构时需特别注意。读者可通过深度思考业务中因缓存导致的问题及解决方案,加深对知识的理解。整体而言,本文深入剖析了高性能缓存架构设计的关键要点,为读者提供了全面的技术视角。
《从 0 开始学架构》,新⼈⾸单¥68

全部留言(135)
- 最新
- 精选
 bluefantasy我们的系统就出现过类似的问题,开始的时候没有缓存,每次做活动访问量大的时候就会导致反应特别慢。后来通过加redis缓存解决了问题。 对于缓存雪崩问题,我们采取了双key策略:要缓存的key过期时间是t,key1没有过期时间。每次缓存读取不到key时就返回key1的内容,然后触发一个事件。这个事件会同时更新key和key1。
bluefantasy我们的系统就出现过类似的问题,开始的时候没有缓存,每次做活动访问量大的时候就会导致反应特别慢。后来通过加redis缓存解决了问题。 对于缓存雪崩问题,我们采取了双key策略:要缓存的key过期时间是t,key1没有过期时间。每次缓存读取不到key时就返回key1的内容,然后触发一个事件。这个事件会同时更新key和key1。作者回复: 很有创意👍👍
2018-06-0535364 王磊经常我说到缓存的时候,面试官问我,数据库自身不是有缓存吗,标准答案是怎么回击他?
王磊经常我说到缓存的时候,面试官问我,数据库自身不是有缓存吗,标准答案是怎么回击他?作者回复: 我对mysql比较熟,以下仅限mysql: 1. mysql第一种缓存叫sql语句结果缓存,但条件比较苛刻,程序员不可控,我们的dba线上都关闭这个功能,具体实现可以查一下 2. mysql第二种缓存是innodb buffer pool,缓存的是磁盘上的分页数据,不是sql的查询结果,sql的执行过程省不了。而mc,redis这些实际上都是缓存sql的结果,两种缓存方式,性能差很远。 因此,可控性,性能是数据库缓存和独立缓存的主要区别
2018-06-0511216 loveluckystar讲一个头两天发生的事情,我们的一个业务背后是es做db,之前是通过redis做缓存,缓存一段时间后失效再从es读取,是业务访问加载缓存的方式。有一天线上es集群机器单台出现问题,返回慢,由于分布式的缘故,渐渐拖满了所有请求,缓存失效来查询es发生了超时,加载失败,于是下次访问还是直接访问es。最终缓存全部失效,qps翻了好多倍,直接雪崩,es集群彻底没有响应了。。。之后我们只好先下线这个缓存加载功能,让集群活过来,最终改造缓存加载方式,用后台进程去更新缓存,而不用业务访问加载。
loveluckystar讲一个头两天发生的事情,我们的一个业务背后是es做db,之前是通过redis做缓存,缓存一段时间后失效再从es读取,是业务访问加载缓存的方式。有一天线上es集群机器单台出现问题,返回慢,由于分布式的缘故,渐渐拖满了所有请求,缓存失效来查询es发生了超时,加载失败,于是下次访问还是直接访问es。最终缓存全部失效,qps翻了好多倍,直接雪崩,es集群彻底没有响应了。。。之后我们只好先下线这个缓存加载功能,让集群活过来,最终改造缓存加载方式,用后台进程去更新缓存,而不用业务访问加载。作者回复: 现学现用的案例,很赞👍👍
2018-06-05791 三月沙@wecatch好的缓存方案应该从这几个方面入手设计: 1.什么数据应该缓存 2.什么时机触发缓存和以及触发方式是什么 3.缓存的层次和粒度( 网关缓存如 nginx,本地缓存如单机文件,分布式缓存如redis cluster,进程内缓存如全局变量) 4.缓存的命名规则和失效规则 5.缓存的监控指标和故障应对方案 6.可视化缓存数据如 redis 具体 key 内容和大小
三月沙@wecatch好的缓存方案应该从这几个方面入手设计: 1.什么数据应该缓存 2.什么时机触发缓存和以及触发方式是什么 3.缓存的层次和粒度( 网关缓存如 nginx,本地缓存如单机文件,分布式缓存如redis cluster,进程内缓存如全局变量) 4.缓存的命名规则和失效规则 5.缓存的监控指标和故障应对方案 6.可视化缓存数据如 redis 具体 key 内容和大小作者回复: 确实,细节不少,可以写本书了😃
2018-06-05383 一叶笔记: 书籍: 《高性能Mysql》 《unix编程艺术》:宁花机器一分,不花程序员一秒 提升性能: 先单机,有压力后优先考虑sql优化、db参数调优,还有硬件性能(32核/16G/SSD)优化,不行还可以再考虑业务逻辑优化、缓存。不要一上来就读写分离、集群等,能单库搞定的就毫不犹豫的单库。 --- 主从读写分离 适用于单机无法应付所有请求,且读比写多时,读写分离还可以分别针对读写节点建索引来优化。 对实时性要求不高:刚写入就读会有延迟,同步数据特别大时,延迟可能达到分钟级(可用缓存解决:2-8原则,挑选占访问量80%的前20%来缓存)。 TODO主从还能设置自增长key不一样? 分库分表(甚用,增加很多复杂度) 几千万或上亿 分库时机:单机性能瓶颈,1业务不复杂,但整体数据量影响到数据库性能;2业务复杂,需要分系统由不同团队开发,使用分库减少团队耦合。(分库导致不能join和事务(有方案但性能太低用了跟没分库差别不大,用最终一致性/事件驱动)) 分表时机:单表数据量大拖慢了sql性能,做垂直(将常用和不常用字段分开)或水平拆分(id分段、hash路由、添加路由表等)提高速度。(那么join、count、分页排序等就变得复杂) TODO环状hash 一致性hash? nosql (nosql——not noly sql 本质上是牺牲ACID中的某个或某几个属性,以解决关系数据库某些复杂的问题) 关系数据库:强大的sql功能和ACID属性,发展了几十年技术相当成熟 Mysql / Postgresql k-v存储:解决关系数据库无法存储数据结构的问题 Redis / Memcache (redis不太适合key的value特别大,这种情况会导致整个redis变慢,这种场景mc更好->参考IO模型 redis单Reactor单进程读写大value会阻塞所有业务 持久化也会) 文档数据库:解决关系数据库强schema约束,查询不存在的列会报错,扩充很麻烦还会长时间锁表 MongoDB 列式数据库:解决关系数据库处理大数据分析或统计时IO高的问题,关系数据库即使只处理某列也会把整行查询到内存中 HBase / Greenplum 全文搜索引擎:解决关系数据库全文搜索like扫描全表性能问题 ElasticSearch / solr LevelDB 内存型? 时序数据库?:实时计算统计实时监控 influxDB OLAP OLTP HTAP? 缓存(千万千万不要设计复杂的缓存,到时候各种不一致问题烦死你) cdn、nginx缓存、网关缓存、数据层缓存redis、db本身也有缓存(sql结果缓存、读取的磁盘分页缓存) 缓存穿透:1本身无数据(添加默认值缓存/布隆过滤器[整型自增key?]) 2未生成缓存(识别爬虫并禁止 但可能影响seo) 缓存雪崩:缓存实效后大家都在更新缓存导致系统性能急剧下降(1消息队列通知后台更新、2使用分布式更新锁) 缓存热点:大部分业务都会命中的同一份缓存,比如1000w+粉丝的微博消息,复制多分缓存副本,key里面加副本编号将请求分散,且设置过期范围,而不是所有副本固定同一过期时间。 缓存框架看一下设计思路:echcache、网友分享https://github.com/qiujiayu/AutoLoadCache
一叶笔记: 书籍: 《高性能Mysql》 《unix编程艺术》:宁花机器一分,不花程序员一秒 提升性能: 先单机,有压力后优先考虑sql优化、db参数调优,还有硬件性能(32核/16G/SSD)优化,不行还可以再考虑业务逻辑优化、缓存。不要一上来就读写分离、集群等,能单库搞定的就毫不犹豫的单库。 --- 主从读写分离 适用于单机无法应付所有请求,且读比写多时,读写分离还可以分别针对读写节点建索引来优化。 对实时性要求不高:刚写入就读会有延迟,同步数据特别大时,延迟可能达到分钟级(可用缓存解决:2-8原则,挑选占访问量80%的前20%来缓存)。 TODO主从还能设置自增长key不一样? 分库分表(甚用,增加很多复杂度) 几千万或上亿 分库时机:单机性能瓶颈,1业务不复杂,但整体数据量影响到数据库性能;2业务复杂,需要分系统由不同团队开发,使用分库减少团队耦合。(分库导致不能join和事务(有方案但性能太低用了跟没分库差别不大,用最终一致性/事件驱动)) 分表时机:单表数据量大拖慢了sql性能,做垂直(将常用和不常用字段分开)或水平拆分(id分段、hash路由、添加路由表等)提高速度。(那么join、count、分页排序等就变得复杂) TODO环状hash 一致性hash? nosql (nosql——not noly sql 本质上是牺牲ACID中的某个或某几个属性,以解决关系数据库某些复杂的问题) 关系数据库:强大的sql功能和ACID属性,发展了几十年技术相当成熟 Mysql / Postgresql k-v存储:解决关系数据库无法存储数据结构的问题 Redis / Memcache (redis不太适合key的value特别大,这种情况会导致整个redis变慢,这种场景mc更好->参考IO模型 redis单Reactor单进程读写大value会阻塞所有业务 持久化也会) 文档数据库:解决关系数据库强schema约束,查询不存在的列会报错,扩充很麻烦还会长时间锁表 MongoDB 列式数据库:解决关系数据库处理大数据分析或统计时IO高的问题,关系数据库即使只处理某列也会把整行查询到内存中 HBase / Greenplum 全文搜索引擎:解决关系数据库全文搜索like扫描全表性能问题 ElasticSearch / solr LevelDB 内存型? 时序数据库?:实时计算统计实时监控 influxDB OLAP OLTP HTAP? 缓存(千万千万不要设计复杂的缓存,到时候各种不一致问题烦死你) cdn、nginx缓存、网关缓存、数据层缓存redis、db本身也有缓存(sql结果缓存、读取的磁盘分页缓存) 缓存穿透:1本身无数据(添加默认值缓存/布隆过滤器[整型自增key?]) 2未生成缓存(识别爬虫并禁止 但可能影响seo) 缓存雪崩:缓存实效后大家都在更新缓存导致系统性能急剧下降(1消息队列通知后台更新、2使用分布式更新锁) 缓存热点:大部分业务都会命中的同一份缓存,比如1000w+粉丝的微博消息,复制多分缓存副本,key里面加副本编号将请求分散,且设置过期范围,而不是所有副本固定同一过期时间。 缓存框架看一下设计思路:echcache、网友分享https://github.com/qiujiayu/AutoLoadCache作者回复: 很用心,赞👍
2018-09-23269 mapping计算机界两大难题:命名和缓存过期。没用缓存的时候,想着怎么用缓存提升性能,用了缓存又担心数据更新不及时。技术上希望所有的请求都能命中缓存,业务上又恨不得数据实时最新。所以就会引入各种缓存过期策略,如设置过期时间,按规则删除,打版本。这些应该在前期设计缓存系统时规划好,我们最早是将 sql md5 作 key 查询结果存入缓存,结果业务系统数据不一致,要清除缓存简直是噩梦,只能祭出绝招重启 memcache,后面改成按规则删除,在 key 中加上业务和用户的前缀,可以很方便删除某个业务或某个用户的缓存。以上过期策略在前端浏览器也是这样,最简单就是 web 服务器设置静态资源缓存过期时间,如果业务频繁发新版本,过期时间不宜设置太长,但其实每次变动的文件很少,这种策略会导致大部分缓存命中率不高。按规则删除,早期很多网站上会有诊断助手类的东西,页面加载错误点下诊断助手就帮你清除缓存,原理就是对静态文件逐一带上 no-cache 请求头发送 ajax 请求强制覆盖缓存(跟 DevTools 中 disable cache 原理一样)。打版本其实就相当于让浏览器请求一个新版本文件,对于老版本文件就让它在缓存中自生自灭。
mapping计算机界两大难题:命名和缓存过期。没用缓存的时候,想着怎么用缓存提升性能,用了缓存又担心数据更新不及时。技术上希望所有的请求都能命中缓存,业务上又恨不得数据实时最新。所以就会引入各种缓存过期策略,如设置过期时间,按规则删除,打版本。这些应该在前期设计缓存系统时规划好,我们最早是将 sql md5 作 key 查询结果存入缓存,结果业务系统数据不一致,要清除缓存简直是噩梦,只能祭出绝招重启 memcache,后面改成按规则删除,在 key 中加上业务和用户的前缀,可以很方便删除某个业务或某个用户的缓存。以上过期策略在前端浏览器也是这样,最简单就是 web 服务器设置静态资源缓存过期时间,如果业务频繁发新版本,过期时间不宜设置太长,但其实每次变动的文件很少,这种策略会导致大部分缓存命中率不高。按规则删除,早期很多网站上会有诊断助手类的东西,页面加载错误点下诊断助手就帮你清除缓存,原理就是对静态文件逐一带上 no-cache 请求头发送 ajax 请求强制覆盖缓存(跟 DevTools 中 disable cache 原理一样)。打版本其实就相当于让浏览器请求一个新版本文件,对于老版本文件就让它在缓存中自生自灭。作者回复: 你们的缓存设计有点复杂,还不如调整业务,越复杂的方案越容易出错,参考架构设计原则
2018-06-0526
 公号-技术夜未眠上缓存架构的时候,结合以前的实际经历,会有几个值得注意的地方: 1 哪些数据才真正的需要缓存?缓存也并非银弹。既然允许数据缓存,那么在你是可以接受在一定时间区间内的数据不一致性的。(当然可以做到最终一致性) 2 确定好1后,就需要会数据类型进行分类,比如业务数据缓存,http缓存等 3 根据数据类型及访问特点的不同选择不同缓存类型的技术方案。 请问华仔,热点数据存在相当的突发性,临时的扩容似乎也来不及,能否从缓存架构角度如何避免类似微博宕机的事件?
公号-技术夜未眠上缓存架构的时候,结合以前的实际经历,会有几个值得注意的地方: 1 哪些数据才真正的需要缓存?缓存也并非银弹。既然允许数据缓存,那么在你是可以接受在一定时间区间内的数据不一致性的。(当然可以做到最终一致性) 2 确定好1后,就需要会数据类型进行分类,比如业务数据缓存,http缓存等 3 根据数据类型及访问特点的不同选择不同缓存类型的技术方案。 请问华仔,热点数据存在相当的突发性,临时的扩容似乎也来不及,能否从缓存架构角度如何避免类似微博宕机的事件?作者回复: 1. 限流 2. 容器化+动态化 3. 业务降级,例如限制评论
2018-06-0523 醇梨子华仔,请教一下,针对这种高并发缓存架构设计中,缓存和存储系统一致性问题怎么保证?比如说商品浏览人数,需要存库,然后又需要放缓存,需要频繁更新数据库。
醇梨子华仔,请教一下,针对这种高并发缓存架构设计中,缓存和存储系统一致性问题怎么保证?比如说商品浏览人数,需要存库,然后又需要放缓存,需要频繁更新数据库。作者回复: 没法保证,这类数据允许一定的不一致,一定范围内的对用户也没有影响,不要只从技术的角度考虑问题,结合业务考虑技术
2018-06-17521 鹅米豆发1、最早也是采用后台用数据库,前台用关系型数据库+被动缓存的模式。结果是经常的性能抖动,且缓存一致性问题很难解决。后来我们的多数系统,都采用了前后台分离的模式——后台原始数据仍然是关系型数据库,前台使用缓存作为数据源,两者之间数据实时同步+定时同步+人工触发结合。 这个模式,基本根除了穿透,雪崩,不一致,性能抖动这些。但带来了新的问题,比如数据丢失且不可恢复。我们的做法是,让缓存具备相对可靠的持久化机制+运维体系。 2、遇到过几次热点问题,感觉这个更加棘手些。第一种情况,单Key数据结构本身过大,单个分片出现热点,单次访问的复杂度变大。这个相对容易,可以对key进行拆分,使用hashtag机制分片。第二种情况,数据分片普遍不均衡,较少遇到,遇到就比较棘手。第三种情况,数据分片均衡,但访问不均衡,可以增加副本数量。
鹅米豆发1、最早也是采用后台用数据库,前台用关系型数据库+被动缓存的模式。结果是经常的性能抖动,且缓存一致性问题很难解决。后来我们的多数系统,都采用了前后台分离的模式——后台原始数据仍然是关系型数据库,前台使用缓存作为数据源,两者之间数据实时同步+定时同步+人工触发结合。 这个模式,基本根除了穿透,雪崩,不一致,性能抖动这些。但带来了新的问题,比如数据丢失且不可恢复。我们的做法是,让缓存具备相对可靠的持久化机制+运维体系。 2、遇到过几次热点问题,感觉这个更加棘手些。第一种情况,单Key数据结构本身过大,单个分片出现热点,单次访问的复杂度变大。这个相对容易,可以对key进行拆分,使用hashtag机制分片。第二种情况,数据分片普遍不均衡,较少遇到,遇到就比较棘手。第三种情况,数据分片均衡,但访问不均衡,可以增加副本数量。作者回复: 缓存持久化是一个不错的方法
2018-06-0513 blacknccccc对于像淘宝商品列表筛选项特别多,组合起来会更多,这样在后台做更新缓存怎么处理,难道是把每一种组合的分页数据都缓存下来吗
blacknccccc对于像淘宝商品列表筛选项特别多,组合起来会更多,这样在后台做更新缓存怎么处理,难道是把每一种组合的分页数据都缓存下来吗作者回复: 淘宝的具体实现没有研究,我们有类似的案例,针对常用的分类会统一缓存,缓存会主动更新;不常用的根据查询条件计算md5作为key 进行缓存,缓存时间不长,例如60分钟,防止短时间内大量访问压垮存储,例如爬虫
2018-07-2212

