

15 | 高性能数据库集群:分库分表

该思维导图由 AI 生成,仅供参考
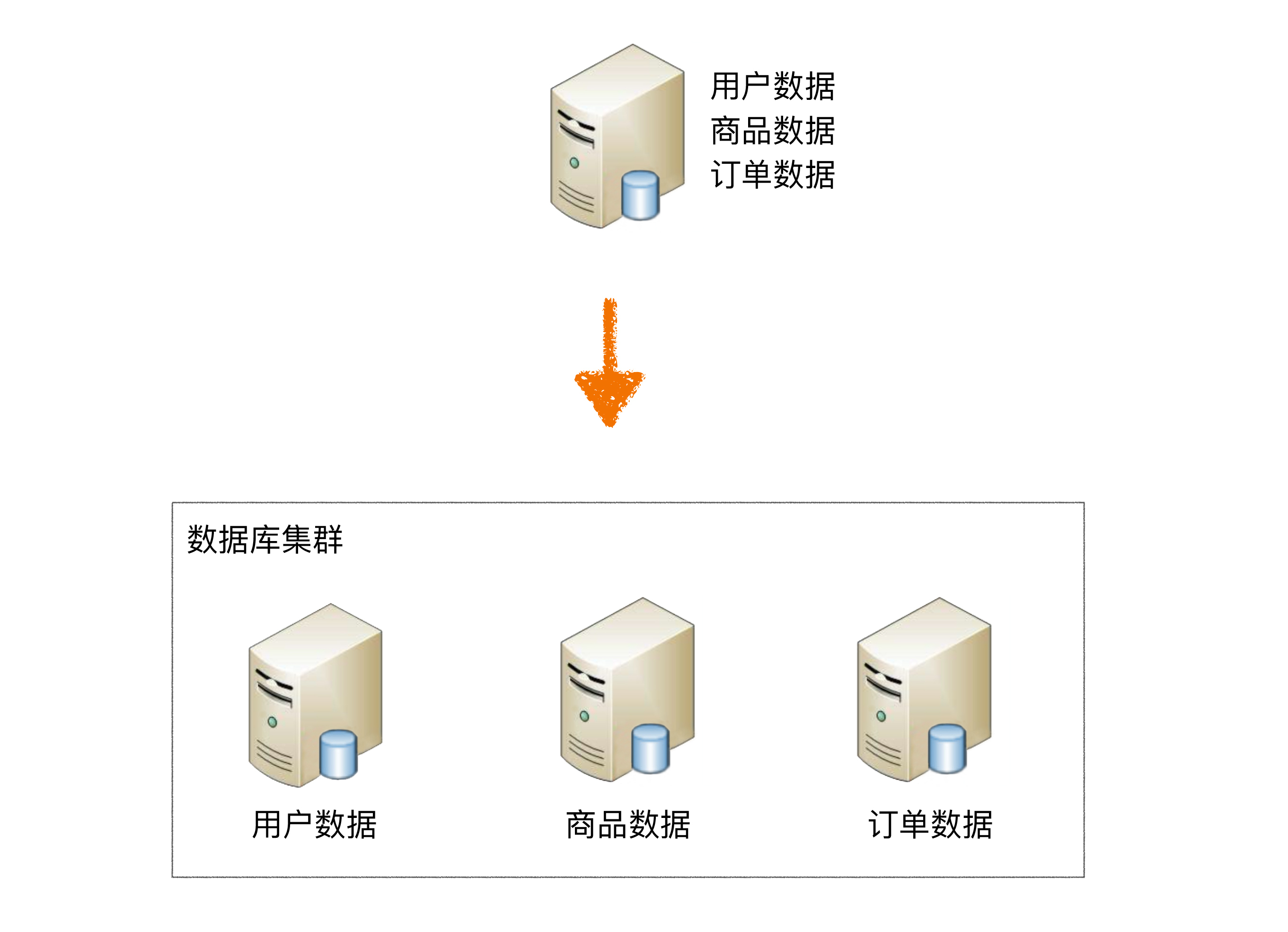
业务分库
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

高性能数据库集群中的分库分表技术是解决单台数据库服务器存储能力瓶颈的重要方案。本文深入介绍了业务分库和分表技术的优势、问题及解决方案。对于初创业务,业务分库可能增加复杂性和成本,不建议一开始就进行分库;而对于成熟大公司来说,业务分库是必要的,因为已有成熟的解决方案和海量用户规模。文章还详细介绍了垂直分表和水平分表的优势、问题及适用场景。特别是水平分表后,排序操作无法在数据库中完成,需要由业务代码或数据库中间件分别查询每个子表中的数据,然后汇总进行排序。总的来说,本文对高性能数据库集群中的分库分表技术进行了深入浅出的介绍,对于想要了解该技术的读者来说,是一篇值得阅读的文章。 文章深入探讨了高性能数据库集群中的分库分表技术,重点介绍了业务分库和分表技术的优势、问题及解决方案。对于初创业务和成熟大公司,分库分表的适用性有所不同,需要根据具体情况来决定是否引入分库分表。此外,文章还详细介绍了垂直分表和水平分表的优势、问题及适用场景,特别强调了水平分表后排序操作的复杂性。总的来说,本文对分库分表技术进行了深入浅出的介绍,对于想要了解该技术的读者来说,是一篇值得阅读的文章。
《从 0 开始学架构》,新⼈⾸单¥68

全部留言(158)
- 最新
- 精选
 明日之春应该是这些操作依次尝试 1.做硬件优化,例如从机械硬盘改成使用固态硬盘,当然固态硬盘不适合服务器使用,只是举个例子 2.先做数据库服务器的调优操作,例如增加索引,oracle有很多的参数调整; 3.引入缓存技术,例如Redis,减少数据库压力 4.程序与数据库表优化,重构,例如根据业务逻辑对程序逻辑做优化,减少不必要的查询; 5.在这些操作都不能大幅度优化性能的情况下,不能满足将来的发展,再考虑分库分表,也要有预估性
明日之春应该是这些操作依次尝试 1.做硬件优化,例如从机械硬盘改成使用固态硬盘,当然固态硬盘不适合服务器使用,只是举个例子 2.先做数据库服务器的调优操作,例如增加索引,oracle有很多的参数调整; 3.引入缓存技术,例如Redis,减少数据库压力 4.程序与数据库表优化,重构,例如根据业务逻辑对程序逻辑做优化,减少不必要的查询; 5.在这些操作都不能大幅度优化性能的情况下,不能满足将来的发展,再考虑分库分表,也要有预估性作者回复: 赞,写的很完善
2018-05-319227 Kongk0ng如果使用hash进行分表的话,为什么大多方案推荐2的n次方作为表的总数,除了收缩容易还有什么好处吗?谢谢
Kongk0ng如果使用hash进行分表的话,为什么大多方案推荐2的n次方作为表的总数,除了收缩容易还有什么好处吗?谢谢作者回复: 这个是hash函数实现的一个技巧,当计算hash值的时候,普通做法是取余操作,例如h%len,但如果len是2的N次方,通过位操作性能更高,计算方式为h & (len-1)
2018-07-101693 帅老师,针对mysql,发现如果字段有blob的字段,select 不写这个字段,和写这个字段,效率差异很大啊,这个是什么原因?一直没弄明白😊 ,谢谢
帅老师,针对mysql,发现如果字段有blob的字段,select 不写这个字段,和写这个字段,效率差异很大啊,这个是什么原因?一直没弄明白😊 ,谢谢作者回复: blob的字段是和行数据分开存储的,而且磁盘上并不是连续的,因此select blob字段会让磁盘进入随机IO模式
2019-03-281385
 公号-技术夜未眠分库分表,可以理解为是一种空间换时间的思路,同时分流了存储压力与读写压力。 数据库性能不够时,首先应该想到是否可以通过改善硬件条件等垂直扩容手段;其次可引入读写分离、缓存/NoSQL、全文检索等手段;然后,单库单表的访问仍然存在性能瓶颈,可考虑分库分表,并且分库分表可以按照业务进行垂直拆分,接着进行水平拆分。 我的问题是:当线上已经进行了分库分表的系统,需要进一步水平扩容时,有什么好的设计方案?
公号-技术夜未眠分库分表,可以理解为是一种空间换时间的思路,同时分流了存储压力与读写压力。 数据库性能不够时,首先应该想到是否可以通过改善硬件条件等垂直扩容手段;其次可引入读写分离、缓存/NoSQL、全文检索等手段;然后,单库单表的访问仍然存在性能瓶颈,可考虑分库分表,并且分库分表可以按照业务进行垂直拆分,接着进行水平拆分。 我的问题是:当线上已经进行了分库分表的系统,需要进一步水平扩容时,有什么好的设计方案?作者回复: 没有太好的方案,要么一开始的分表方案就是按照id范围来设计的,要么就需要数据迁移
2018-05-31346 刘志刚我们公司业务增长比较平稳,已经经历了几个过程, 1.先是最基础的主备,Oracle 扛了3年到15年,中间优化了几次硬件和数据库上的配置 2.到16年左右开始扛不住了,数据量在3千万,但是订单表列太多,导致性能开始不理想,这个时候做了一把分区,性能勉强接受,继续扛着 3.到17年之后做到18年开始做去O项目换MySQL了,顺带着分表和分区了,目前按业务,把一些非核心业务分出去其他库了,订单的库还没分,按照历史年表和热表来做的,做滚表实现的,热表数据差不多在1千万以内,现在性能还不错,历史数据用搜索聚合的,查询性能还不错! 4.到后面如果业务再持续增长的话,估计就要拆订单库了 总结一句话,分库分表要在业务需要之前一点,看数据量和业务特性!
刘志刚我们公司业务增长比较平稳,已经经历了几个过程, 1.先是最基础的主备,Oracle 扛了3年到15年,中间优化了几次硬件和数据库上的配置 2.到16年左右开始扛不住了,数据量在3千万,但是订单表列太多,导致性能开始不理想,这个时候做了一把分区,性能勉强接受,继续扛着 3.到17年之后做到18年开始做去O项目换MySQL了,顺带着分表和分区了,目前按业务,把一些非核心业务分出去其他库了,订单的库还没分,按照历史年表和热表来做的,做滚表实现的,热表数据差不多在1千万以内,现在性能还不错,历史数据用搜索聚合的,查询性能还不错! 4.到后面如果业务再持续增长的话,估计就要拆订单库了 总结一句话,分库分表要在业务需要之前一点,看数据量和业务特性!作者回复: 这样做没错,如果你们12年就开始分库分表,可能当时的方案也不一定适应后来的业务变化
2018-06-06441 Snway我们是在设计初就考虑进去了,预估单表数据容量,再考虑未来三年的数据增长,不过现在反观这种做法,感觉有点过度设计,如当初一张用户表,分了127张,2个库,然而实际数据容量根本没这么多,顶多千万级别,不仅带来存储资源浪费,也给编码带来不少复杂度!所以我还是觉得得遵循演化原则,业务真正发展起来再考虑分库分表
Snway我们是在设计初就考虑进去了,预估单表数据容量,再考虑未来三年的数据增长,不过现在反观这种做法,感觉有点过度设计,如当初一张用户表,分了127张,2个库,然而实际数据容量根本没这么多,顶多千万级别,不仅带来存储资源浪费,也给编码带来不少复杂度!所以我还是觉得得遵循演化原则,业务真正发展起来再考虑分库分表作者回复: 我们也这样做过,后来受不了了又缩表😂😂😂
2018-05-31338 鲁伊李分库分表的痛点大家都知道,可否介绍下解决方案…
鲁伊李分库分表的痛点大家都知道,可否介绍下解决方案…作者回复: 没有很好的,要么中间件要么代码中间层,业务代码处理总是很麻烦的
2018-05-31229 kylexy_0817其实在同一个库里做数据拆分,无需分表吧?就例如MySQL,只需要对表做分区就可以了。分表的目的主要是为后面把表分到不同的数据库实例作准备? 还有个疑问,文中提到,用户表的description等字段内容不是经常查到,所以做垂直划分可以提高查询性能,意思是,如果表中有内容较长的字段,查询的时候不查出来(不使用select *),也会有性能问题? 最后,我觉得当单实例的访问量,已达到机器的60%承载能力,就要考虑分库,而具体如何拆分,则要分析访问量主要集中在哪些表。至于分表,主要依据还是单表的数据量和查询性能。
kylexy_0817其实在同一个库里做数据拆分,无需分表吧?就例如MySQL,只需要对表做分区就可以了。分表的目的主要是为后面把表分到不同的数据库实例作准备? 还有个疑问,文中提到,用户表的description等字段内容不是经常查到,所以做垂直划分可以提高查询性能,意思是,如果表中有内容较长的字段,查询的时候不查出来(不使用select *),也会有性能问题? 最后,我觉得当单实例的访问量,已达到机器的60%承载能力,就要考虑分库,而具体如何拆分,则要分析访问量主要集中在哪些表。至于分表,主要依据还是单表的数据量和查询性能。作者回复: 关系数据库是行存储,即使不用那一列,也会从存储读取到内存
2018-05-31625 耶愿您好!请教一个问题,目前线上业务遇到一个问题,就是订单表需要在单库里分100张表,使用uid%100分的表,前端用户查数据没有问题,后台需要查天、周、月、年的统计信息,这个应该怎么实现?而且要求每行统计记录点击后可以看到该汇总信息下所有的订单记录,这个该怎么做?
耶愿您好!请教一个问题,目前线上业务遇到一个问题,就是订单表需要在单库里分100张表,使用uid%100分的表,前端用户查数据没有问题,后台需要查天、周、月、年的统计信息,这个应该怎么实现?而且要求每行统计记录点击后可以看到该汇总信息下所有的订单记录,这个该怎么做?作者回复: 后台统计库不拆分,冗余一份线上数据,既可以应对复杂的统计需求,也不担心影响线上业务
2018-12-301420 FluttySage老师您好,分库分表后必然会遇见运营人员实时报表查询的问题。单库时,查询实现起来比较简单。 分库之后,查询就变得复杂了,请问有没有比较好的解决思路呢?
FluttySage老师您好,分库分表后必然会遇见运营人员实时报表查询的问题。单库时,查询实现起来比较简单。 分库之后,查询就变得复杂了,请问有没有比较好的解决思路呢?作者回复: 数据写双份,一份给线上用,采用分库分表;一份给运营,不分库分表
2018-07-24417

