

14 | 高性能数据库集群:读写分离

该思维导图由 AI 生成,仅供参考
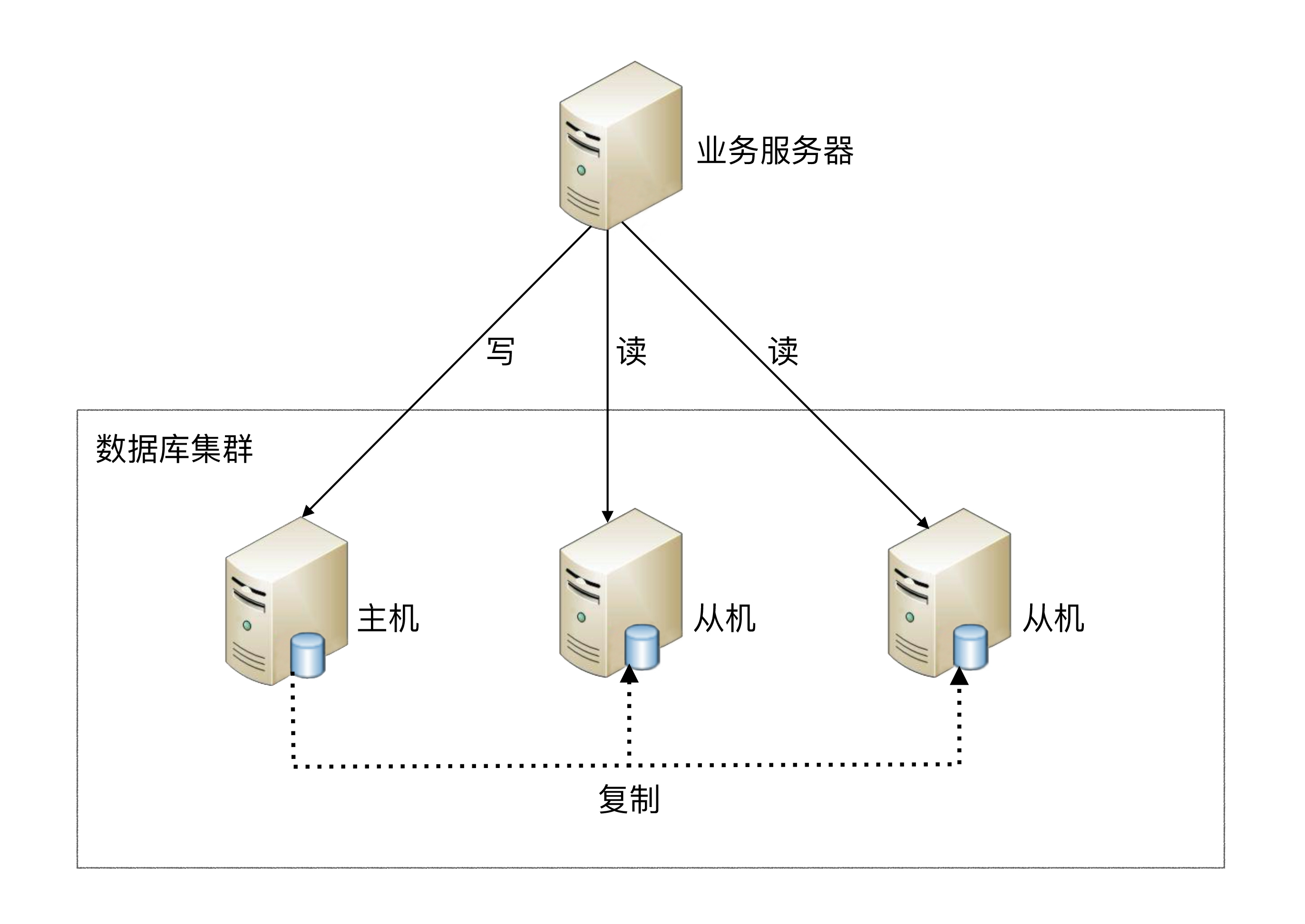
读写分离原理
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

高性能数据库集群中的读写分离架构模式是本文的主题。文章首先介绍了读写分离的基本原理,即通过将数据库读写操作分散到不同节点上,实现数据同步。随后,详细讨论了读写分离中的两个设计复杂度问题:主从复制延迟和分配机制。解决主从复制延迟可能导致数据不一致的问题的方法包括指定读操作发给主服务器、二次读取和关键业务读写操作指向主机。在分配机制方面,文章介绍了程序代码封装和中间件封装两种方式,并讨论了它们的特点和适用场景。最后,文章列举了一些开源的数据库中间件方案,如淘宝的TDDL和奇虎360的Atlas,并对它们的基本架构进行了介绍。总的来说,本文通过深入浅出的方式,详细介绍了读写分离架构模式的原理、实现细节和相关开源方案,对于想要了解高性能数据库集群的读写分离的读者具有很高的参考价值。
《从 0 开始学架构》,新⼈⾸单¥68

全部留言(128)
- 最新
- 精选
 海。老师,您好 我个人的想法是可以加入缓存,例如注册后登录这种业务,可以在注册后加入数据库,并加入缓存,登录的时候先查缓存再查库表。 例如存入redis中并设置十分钟的过期时间。登录的时候先查redis,再查库表,如果redis中没有,说明就是过期的数据,这时候查从机就肯定存在了,希望能得到老师的点评,谢谢。
海。老师,您好 我个人的想法是可以加入缓存,例如注册后登录这种业务,可以在注册后加入数据库,并加入缓存,登录的时候先查缓存再查库表。 例如存入redis中并设置十分钟的过期时间。登录的时候先查redis,再查库表,如果redis中没有,说明就是过期的数据,这时候查从机就肯定存在了,希望能得到老师的点评,谢谢。作者回复: 赞同,并不是说一有性能问题就上读写分离,而是应该先优化,例如优化慢查询,调整不合理的业务逻辑,引入缓存等,只有确定系统没有优化空间后,才考虑读写分离或者集群
2018-05-308256 tangfengr我认为读写分离适用单机并发无法支撑并且读的请求更多的情形。在单机数据库情况下,表上加索引一般对查询有优化作用却影响写入速度,读写分离后可以单独对读库进行优化,写库上减少索引,对读写的能力都有提升,且读的提升更多一些。 不适用的情况:1如果并发写入特别高,单机写入无法支撑,就不适合这种模式。 2 通过缓存技术或者程序优化能够满足要求
tangfengr我认为读写分离适用单机并发无法支撑并且读的请求更多的情形。在单机数据库情况下,表上加索引一般对查询有优化作用却影响写入速度,读写分离后可以单独对读库进行优化,写库上减少索引,对读写的能力都有提升,且读的提升更多一些。 不适用的情况:1如果并发写入特别高,单机写入无法支撑,就不适合这种模式。 2 通过缓存技术或者程序优化能够满足要求作者回复: 赞同👍
2018-07-197127 LONGER目前还在用单机一直在扛着,目前数据量在百万万,在不停的优化,建立冗余等方式,还在保持着一个较快的查询速度,因为业务查询的关系,多表之间的关联,聚合,很难避免,一直想引用缓存,但是查询的条件太多,很动态,就不知道如何设计缓存,类似于京东筛选物品,多品类,多维度筛选,不知道大牛有何高见
LONGER目前还在用单机一直在扛着,目前数据量在百万万,在不停的优化,建立冗余等方式,还在保持着一个较快的查询速度,因为业务查询的关系,多表之间的关联,聚合,很难避免,一直想引用缓存,但是查询的条件太多,很动态,就不知道如何设计缓存,类似于京东筛选物品,多品类,多维度筛选,不知道大牛有何高见作者回复: 按照2-8原则,选出占访问量80%的前20%的请求条件缓存,因为大部分人的查询不会每次都非常多条件,以手机为例,查询苹果加华为的可能占很大一部分
2018-06-05685- 性能我们做网银系统,用redis存了一些不太重要的数据,比如数据字典信息,作为缓存。但是不太敢把用户权限,交易数据等重要信息存在缓存里,因为redis并不保证事务,我们担心一旦缓存服务器宕机或者失败会影响银行业务。所以缓存的作用也不是很大,还是把大部分读数据的压力放到了数据库上,您说我们这种担心有必要吗?如果单库后续扛不住压力,是否读写分离比加缓存更好一些?
作者回复: 交易型业务缓存应用不多,缓存一般总在查询类业务上,你们的担心有一定必要
2018-06-03348  彡工鸟是否还应该加上一个,当单机写顶不住压力后,就可以做数据库拆分了,例如业务纵向拆分,连同数据库一起,就变成分布式服务,微服务了:)
彡工鸟是否还应该加上一个,当单机写顶不住压力后,就可以做数据库拆分了,例如业务纵向拆分,连同数据库一起,就变成分布式服务,微服务了:)作者回复: 说法没错,但具体实施的时候要注意,不要一有压力就上读者分离,因为很多时候其实是sql语句或者业务逻辑有问题,因此先优化,只有优化后也无法满足要求的时候才考虑读者分离或者集群
2018-05-3023 小喵喵公司现在的系统时采用读写分离的,是中间层程序封装的api,第一套分两类:1读主库,2.读从库.然后客户端程序通过传递SQL或存储过程和参数的值调用。 第二套只提供一个api,通过传递一个布尔值来判断是走主库还是从库,这套是供自动调度工具来调用。这两套api都有一个共同点,就程序猿必须手动指定是走主库还是从库。现在出现的问题是大量的SQL应该走从库,结果很多菜鸟都走了主库,导致现在的主库压力很大。听了你的课程后觉得走主库还是从库不应该由程序猿自己指定,而是由中间层来判断。具体如何做呢,请老师指点一下。客户端有时传递一些复杂的SQL,比如,先做更新然后再查。
小喵喵公司现在的系统时采用读写分离的,是中间层程序封装的api,第一套分两类:1读主库,2.读从库.然后客户端程序通过传递SQL或存储过程和参数的值调用。 第二套只提供一个api,通过传递一个布尔值来判断是走主库还是从库,这套是供自动调度工具来调用。这两套api都有一个共同点,就程序猿必须手动指定是走主库还是从库。现在出现的问题是大量的SQL应该走从库,结果很多菜鸟都走了主库,导致现在的主库压力很大。听了你的课程后觉得走主库还是从库不应该由程序猿自己指定,而是由中间层来判断。具体如何做呢,请老师指点一下。客户端有时传递一些复杂的SQL,比如,先做更新然后再查。作者回复: 默认读走从库,写走主库,特殊情况才由程序员制定,可以代码指定,可以配置指定,这样就不会出现大量sql都走主库了
2018-06-03319 spoofer前段时间,老大在大表上执行了delete操作,然后主从就不同步了。然后线上各种bug,最后我花了5分钟排查到了问题(运维团队比较小,我打杂的)。解决方式,线上业务部分限流,关键业务读写紧急切换到主库,修复主从不同步问题,切换回读写分离配置。最后发现是老大做了骚操作,一问才知道,是个日志表,清理一下。😂我。。。
spoofer前段时间,老大在大表上执行了delete操作,然后主从就不同步了。然后线上各种bug,最后我花了5分钟排查到了问题(运维团队比较小,我打杂的)。解决方式,线上业务部分限流,关键业务读写紧急切换到主库,修复主从不同步问题,切换回读写分离配置。最后发现是老大做了骚操作,一问才知道,是个日志表,清理一下。😂我。。。作者回复: 我们要求线上delete每次不能超过1000条,超过就定时循环操作
2019-12-18414 allen.huang老师您好, 像我们数据库服务器只有一台,并且现在业务量也越来越大,尤其是中午,晚上加起来大概是5,6个小时是业务高峰,订餐的量还挺大。前台读写操作都很频繁, 后来就是要看数据统计啊之类的,客户也是经常在使用。在业务高峰期,他们还要进去看实时交易情况。这样子经常会出现磁盘IO报警。 我也在尝试规划做读写分离,但是像业务前台做了以后,就会出现数据延时的情况,这样子业务处理就有问题。 我现在初步规划是前台都用主,后台读写分离,这样子是否合理,有经验的同学也给予我指导谢谢😜
allen.huang老师您好, 像我们数据库服务器只有一台,并且现在业务量也越来越大,尤其是中午,晚上加起来大概是5,6个小时是业务高峰,订餐的量还挺大。前台读写操作都很频繁, 后来就是要看数据统计啊之类的,客户也是经常在使用。在业务高峰期,他们还要进去看实时交易情况。这样子经常会出现磁盘IO报警。 我也在尝试规划做读写分离,但是像业务前台做了以后,就会出现数据延时的情况,这样子业务处理就有问题。 我现在初步规划是前台都用主,后台读写分离,这样子是否合理,有经验的同学也给予我指导谢谢😜作者回复: 面向用户的业务读写都用主,面向客户和运营的业务可以读写分离,大部分场景没必要看实时交易情况的
2018-08-1414 刘岚乔月请问 对于主从出现的数据同步延时问题 在实际生产落地 真的只有把重要的查询指向主吗 还有其他真正的落地方案吗
刘岚乔月请问 对于主从出现的数据同步延时问题 在实际生产落地 真的只有把重要的查询指向主吗 还有其他真正的落地方案吗作者回复: 当然是真的呀,难道我还会骗你不成?😂 如果不想用这种方式,用缓存是可以规避这个问题的,但其实这时候的方案就不是读写分离了
2018-05-29213 rubin读写分离的前提是并发量大,单机已经不能处理该数量的并发请求了,想要解决问题就得做作拆分,于是有了读写分离,主库负责写,从库负责读,降低了同台机器并发请求,当读越来越多时,可扩充从库,写越来越多时,只好拆分业务或分库分表,如:注册功能,单独出来做一个注册的微服务,但还是会到达一个瓶颈,没做过,不知道能支持多少的并发?
rubin读写分离的前提是并发量大,单机已经不能处理该数量的并发请求了,想要解决问题就得做作拆分,于是有了读写分离,主库负责写,从库负责读,降低了同台机器并发请求,当读越来越多时,可扩充从库,写越来越多时,只好拆分业务或分库分表,如:注册功能,单独出来做一个注册的微服务,但还是会到达一个瓶颈,没做过,不知道能支持多少的并发?作者回复: 要具体测试,不同业务复杂度不同
2018-05-3012

