

39 | 自增主键为什么不是连续的?

该思维导图由 AI 生成,仅供参考
自增值保存在哪儿?
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

自增主键的连续性问题在数据库设计中是一个重要议题。本文深入探讨了自增主键的不连续性原因及相关技术细节。首先介绍了自增值的保存位置和不同引擎对自增值的保存策略,以及自增值的修改机制和生成算法。文章指出了唯一键冲突和事务回滚是导致自增主键不连续的两种原因,并给出了相应的操作序列进行验证。此外,分析了MySQL设计中不允许自增值回退的原因,主要是为了提升性能。最后,总结了InnoDB放弃自增值回退设计的原因,强调了自增主键保证递增但不保证连续的特点。另外,文章还介绍了MySQL 5.1.22版本引入的参数innodb_autoinc_lock_mode,控制了自增值申请时的锁范围,并提出了对于批量插入数据的语句,建议将其设置为2,同时将binlog_format设置为row,以提升并发性能并避免数据一致性问题。整体而言,本文深入浅出地解释了自增主键不连续的原因和相关技术细节,对于理解自增主键的工作机制和特性具有很高的参考价值。
《MySQL 实战 45 讲》,新⼈⾸单¥68

全部留言(60)
- 最新
- 精选
 长杰在最后一个例子中,执行 insert into t2(c,d) select c,d from t; 这个语句的时候,如果隔离级别是可重复读(repeatable read),binlog_format=statement。这个语句会对表 t 的所有记录和间隙加锁。 你觉得为什么需要这么做呢? 假如原库不对t表所有记录和间隙加锁,如果有其他事物新增数据并先与这个批量操作提交,由于事物的隔离级别是可重复读,t2是看不到新增的数据的。但是记录的binlog是statement格式,备库或基于binlog恢复的临时库,t2会看到新增的数据,出现数据不一致的情况。
长杰在最后一个例子中,执行 insert into t2(c,d) select c,d from t; 这个语句的时候,如果隔离级别是可重复读(repeatable read),binlog_format=statement。这个语句会对表 t 的所有记录和间隙加锁。 你觉得为什么需要这么做呢? 假如原库不对t表所有记录和间隙加锁,如果有其他事物新增数据并先与这个批量操作提交,由于事物的隔离级别是可重复读,t2是看不到新增的数据的。但是记录的binlog是statement格式,备库或基于binlog恢复的临时库,t2会看到新增的数据,出现数据不一致的情况。作者回复: 👍 这是一个典型的场景
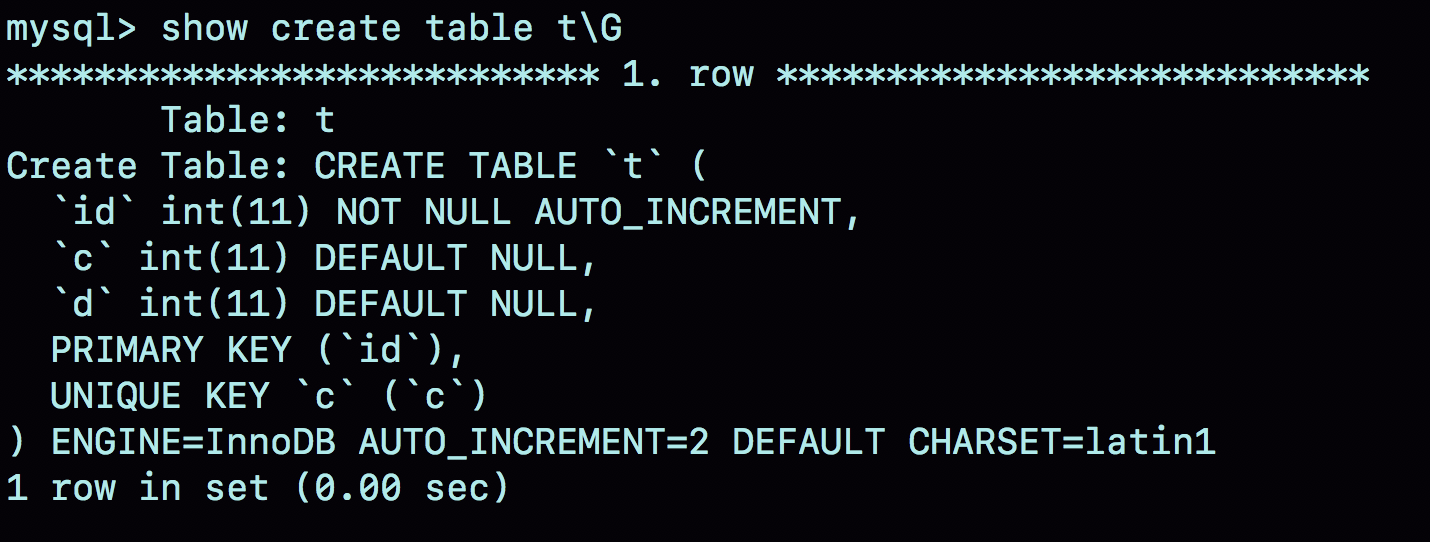
2019-02-114121 钱最喜欢这样的文章,以为比较简单和熟悉,也能打开一扇窗,让人看到一个不同的世界,并且无比丰富多彩。 在什么场景下自增主键可能不连续? 1:唯一键冲突 2:事务回滚 3:自增主键的批量申请 深层次原因是,不判断自增主键是否已存在和减少加锁的时间范围和粒度->为了更高的性能->自增主键不能回退->自增主键不连续 自增主键是怎么做的唯一性的? 自增值加1,自增锁控制并发 自增主键的生成性能如何? 这个需要测试一下,数据库的自增主键也用做生成唯一数字,作为其他单号,比如:并发量小的订单号,性能可能一般。 自增主键有最大值嘛?如果有,到了咋弄? 最大值应该有,因为数字总有个范围,到了当做字符串的一部分,然后再自增拼接上另一部分,貌似也可以。 自增主键的作用?保存机制?修改机制? 作用:让主键索引尽量地保持递增顺序插入,避免页分裂,使索引更紧凑。 保存机制:不同的存储引擎不一样。 MyISAM 引擎的自增值保存在数据文件中。 InnoDB 引擎的自增值,先是保存在了内存里,到了 MySQL 8.0 版本后,才有了“自增值持久化”的能力,放在了redolog里。 修改机制: 在 MySQL 里面,如果字段 id 被定义为 AUTO_INCREMENT,在插入一行数据的时候,自增值的行为如下: 1:如果插入数据时 id 字段指定为 0、null 或未指定值,那么就把这个表当前的 AUTO_INCREMENT 值填到自增字段; 2:如果插入数据时 id 字段指定了具体的值,就直接使用语句里指定的值。 根据要插入的值和当前自增值的大小关系,自增值的变更结果也会有所不同。假设,某次要插入的值是 X,当前的自增值是 Y。 1:如果 X<Y,那么这个表的自增值不变; 2:如果 X≥Y,就需要把当前自增值修改为新的自增值。
钱最喜欢这样的文章,以为比较简单和熟悉,也能打开一扇窗,让人看到一个不同的世界,并且无比丰富多彩。 在什么场景下自增主键可能不连续? 1:唯一键冲突 2:事务回滚 3:自增主键的批量申请 深层次原因是,不判断自增主键是否已存在和减少加锁的时间范围和粒度->为了更高的性能->自增主键不能回退->自增主键不连续 自增主键是怎么做的唯一性的? 自增值加1,自增锁控制并发 自增主键的生成性能如何? 这个需要测试一下,数据库的自增主键也用做生成唯一数字,作为其他单号,比如:并发量小的订单号,性能可能一般。 自增主键有最大值嘛?如果有,到了咋弄? 最大值应该有,因为数字总有个范围,到了当做字符串的一部分,然后再自增拼接上另一部分,貌似也可以。 自增主键的作用?保存机制?修改机制? 作用:让主键索引尽量地保持递增顺序插入,避免页分裂,使索引更紧凑。 保存机制:不同的存储引擎不一样。 MyISAM 引擎的自增值保存在数据文件中。 InnoDB 引擎的自增值,先是保存在了内存里,到了 MySQL 8.0 版本后,才有了“自增值持久化”的能力,放在了redolog里。 修改机制: 在 MySQL 里面,如果字段 id 被定义为 AUTO_INCREMENT,在插入一行数据的时候,自增值的行为如下: 1:如果插入数据时 id 字段指定为 0、null 或未指定值,那么就把这个表当前的 AUTO_INCREMENT 值填到自增字段; 2:如果插入数据时 id 字段指定了具体的值,就直接使用语句里指定的值。 根据要插入的值和当前自增值的大小关系,自增值的变更结果也会有所不同。假设,某次要插入的值是 X,当前的自增值是 Y。 1:如果 X<Y,那么这个表的自增值不变; 2:如果 X≥Y,就需要把当前自增值修改为新的自增值。作者回复: 👍
2019-08-0762 Nomius不知道老师还关不关注. (1)问一下为什么一张表上面只能有一个自增的字段? (这个大概能从文章中分析出来,因为autoincrement是定义在表结构中,如果有多个的话实现自增的时候逻辑太复杂了) (2)为什么自增的字段上面必须要有索引?
Nomius不知道老师还关不关注. (1)问一下为什么一张表上面只能有一个自增的字段? (这个大概能从文章中分析出来,因为autoincrement是定义在表结构中,如果有多个的话实现自增的时候逻辑太复杂了) (2)为什么自增的字段上面必须要有索引?作者回复: 1. 是的 2. 我觉得最初的一个原因是,由于以前(8.0版本前)自增主键值是不持久化的,只放在内存里面。每次重启后,重新打开表时,需要计算“自增字段里面的最大值”,然后加1,作为当前的autoincrement的值。 如果没有索引,算这个值就要做全表扫描,性能可能很差,影响访问表的速度。 好问题。不过这个只是我个人猜测,也可能还有别的原因。😆
2019-06-05254 帽子掉了老师您好,我有一个时序问题,想请教一下。 从这篇文章的介绍来看,获取自增id和写binlog是有先后顺序的。 那么在binlog为statement的情况下。 语句A先获取id=1,然后B获取id=2,接着B提交,写binlog,再A写binlog。 这个时候如果binlog重放,是不是会发生B的id为1,而A的id为2的不一致的情况?
帽子掉了老师您好,我有一个时序问题,想请教一下。 从这篇文章的介绍来看,获取自增id和写binlog是有先后顺序的。 那么在binlog为statement的情况下。 语句A先获取id=1,然后B获取id=2,接着B提交,写binlog,再A写binlog。 这个时候如果binlog重放,是不是会发生B的id为1,而A的id为2的不一致的情况?作者回复: 好问题,不会 因为binlog在记录这种带自增值的语句之前,会在前面多一句,用于指定“接下来这个语句要需要的 自增ID值是多少”,而这个值,是在主库上这一行插入成功后对应的自增值,所以是一致的
2019-02-13848
 Ryoma在8.0.3版本后,innodb_autoinc_lock_mode默认值已是2,在binlog_format默认值为row的前提下,想来也是为了增加并发。 https://dev.mysql.com/doc/refman/8.0/en/innodb-parameters.html#sysvar_innodb_autoinc_lock_mode
Ryoma在8.0.3版本后,innodb_autoinc_lock_mode默认值已是2,在binlog_format默认值为row的前提下,想来也是为了增加并发。 https://dev.mysql.com/doc/refman/8.0/en/innodb-parameters.html#sysvar_innodb_autoinc_lock_mode作者回复: 👍 大势所趋😆
2019-02-1422 aliang老师,我们这边有的开发不喜欢用mysql自带的主键自增功能,而是在程序中控制主键(时间+业务+机器+序列,bigint类型,实际长度有17位,其中序列保存在内存中,每次递增,主键值不连续)。理由是 (1)通过这样的主键可以直接定位数据,减少索引(2)如果自增,必须先存数据得到主键才可继续下面的程序,如果自己计算主键,可以在入库前进行异步处理 (3)a表要insert得到主键,然后处理b表,然后根据条件还要update a表。如果程序自己控制,就不用先insert a表,数据可以在内存中,直到最后一次提交。(对于a表,本来是insert+update,最后只是一条insert,少一次数据库操作) 我想请问的是: (1)针对理由1,是否可以用组合索引替代? (2)针对理由2,是否mysql自身的主键自增分配逻辑就已经能实现了? (3)针对理由3,主键更长意味着更大的索引(主键索引和普通索引),你觉得怎样做会更好呢
aliang老师,我们这边有的开发不喜欢用mysql自带的主键自增功能,而是在程序中控制主键(时间+业务+机器+序列,bigint类型,实际长度有17位,其中序列保存在内存中,每次递增,主键值不连续)。理由是 (1)通过这样的主键可以直接定位数据,减少索引(2)如果自增,必须先存数据得到主键才可继续下面的程序,如果自己计算主键,可以在入库前进行异步处理 (3)a表要insert得到主键,然后处理b表,然后根据条件还要update a表。如果程序自己控制,就不用先insert a表,数据可以在内存中,直到最后一次提交。(对于a表,本来是insert+update,最后只是一条insert,少一次数据库操作) 我想请问的是: (1)针对理由1,是否可以用组合索引替代? (2)针对理由2,是否mysql自身的主键自增分配逻辑就已经能实现了? (3)针对理由3,主键更长意味着更大的索引(主键索引和普通索引),你觉得怎样做会更好呢作者回复: “(时间+业务+机器+序列,bigint类型,实际长度有17位,其中序列保存在内存中,每次递增,主键值不连续)。” ----bigint就是8位,这个你需要确定一下。如果是8位的还好,如果是17位的字符串,就比较耗费空间; (1)如果“序列”是递增的,还是不能直接用来体现业务逻辑吧? 创建有业务意义的字段索引估计还是省不了的 ? (2)mysql确实做不到“插入之前就先算好接下来的id是多少”,一般都是insert执行完成后,再执行select last_insert_id (3) 先insert a再update b再update a,确实看上去比较奇怪,不过感觉这个逻辑应该是可以优化的,不应该作为“主键选择”的一个依据。你可否脱敏一下,把模拟的表结构和业务逻辑说下,看看是不是可以优化的。 总之,按照你说的“时间+业务+机器+序列”这种模式,有点像用uuid,主要的问题还是,如果这个表的索引多,占用的空间比较大
2019-02-12420 Aaron_涛老师,能如果两个事务同时并发插入,主键没有指明的话,加锁的情况能说明下吗
Aaron_涛老师,能如果两个事务同时并发插入,主键没有指明的话,加锁的情况能说明下吗作者回复: 是说自增主键没指定? 两个语句分别去申请自增主键,申请到的值是不一样的,所以并不冲突
2019-04-216 hetiu老师,请问下innodb_autoinc_lock_mode配置是库级别的还是实例级别的?
hetiu老师,请问下innodb_autoinc_lock_mode配置是库级别的还是实例级别的?作者回复: 全局的
2019-03-055 牛在天上飞老师,请问产生大量的event事件会对mysql服务器有什么影响?主要是哪几个方面的影响?
牛在天上飞老师,请问产生大量的event事件会对mysql服务器有什么影响?主要是哪几个方面的影响?作者回复: 也没啥,主要就是不好管理。。 毕竟event是写在MySQL里的,写程序的同学不一定会记得。 比较建议将这类逻辑写在应用程序里面
2019-02-124- 唐名之老师,如果我业务场景必须需要一个带有序自增值,设业务为表A,另外添加一张表记录自增为表B,表B包含3个字段(自增主键,表A唯一键,自增列);伪代码如下;这样能实现吗?或者有其他什么好的方案? begin; insert into A values(字段1, 唯一键); insert into B value (表A唯一键,自增列); commit;
作者回复: 这样思路上是ok的, 不过表b怎么有两个自增列?一个表只能有一个自增列。
2019-02-252

