

28 | 读写分离有哪些坑?

该思维导图由 AI 生成,仅供参考
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

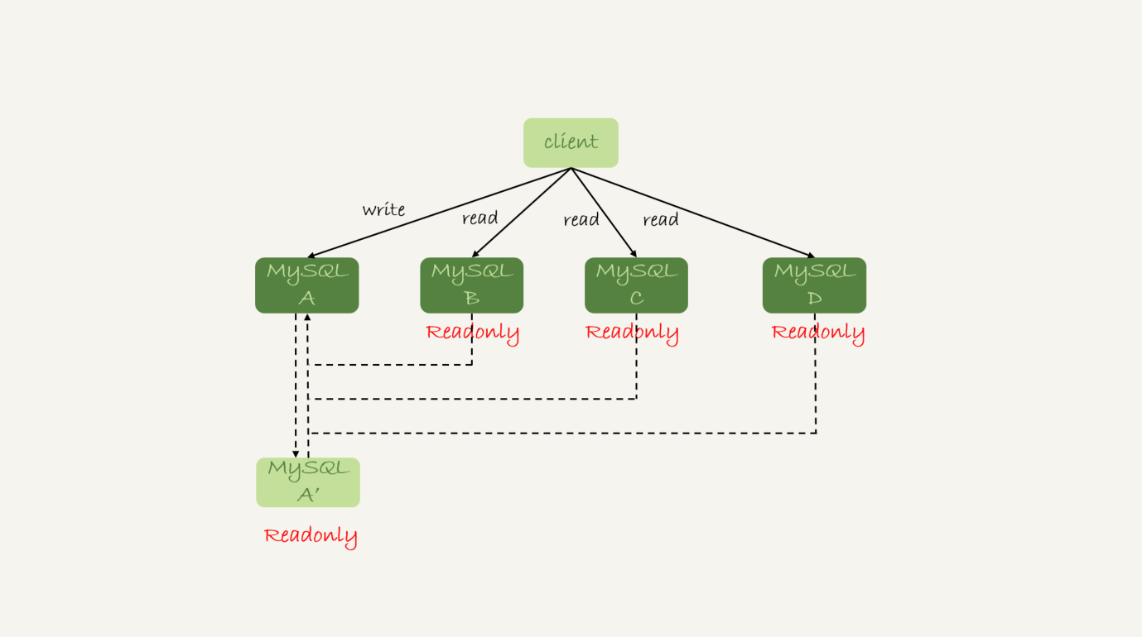
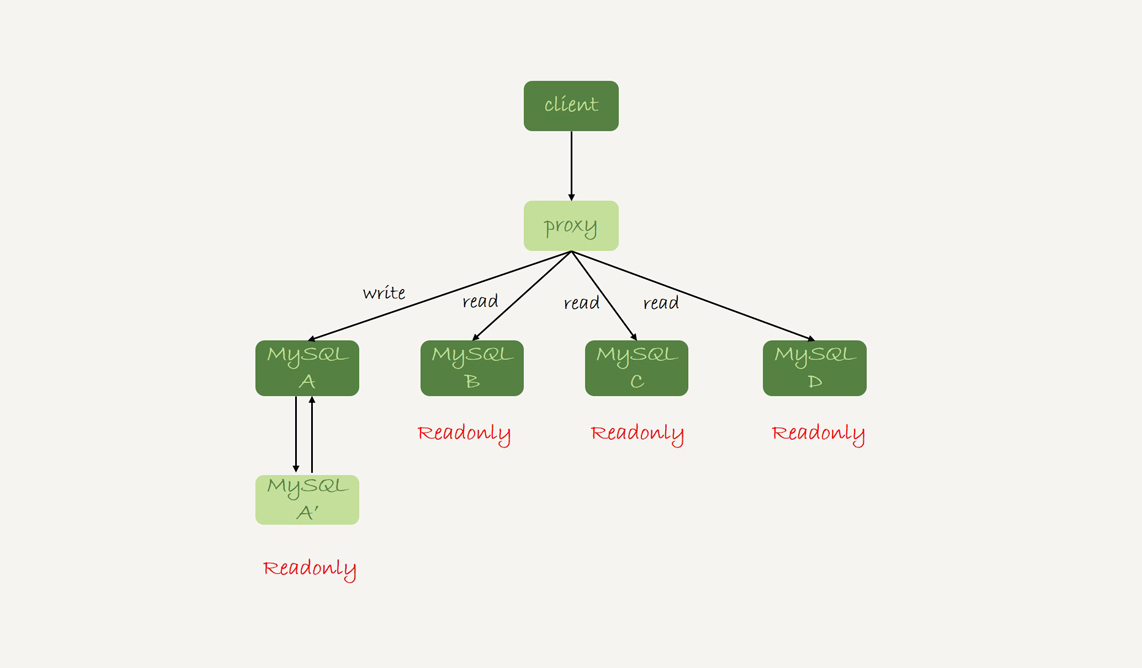
本文深入探讨了数据库架构中的读写分离问题及解决方案。首先介绍了两种读写分离架构:客户端直连和带proxy的架构,并分析了它们的特点和优劣。随后讨论了由于主从延迟导致的“过期读”问题,并提出了多种处理过期读的方案,包括强制走主库、sleep方案等。文章提出了更准确的方案,如判断主备无延迟方案、配合semi-sync方案等。在确保主备无延迟的方法中,通过对比位点和GTID的方法更准确。文章还介绍了semi-sync replication和等主库位点方案,以解决过期读问题。总的来说,本文提出的解决方案在不同场景下都有其适用性和局限性,需要根据具体业务需求和技术特点进行选择和权衡。文章还提到了在实际应用中可以混合使用这些方案,并留下了一个问题供读者思考。
《MySQL 实战 45 讲》,新⼈⾸单¥68

全部留言(84)
- 最新
- 精选
- 有铭这专栏真的是干货满满,每看一篇我都有“我发现我真的不会使用MySQL”和“我原来把MySQL用错了”的挫败感
作者回复: 这样我觉得你和我的时间都值了😆 把你更新了认识的点发到评论区,这样会印象更深哈🤝
2019-01-168131  曾剑老师写的每一篇文章都能让我获益良多。每一篇都值得看好几遍。 今天的问题,大表做DDL的时候可能会出现主从延迟,导致等 GTID 的方案可能会导致这部分流量全打到主库,或者全部超时。 如果这部分流量太大的话,我会选择上一篇文章介绍的两种方法: 1.在各个从库先SET sql_log_bin = OFF,然后做DDL,所有从库及备主全做完之后,做主从切换,最后在原来的主库用同样的方式做DDL。 2.从库上执行DDL;将从库上执行DDL产生的GTID在主库上利用生成一个空事务GTID的方式将这个GTID在主库上生成出来。 各个从库做完之后再主从切换,然后再在原来的主库上同样做一次。 需要注意的是如果有MM架构的情况下,承担写职责的主库上的slave需要先停掉。
曾剑老师写的每一篇文章都能让我获益良多。每一篇都值得看好几遍。 今天的问题,大表做DDL的时候可能会出现主从延迟,导致等 GTID 的方案可能会导致这部分流量全打到主库,或者全部超时。 如果这部分流量太大的话,我会选择上一篇文章介绍的两种方法: 1.在各个从库先SET sql_log_bin = OFF,然后做DDL,所有从库及备主全做完之后,做主从切换,最后在原来的主库用同样的方式做DDL。 2.从库上执行DDL;将从库上执行DDL产生的GTID在主库上利用生成一个空事务GTID的方式将这个GTID在主库上生成出来。 各个从库做完之后再主从切换,然后再在原来的主库上同样做一次。 需要注意的是如果有MM架构的情况下,承担写职责的主库上的slave需要先停掉。作者回复: 👍 表示这两篇文章你都get到了
2019-01-16994 某、人老师我先请教两个问题(估计大多数同学都有这个疑惑)😄: 1.现在的中间件可以说是乱花渐欲迷人眼,请问老师哪一款中间件适合大多数不分库分表,只是做读写分离业务的proxy,能推荐一款嘛?毕竟大多数公司都没有专门做中间件开发的团队 2.如果是业务上进行了分库分表,老师能推荐一款分库分表的proxy嘛?我目前了解到的针对分库分表的proxy都或多或少有些问题。不过分布式数据库是一个趋势也是一个难点。
某、人老师我先请教两个问题(估计大多数同学都有这个疑惑)😄: 1.现在的中间件可以说是乱花渐欲迷人眼,请问老师哪一款中间件适合大多数不分库分表,只是做读写分离业务的proxy,能推荐一款嘛?毕竟大多数公司都没有专门做中间件开发的团队 2.如果是业务上进行了分库分表,老师能推荐一款分库分表的proxy嘛?我目前了解到的针对分库分表的proxy都或多或少有些问题。不过分布式数据库是一个趋势也是一个难点。作者回复: 额,这个最难回答了 说实话因为我原来团队是团队自己做的proxy(没有开源),所以我对其他proxy用得并不多,实在不敢随便指一个。 如果我说个比较熟悉的话,可能MariaDB MaxScale还不错
2019-01-16540 Mr.Strive.Z.H.L老师您好: 关于主库大表的DDL操作,我看了问题答案,有两种方案。第一种是读写请求转到主库,在主库上做DDL。第二种是从库上做DDL,完成后进行主从切换。 关于第二种,有一个疑惑: 从库上做DDL,读写请求走主库,等到从库完成后,从库必须要同步DDL期间,主库完成的事务后才能进行主从切换。而如果DDL操作是删除一列,那么在同步过程中会出错呀?(比如抛出这一列不存在的错误)。
Mr.Strive.Z.H.L老师您好: 关于主库大表的DDL操作,我看了问题答案,有两种方案。第一种是读写请求转到主库,在主库上做DDL。第二种是从库上做DDL,完成后进行主从切换。 关于第二种,有一个疑惑: 从库上做DDL,读写请求走主库,等到从库完成后,从库必须要同步DDL期间,主库完成的事务后才能进行主从切换。而如果DDL操作是删除一列,那么在同步过程中会出错呀?(比如抛出这一列不存在的错误)。作者回复: 你说得对,这种方案下能支持的DDL只有以下几种: 创建/删除索引、新增最后一列、删除最后一列 其中DBA会认为“合理”的DDL需求就是: “创建/删除索引、新增最后一列” 新春快乐~
2019-01-21928 钱1:单机的性能总是有限的,所以,就出现了读写分离 2:读写分离带来了更高的性能,也引入了数据不一致的问题 3:为了数据一致性,又产生了各种解决方案 人少力量小,人多了事就多,如果管理能力好,还是人多好办事。 原理是这样,没怎么实操过,感谢老师的分享,让自己的认知边界有移动了一点点。
钱1:单机的性能总是有限的,所以,就出现了读写分离 2:读写分离带来了更高的性能,也引入了数据不一致的问题 3:为了数据一致性,又产生了各种解决方案 人少力量小,人多了事就多,如果管理能力好,还是人多好办事。 原理是这样,没怎么实操过,感谢老师的分享,让自己的认知边界有移动了一点点。作者回复: 👍
2019-08-04222 Max我一般是先是在从库上设置 set_log_bin=off,然后执行ddl,语句。 然后完成以后,主从做一下切换。然后在主库上在执行一下set_log_bin=off,执行ddl语句。 然后在做一下主从切换。 个人对pt-online-scheman-change不是很推荐使用,它的原理基本是创建触发器,然后创建和旧表一样结构的数据表, 把旧表的数据复制过去。最后删除旧表。以前做个一个测试,如果旧表一直在被select,删除过程会一直会等待。 所以个人不是很建议。万一不小心变成从删库到路步,那就得不偿失了。 老师,有个问题想请教一下,一主多从可以多到什么地步,以前我们CTO解决的方案就是加机器,一主十三从。 当时我是反对的,其实个人建议还是从SQL,业务上面去优化。而不是一味的加机器。如果加机器解决的话,还要DBA做什么呢?
Max我一般是先是在从库上设置 set_log_bin=off,然后执行ddl,语句。 然后完成以后,主从做一下切换。然后在主库上在执行一下set_log_bin=off,执行ddl语句。 然后在做一下主从切换。 个人对pt-online-scheman-change不是很推荐使用,它的原理基本是创建触发器,然后创建和旧表一样结构的数据表, 把旧表的数据复制过去。最后删除旧表。以前做个一个测试,如果旧表一直在被select,删除过程会一直会等待。 所以个人不是很建议。万一不小心变成从删库到路步,那就得不偿失了。 老师,有个问题想请教一下,一主多从可以多到什么地步,以前我们CTO解决的方案就是加机器,一主十三从。 当时我是反对的,其实个人建议还是从SQL,业务上面去优化。而不是一味的加机器。如果加机器解决的话,还要DBA做什么呢?作者回复: 前面的分析很好哈 然后一主13从有点多了,否则主库生成binlog太快的话,主库的网卡会被打爆。要这么多的话,得做级联。 DBA解决不能靠加机器解决的事情^_^ 而且如果通过优化,可以把13变成3,那也是DBA的价值
2019-01-17214- 二马最近做性能测试时发现当并发用户达到一定量(比如500),部分用户连接不上,能否介绍下MySQL连接相关问题,谢谢!
作者回复: 修改max_connections参数
2019-01-1612  万勇老师,请教下。 1.对大表做ddl,是可以采用先在备库上set global log_bin=off,先做完ddl,然后切换主备库。为了保证数据一致性,在切主备的时候,数据库会有个不可用的时间段,对业务会造成影响。现在的架构方式,中间层还有proxy,意味着proxy也需要修改主备配置,做reload。这样做的话,感觉成本太高,在真正的生产环境中,这种方法适用吗? 2.目前我们常采用的是对几百万以上的表用pt-online-schema-change,这种方式会产生大量的binlog,业务高峰期不能做,会引起主备延迟。在生产业务中,我觉得等主库节点或者等gtid这种方案挺不错,至少能保证业务,但也会增加主库的压力。 3.5.7版本出的group_replication多写模式性能不知道如何?架构变动太大,还不敢上。
万勇老师,请教下。 1.对大表做ddl,是可以采用先在备库上set global log_bin=off,先做完ddl,然后切换主备库。为了保证数据一致性,在切主备的时候,数据库会有个不可用的时间段,对业务会造成影响。现在的架构方式,中间层还有proxy,意味着proxy也需要修改主备配置,做reload。这样做的话,感觉成本太高,在真正的生产环境中,这种方法适用吗? 2.目前我们常采用的是对几百万以上的表用pt-online-schema-change,这种方式会产生大量的binlog,业务高峰期不能做,会引起主备延迟。在生产业务中,我觉得等主库节点或者等gtid这种方案挺不错,至少能保证业务,但也会增加主库的压力。 3.5.7版本出的group_replication多写模式性能不知道如何?架构变动太大,还不敢上。作者回复: 1. 是这样的,我们说的是,如果非紧急情况下,还是尽量用gh-ost,在“紧急”的情况下,才这么做;确实是要绕过proxy的,也就是说,这事儿是要负责运维的同学做; 2. pt工具是有这个问题,试一下gh-ost哈;group_replication多写模式国内我还没有听到国内有公司在生产上大规模用的,如果你有使用经验,分享一下哈
2019-01-1639- 啊啊啊哦哦老师。最近公司在阿里云要用 一主多从。 我想问下阿里的。 select *from test for update 会定位到主库吗
作者回复: 设计不出bug的话,应该要😆
2019-04-1036  Dovelol老师好,有几个问题想请教下, 1.如果不想有过期读,用等GTID的方案,那么每次查询都要有等GTID的相关操作,增加的这部分对性能有多少影响; 2.我们用的读写分离proxy不支持等GTID,那是不是自己要在客户端实现这部分逻辑,等于读写分离的架构既用了proxy,又在客户端做了相关策略,感觉这方案更适合有能力自研proxy的公司啊; 3.感觉目前大多数生产环境还是用的读主库这种方式避免过期读,如果只能用这种方案的话该怎么扩展mysql架构来避免主库压力太大呢。 我们是项目上线很久然后加的读写分离,好多service层代码写的不好,可以读从库的sql被写到了事务中,这样会被proxy转到主库上读,所以导致主库负担了好多读的sql,感觉读写分离不仅对mysql这块要掌握,整体的代码结构上也要有所调整吧。
Dovelol老师好,有几个问题想请教下, 1.如果不想有过期读,用等GTID的方案,那么每次查询都要有等GTID的相关操作,增加的这部分对性能有多少影响; 2.我们用的读写分离proxy不支持等GTID,那是不是自己要在客户端实现这部分逻辑,等于读写分离的架构既用了proxy,又在客户端做了相关策略,感觉这方案更适合有能力自研proxy的公司啊; 3.感觉目前大多数生产环境还是用的读主库这种方式避免过期读,如果只能用这种方案的话该怎么扩展mysql架构来避免主库压力太大呢。 我们是项目上线很久然后加的读写分离,好多service层代码写的不好,可以读从库的sql被写到了事务中,这样会被proxy转到主库上读,所以导致主库负担了好多读的sql,感觉读写分离不仅对mysql这块要掌握,整体的代码结构上也要有所调整吧。作者回复: 1. 这个等待时间其实就基本上是主备延迟的时间 2. 用了proxy这事情就得proxy做了,就不要客户端做了。没有gtid,可以用倒数第二种方法呀:) 3. 是的,其实“走主库”这种做法还挺多的。我之前看到有的公司的做法,就是直接拆库了。等于一套“一主多从”拆成多套。
2019-01-166

