

27 | 主库出问题了,从库怎么办?

该思维导图由 AI 生成,仅供参考
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

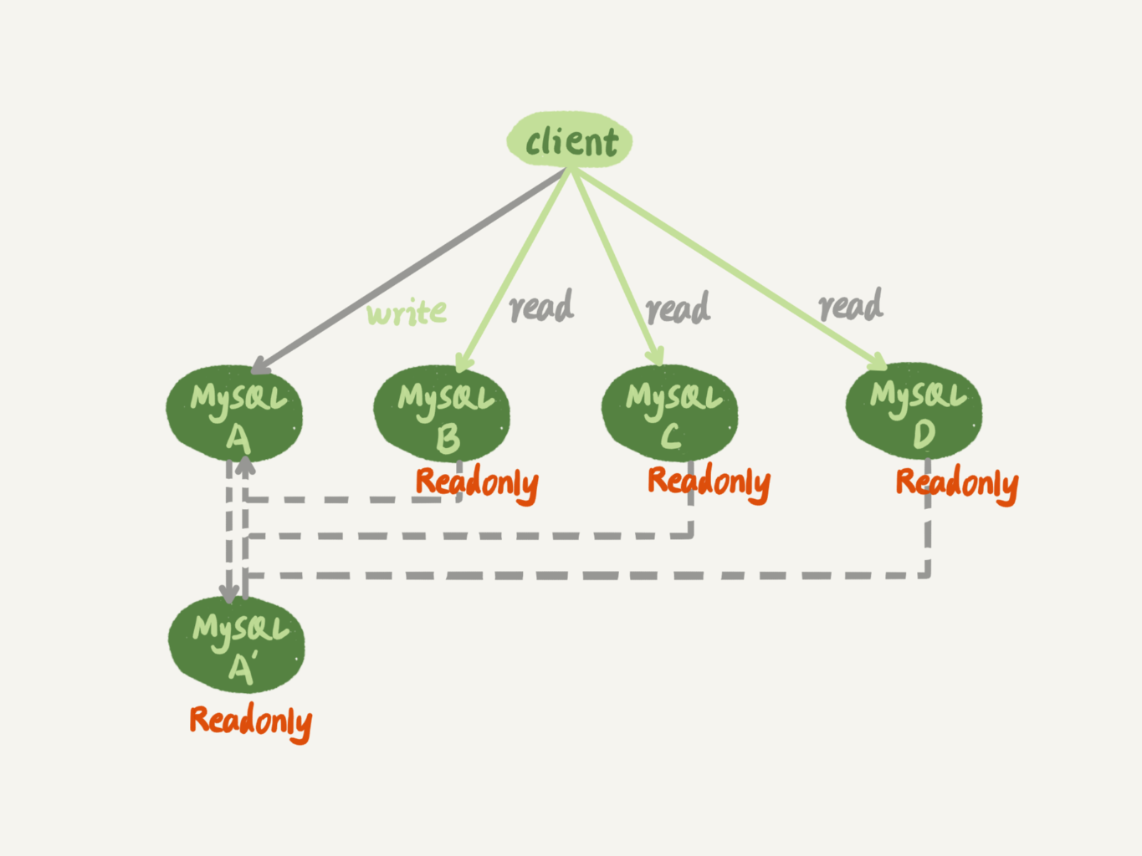
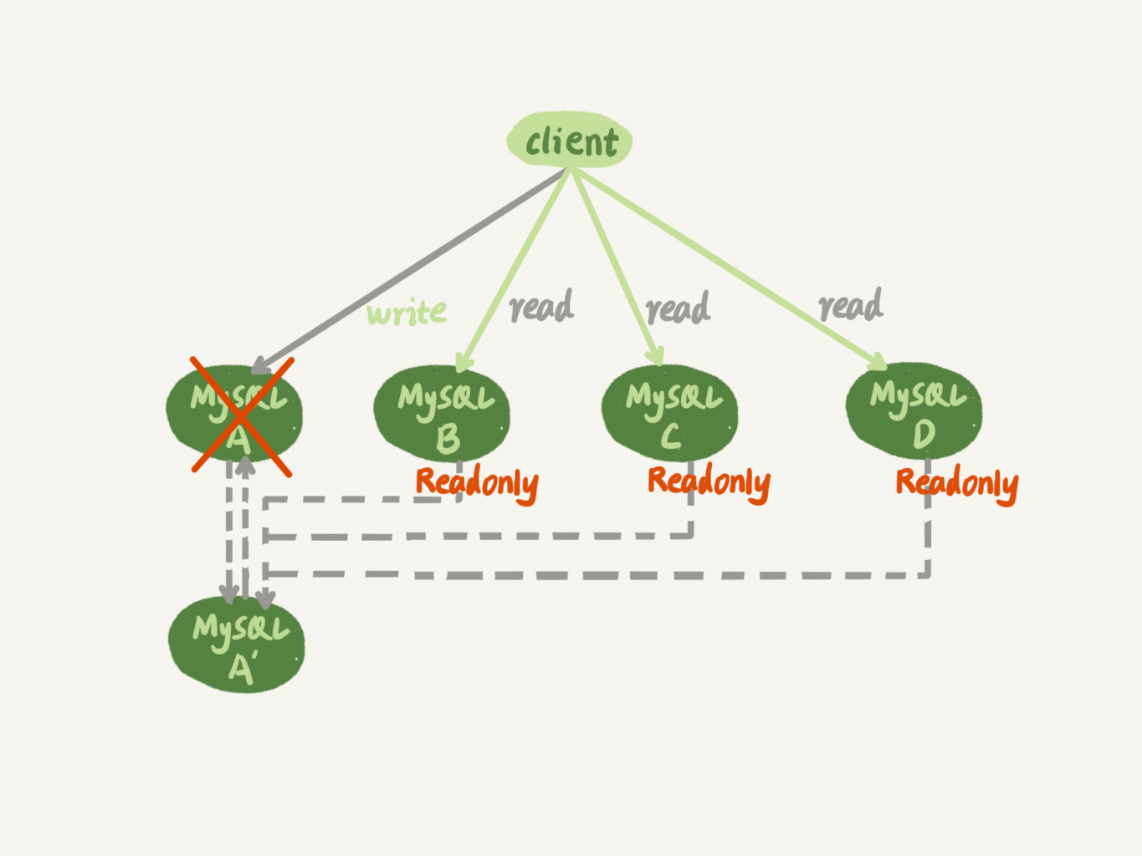
在一主多从架构下,主库出现故障后,从库如何处理是一个关键问题。本文深入探讨了基于位点和GTID的主备切换方法,并详细介绍了在切换过程中可能出现的数据同步问题及解决方案。GTID(全局事务ID)作为解决主备切换困难的利器被详细介绍,其生成方式和启动模式都得到了清晰的阐述。文章还通过具体的例子展示了GTID的基本用法,以及基于GTID的主备切换的实现逻辑。通过GTID模式,主备切换不再需要手动找位点,而是在实例内部自动完成,极大地简化了操作流程。对于数据库管理员和系统架构师来说,本文提供了宝贵的参考价值,帮助他们更好地理解和应用主备切换的复杂性及解决方案。 在GTID模式下,一主多从切换变得非常方便,极大地简化了操作流程。如果使用的MySQL版本支持GTID,建议尽量使用GTID模式来进行一主多从的切换。文章还提到了GTID模式在读写分离场景的应用,为读者提供了更多的技术应用思路。 此外,文章还涉及了在主库单线程压力模式下,从库追主库的过程中应该选用什么参数的问题,并给出了详细的解答。这些内容对于技术人员来说具有一定的参考价值。 总的来说,本文通过深入探讨GTID模式在主备切换中的应用,为读者提供了宝贵的技术知识,帮助他们更好地理解和应用主备切换的复杂性及解决方案。
《MySQL 实战 45 讲》,新⼈⾸单¥68

全部留言(74)
- 最新
- 精选
 Mr.Strive.Z.H.L置顶老师您好: 在实际工作中,主从备份似乎是mysql用的最多的高可用方案。 但是个人认为主从备份这个方案的问题实在太多了: 1. binlog数据传输前,主库宕机,导致提交了的事务数据丢失。 2. 一主多从,即使采用半同步,也只能保证binlog至少在两台机器上,没有一个机制能够选出拥有最完整binlog的从库作为新的主库。 3. 主从切换涉及到 人为操作,而不是全自动化的。即使在使用GTID的情况下,也会有binlog被删除,需要重新做从库的情况。 4. 互为主备,如果互为主备的两个实例全部宕机,mysql直接不可用。 mysql应该有更强大更完备的高可用方案(类似于zab协议或者raft协议这种),而在实际环境下,为什么主从备份用得最多呢?
Mr.Strive.Z.H.L置顶老师您好: 在实际工作中,主从备份似乎是mysql用的最多的高可用方案。 但是个人认为主从备份这个方案的问题实在太多了: 1. binlog数据传输前,主库宕机,导致提交了的事务数据丢失。 2. 一主多从,即使采用半同步,也只能保证binlog至少在两台机器上,没有一个机制能够选出拥有最完整binlog的从库作为新的主库。 3. 主从切换涉及到 人为操作,而不是全自动化的。即使在使用GTID的情况下,也会有binlog被删除,需要重新做从库的情况。 4. 互为主备,如果互为主备的两个实例全部宕机,mysql直接不可用。 mysql应该有更强大更完备的高可用方案(类似于zab协议或者raft协议这种),而在实际环境下,为什么主从备份用得最多呢?作者回复: 3 这个应该是可以做到自动化的。 4 这个概率比较小,其实即使是别的三节点的方案,也架不住挂两个实例,所以这个不是MySQL主备的锅。 前面两点提得很对哈。 其实MySQL到现在,还是提供了很多方案可选的。很多是业务权衡的结果。 比如说,异步复制,在主库异常掉电的时候可能会丢数据。 这个大家知道以后,有一些就改成semi-sync了,但是还是有一些就留着异步复制的模式,因为semi-sync有性能影响(一开始35%,现在好点15%左右,看具体环境),而可能这些业务认为丢一两行,可以从应用层日志去补。 就保留了异步复制模式。 最后,为什么主从备份用得最多,我觉得有历史原因。多年前MySQL刚要开始火的时候,大家发现这个主备模式好方便,就都用了。 而基于其他协议的方案,都是后来出现的,并且还是陆陆续续出点bug。 涉及到线上服务,大家使用新方案的热情总是局限在测试环境的多。 semi-sync也是近几年才开始稳定并被一些公司开始作为默认配置。 新技术的推广,在数据库上,确实比其他领域更需要谨慎些,也算是业务决定的吧^_^ 好问题👍 以上仅一家之言哈😆
2019-01-18866 某、人置顶1.如果业务允许主从不一致的情况那么可以在主上先show global variables like 'gtid_purged';然后在从上执行set global gtid_purged =' '.指定从库从哪个gtid开始同步,binlog缺失那一部分,数据在从库上会丢失,就会造成主从不一致 2.需要主从数据一致的话,最好还是通过重新搭建从库来做。 3.如果有其它的从库保留有全量的binlog的话,可以把从库指定为保留了全量binlog的从库为主库(级联复制) 4.如果binlog有备份的情况,可以先在从库上应用缺失的binlog,然后在start slave
某、人置顶1.如果业务允许主从不一致的情况那么可以在主上先show global variables like 'gtid_purged';然后在从上执行set global gtid_purged =' '.指定从库从哪个gtid开始同步,binlog缺失那一部分,数据在从库上会丢失,就会造成主从不一致 2.需要主从数据一致的话,最好还是通过重新搭建从库来做。 3.如果有其它的从库保留有全量的binlog的话,可以把从库指定为保留了全量binlog的从库为主库(级联复制) 4.如果binlog有备份的情况,可以先在从库上应用缺失的binlog,然后在start slave作者回复: 非常好👍
2019-01-157104 七七置顶看过上篇后想到一个问题: 级联复制A->B->C结构下, 从库C的Seconds_Behind_Master的时间计算问题. 假定当前主库A仅有一个DDL要进行变更,耗时1分钟.那么从库C的SBM值最大应该是多少时间? 是1分钟, 2分钟, 还是3分钟呢 ? 带着疑问看了一下测试从库C的binlog文件中的时间戳,得出结论应该是3分钟. 打破之前认知 🤦♀️ . 请老师解惑 , 谢谢 !
七七置顶看过上篇后想到一个问题: 级联复制A->B->C结构下, 从库C的Seconds_Behind_Master的时间计算问题. 假定当前主库A仅有一个DDL要进行变更,耗时1分钟.那么从库C的SBM值最大应该是多少时间? 是1分钟, 2分钟, 还是3分钟呢 ? 带着疑问看了一下测试从库C的binlog文件中的时间戳,得出结论应该是3分钟. 打破之前认知 🤦♀️ . 请老师解惑 , 谢谢 !作者回复: 是的,因为算的是:当前执行时间,跟*日志时间*的差距 而这个日志时间,是在A上执行出来的。 好问题,很好的验证过程。
2019-01-141027 张永志今天问题回答: GTID主从同步设置时,主库A发现需同步的GTID日志有删掉的,那么A就会报错。 解决办法: 从库B在启动同步前需要设置 gtid_purged,指定GTID同步的起点,使用备份搭建从库时需要这样设置。 如果在从库上执行了单独的操作,导致主库上缺少GTID,那么可以在主库上模拟一个与从库B上GTID一样的空事务,这样主从同步就不会报错了。
张永志今天问题回答: GTID主从同步设置时,主库A发现需同步的GTID日志有删掉的,那么A就会报错。 解决办法: 从库B在启动同步前需要设置 gtid_purged,指定GTID同步的起点,使用备份搭建从库时需要这样设置。 如果在从库上执行了单独的操作,导致主库上缺少GTID,那么可以在主库上模拟一个与从库B上GTID一样的空事务,这样主从同步就不会报错了。作者回复: 你已经理解GTID的机制啦👍
2019-01-14638- Mr.Strive.Z.H.L老师您好: 之前讲过 互为主备 的场景下,会出现循环复制的问题,今天这节讲了GTID。 如果使用GTID,那么 循环复制 的问题自然而然就解决了呀??!!
作者回复: 哈哈,you got it
2019-01-1835  mgxian老师我有一个问题 如果数据库已经有完成了很多事务 实例 A’的 GTID集合和 实例 B的 GTID集合 是不是很大,这个GTID是从binglog里一点一点的解析出来所有的事务的吗?这样是不是会很慢 ?在所有binlog里定位某个GTID是不是效率也很低
mgxian老师我有一个问题 如果数据库已经有完成了很多事务 实例 A’的 GTID集合和 实例 B的 GTID集合 是不是很大,这个GTID是从binglog里一点一点的解析出来所有的事务的吗?这样是不是会很慢 ?在所有binlog里定位某个GTID是不是效率也很低作者回复: 好问题,👍 在binlog文件开头,有一个Previous_gtids, 用于记录 “生成这个binlog的时候,实例的Executed_gtid_set”, 所以启动的时候只需要解析最后一个文件; 同样的,由于有这个Previous_gtids,可以快速地定位GTID在哪个文件里。
2019-01-1523 Lukia对于老师之前对其他他同学的回答还有一点疑问需要请教一下: Master A上的binlog时间不是在事物commit之前写binlog的时间吗,那么在从节点C上的SBM最大值不应该是2分钟吗?(按3分钟的答案来说,Master A上执行的1分钟为啥要算进去呢?) 看过上篇后想到一个问题: 级联复制A->B->C结构下, 从库C的Seconds_Behind_Master的时间计算问题. 假定当前主库A仅有一个DDL要进行变更,耗时1分钟.那么从库C的SBM值最大应该是多少时间? 是1分钟, 2分钟, 还是3分钟呢 ? 带着疑问看了一下测试从库C的binlog文件中的时间戳,得出结论应该是3分钟. 打破之前认知 🤦♀️ . 请老师解惑 , 谢谢 ! 作者回复: 是的,因为算的是:当前执行时间,跟*日志时间*的差距 而这个日志时间,是在A上执行出来的。 好问题,很好的验证过程。
Lukia对于老师之前对其他他同学的回答还有一点疑问需要请教一下: Master A上的binlog时间不是在事物commit之前写binlog的时间吗,那么在从节点C上的SBM最大值不应该是2分钟吗?(按3分钟的答案来说,Master A上执行的1分钟为啥要算进去呢?) 看过上篇后想到一个问题: 级联复制A->B->C结构下, 从库C的Seconds_Behind_Master的时间计算问题. 假定当前主库A仅有一个DDL要进行变更,耗时1分钟.那么从库C的SBM值最大应该是多少时间? 是1分钟, 2分钟, 还是3分钟呢 ? 带着疑问看了一下测试从库C的binlog文件中的时间戳,得出结论应该是3分钟. 打破之前认知 🤦♀️ . 请老师解惑 , 谢谢 ! 作者回复: 是的,因为算的是:当前执行时间,跟*日志时间*的差距 而这个日志时间,是在A上执行出来的。 好问题,很好的验证过程。作者回复: 嗯,多一跳确实是应该多1分钟,在c的最长延迟时间应该是2分钟
2019-02-18320 时隐时现其实基于gtid复制有个大坑,在主库上千万不要执行reset master,否则从库不会报错,只会跳过gno < current_no的事务,造成一个现象就是主库复制没有中断,但是主库上的数据无法同步到从库。
时隐时现其实基于gtid复制有个大坑,在主库上千万不要执行reset master,否则从库不会报错,只会跳过gno < current_no的事务,造成一个现象就是主库复制没有中断,但是主库上的数据无法同步到从库。作者回复: 是的, 不过reset master这种语句。。就算是基于position的协议,谁在线上主库上执行,也是直接当做删数据论处的了😅
2019-01-31217- fuyuseta 和 setb 里的集合大小不会很大?
作者回复: 大没关系呀,是分段的,比如 server_uuid_of_a:1-1000000,就一个段
2019-01-15217  PengfeiWang老师,您好: 文中对于sql_slave_skip_counter=1的理解似乎有偏差,官方文档中的解释是: When you use SET GLOBAL sql_slave_skip_counter to skip events and the result is in the middle of a group, the slave continues to skip events until it reaches the end of the group. Execution then starts with the next event group. 按照官方文档的解释,命令sql_slave_skip_counter=1 应该是跳过一个事务中的1个event,除非这个事务是有单个event组成的,才会跳过一个事务。
PengfeiWang老师,您好: 文中对于sql_slave_skip_counter=1的理解似乎有偏差,官方文档中的解释是: When you use SET GLOBAL sql_slave_skip_counter to skip events and the result is in the middle of a group, the slave continues to skip events until it reaches the end of the group. Execution then starts with the next event group. 按照官方文档的解释,命令sql_slave_skip_counter=1 应该是跳过一个事务中的1个event,除非这个事务是有单个event组成的,才会跳过一个事务。作者回复: 你这个是好问题, 确实只是跳过一个event,不过文档中说了呀 “the slave continues to skip events until it reaches the end of the group. ”, 所以效果上等效于跳过一个事务哦
2019-01-1411

