

02 | 日志系统:一条SQL更新语句是如何执行的?

该思维导图由 AI 生成,仅供参考
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

MySQL更新语句的执行流程涉及连接器、分析器、优化器、执行器等功能模块,以及重做日志和归档日志。重做日志采用WAL技术,先写日志再写磁盘,保证数据库异常重启时不会丢失已提交的记录,实现了crash-safe能力。归档日志记录原始逻辑,不同于重做日志的物理记录。文章详细介绍了更新语句的内部流程,包括执行器和InnoDB引擎的交互过程,以及重做日志的两阶段提交。通过对比重做日志和归档日志的特点,读者能够深入了解MySQL的日志系统设计和执行过程。 文章还介绍了MySQL里面最重要的两个日志,即物理日志redo log和逻辑日志binlog。redo log用于保证crash-safe能力。innodb_flush_log_at_trx_commit参数设置成1时,表示每次事务的redo log都直接持久化到磁盘,建议设置成1以保证数据不丢失。sync_binlog参数设置成1时,表示每次事务的binlog都持久化到磁盘,也建议设置成1以保证binlog不丢失。与MySQL日志系统密切相关的“两阶段提交”是跨系统维持数据逻辑一致性时常用的一个方案。 总结:本文深入介绍了MySQL更新语句的执行流程和日志系统设计,包括重做日志和归档日志的特点,以及两阶段提交的重要性。读者可以从中了解MySQL的日志系统设计和执行过程,以及保证数据安全和一致性的关键参数设置建议。
《MySQL 实战 45 讲》,新⼈⾸单¥68

全部留言(1315)
- 最新
- 精选
 哇!怎么这么大个置顶老师您好,我之前是做运维的,通过binlog恢复误操作的数据,但是实际上,我们会后知后觉,误删除一段时间了,才发现误删除,此时,我把之前误删除的binlog导入,再把误删除之后binlog导入,会出现问题,比如主键冲突,而且binlog导数据,不同模式下时间也有不同,但是一般都是row模式,时间还是很久,有没什么方式,时间短且数据一致性强的方式
哇!怎么这么大个置顶老师您好,我之前是做运维的,通过binlog恢复误操作的数据,但是实际上,我们会后知后觉,误删除一段时间了,才发现误删除,此时,我把之前误删除的binlog导入,再把误删除之后binlog导入,会出现问题,比如主键冲突,而且binlog导数据,不同模式下时间也有不同,但是一般都是row模式,时间还是很久,有没什么方式,时间短且数据一致性强的方式作者回复: 其实恢复数据只能恢复到误删之前到一刻, 误删之后的,不能只靠binlog来做,因为业务逻辑可能因为误删操作的行为,插入了逻辑错误的语句, 所以之后的,跟业务一起,从业务快速补数据的。只靠binlog补出来的往往不完整
2018-12-2017155 小张置顶老师您好,有一个问题,如果在非常极端的情况下,redo log被写满,而redo log涉及的事务均未提交,此时又有新的事务进来时,就要擦除redo log,这就意味着被修改的的脏页此时要被迫被flush到磁盘了,因为用来保证事务持久性的redo log就要消失了。但如若真的执行了这样的操作,数据就在被commit之前被持久化到磁盘中了。当真的遇到这样的恶劣情况时,mysql会如何处理呢,会直接报错吗?还是有什么应对的方法和策略呢?
小张置顶老师您好,有一个问题,如果在非常极端的情况下,redo log被写满,而redo log涉及的事务均未提交,此时又有新的事务进来时,就要擦除redo log,这就意味着被修改的的脏页此时要被迫被flush到磁盘了,因为用来保证事务持久性的redo log就要消失了。但如若真的执行了这样的操作,数据就在被commit之前被持久化到磁盘中了。当真的遇到这样的恶劣情况时,mysql会如何处理呢,会直接报错吗?还是有什么应对的方法和策略呢?作者回复: 👍🏿,会想到这么细致的场景 这些数据在内存中是无效其他事务读不到的(读到了也放弃),同样的,即使写进磁盘,也没关系,再次读到内存以后,还是原来的逻辑
2018-11-2740165 Jason置顶首先谈一下,学习后的收获 redo是物理的,binlog是逻辑的;现在由于redo是属于InnoDB引擎,所以必须要有binlog,因为你可以使用别的引擎 保证数据库的一致性,必须要保证2份日志一致,使用的2阶段式提交;其实感觉像事务,不是成功就是失败,不能让中间环节出现,也就是一个成功,一个失败 如果有一天mysql只有InnoDB引擎了,有redo来实现复制,那么感觉oracle的DG就诞生了,物理的速度也将远超逻辑的,毕竟只记录了改动向量 binlog几大模式,一般采用row,因为遇到时间,从库可能会出现不一致的情况,但是row更新前后都有,会导致日志变大 最后2个参数,保证事务成功,日志必须落盘,这样,数据库crash后,就不会丢失某个事务的数据了 其次说一下,对问题的理解 备份时间周期的长短,感觉有2个方便 首先,是恢复数据丢失的时间,既然需要恢复,肯定是数据丢失了。如果一天一备份的话,只要找到这天的全备,加入这天某段时间的binlog来恢复,如果一周一备份,假设是周一,而你要恢复的数据是周日某个时间点,那就,需要全备+周一到周日某个时间点的全部binlog用来恢复,时间相比前者需要增加很多;看业务能忍受的程度 其次,是数据库丢失,如果一周一备份的话,需要确保整个一周的binlog都完好无损,否则将无法恢复;而一天一备,只要保证这天的binlog都完好无损;当然这个可以通过校验,或者冗余等技术来实现,相比之下,上面那点更重要 不对的地方,望大神指点
Jason置顶首先谈一下,学习后的收获 redo是物理的,binlog是逻辑的;现在由于redo是属于InnoDB引擎,所以必须要有binlog,因为你可以使用别的引擎 保证数据库的一致性,必须要保证2份日志一致,使用的2阶段式提交;其实感觉像事务,不是成功就是失败,不能让中间环节出现,也就是一个成功,一个失败 如果有一天mysql只有InnoDB引擎了,有redo来实现复制,那么感觉oracle的DG就诞生了,物理的速度也将远超逻辑的,毕竟只记录了改动向量 binlog几大模式,一般采用row,因为遇到时间,从库可能会出现不一致的情况,但是row更新前后都有,会导致日志变大 最后2个参数,保证事务成功,日志必须落盘,这样,数据库crash后,就不会丢失某个事务的数据了 其次说一下,对问题的理解 备份时间周期的长短,感觉有2个方便 首先,是恢复数据丢失的时间,既然需要恢复,肯定是数据丢失了。如果一天一备份的话,只要找到这天的全备,加入这天某段时间的binlog来恢复,如果一周一备份,假设是周一,而你要恢复的数据是周日某个时间点,那就,需要全备+周一到周日某个时间点的全部binlog用来恢复,时间相比前者需要增加很多;看业务能忍受的程度 其次,是数据库丢失,如果一周一备份的话,需要确保整个一周的binlog都完好无损,否则将无法恢复;而一天一备,只要保证这天的binlog都完好无损;当然这个可以通过校验,或者冗余等技术来实现,相比之下,上面那点更重要 不对的地方,望大神指点作者回复: 👍🏿置顶了 你说的物理复制业界有团队在做了 而且官方新版本也把MySQL的表结构都收归InnoDB管理了😄
2018-11-1635799 Godruoyi置顶Bin log 用于记录了完整的逻辑记录,所有的逻辑记录在 bin log 里都能找到,所以在备份恢复时,是以 bin log 为基础,通过其记录的完整逻辑操作,备份出一个和原库完整的数据。 在两阶段提交时,若 redo log 写入成功,bin log 写入失败,则后续通过 bin log 恢复时,恢复的数据将会缺失一部分。(如 redo log 执行了 update t set status = 1,此时原库的数据 status 已更新为 1,而 bin log 写入失败,没有记录这一操作,后续备份恢复时,其 status = 0,导致数据不一致)。 若先写入 bin log,当 bin log 写入成功,而 redo log 写入失败时,原库中的 status 仍然是 0 ,但是当通过 bin log 恢复时,其记录的操作是 set status = 1,也会导致数据不一致。 其核心就是, redo log 记录的,即使异常重启,都会刷新到磁盘,而 bin log 记录的, 则主要用于备份。 我可以这样理解吗?还有就是如何保证 redo log 和 bin log 操作的一致性啊?
Godruoyi置顶Bin log 用于记录了完整的逻辑记录,所有的逻辑记录在 bin log 里都能找到,所以在备份恢复时,是以 bin log 为基础,通过其记录的完整逻辑操作,备份出一个和原库完整的数据。 在两阶段提交时,若 redo log 写入成功,bin log 写入失败,则后续通过 bin log 恢复时,恢复的数据将会缺失一部分。(如 redo log 执行了 update t set status = 1,此时原库的数据 status 已更新为 1,而 bin log 写入失败,没有记录这一操作,后续备份恢复时,其 status = 0,导致数据不一致)。 若先写入 bin log,当 bin log 写入成功,而 redo log 写入失败时,原库中的 status 仍然是 0 ,但是当通过 bin log 恢复时,其记录的操作是 set status = 1,也会导致数据不一致。 其核心就是, redo log 记录的,即使异常重启,都会刷新到磁盘,而 bin log 记录的, 则主要用于备份。 我可以这样理解吗?还有就是如何保证 redo log 和 bin log 操作的一致性啊?作者回复: 几乎全对,除了这个“两阶段提交时,若redo log写入成功,但binlog写入失败…”这句话。 实际上,因为是两阶段提交,这时候redolog只是完成了prepare, 而binlog又失败,那么事务本身会回滚,所以这个库里面status的值是0。 如果通过binlog 恢复出一个库,status值也是0。 这样不算丢失,这样是合理的结果。 两阶段就是保证一致性用的。 你不用担心日志写错,那样就是bug了…
2018-11-1658267 lfn置顶老师,今天MYSQL第二讲中提到binlog和redo log, 我感觉binlog很多余,按理是不是只要redo log就够了?[费解] 您讲的时候说redo log是InnoDB的要求,因为以plugin的形式加入到MySQL中,此时binlog作为Server层的日志已然存在,所以便有了两者共存的现状。但我觉得这并不能解释我们在只用InonoDB引擎的时候还保留Binlog这种设计的原因.
lfn置顶老师,今天MYSQL第二讲中提到binlog和redo log, 我感觉binlog很多余,按理是不是只要redo log就够了?[费解] 您讲的时候说redo log是InnoDB的要求,因为以plugin的形式加入到MySQL中,此时binlog作为Server层的日志已然存在,所以便有了两者共存的现状。但我觉得这并不能解释我们在只用InonoDB引擎的时候还保留Binlog这种设计的原因.作者回复: binlog还不能去掉。 一个原因是,redolog只有InnoDB有,别的引擎没有。 另一个原因是,redolog是循环写的,不持久保存,binlog的“归档”这个功能,redolog是不具备的。
2018-11-1676532 ricktian置顶redo log的机制看起来和ring buffer一样的; 另外有个和高枕、思雨一样的疑问,如果在重启后,需要通过检查binlog来确认redo log中处于prepare的事务是否需要commit,那是否不需要二阶段提交,直接以binlog的为准,如果binlog中不存在的,就认为是需要回滚的。这个地方,是不是我漏了什么,拉不通。。。 麻烦老师解下疑,多谢~
ricktian置顶redo log的机制看起来和ring buffer一样的; 另外有个和高枕、思雨一样的疑问,如果在重启后,需要通过检查binlog来确认redo log中处于prepare的事务是否需要commit,那是否不需要二阶段提交,直接以binlog的为准,如果binlog中不存在的,就认为是需要回滚的。这个地方,是不是我漏了什么,拉不通。。。 麻烦老师解下疑,多谢~作者回复: 文章中有提到“binlog没有被用来做崩溃恢复”, 历史上的原因是,这个是一开始就这么设计的,所以不能只依赖binlog。 操作上的原因是,binlog是可以关的,你如果有权限,可以set sql_log_bin=0关掉本线程的binlog日志。 所以只依赖binlog来恢复就靠不住。 @高枕、@思雨 也看下这个讨论😄
2018-11-162783 DanielAnton置顶有个问题请教老师,既然write pos和checkout都是往后推移并循环的,而且当write pos赶上checkout的时候要停下来,将checkout往后推进,那么是不是意味着write pos的位置始终在checkout后面,最多在一起,而这和老师画的图有些出入,不知道我的理解是不是有些错误,请老师指教。
DanielAnton置顶有个问题请教老师,既然write pos和checkout都是往后推移并循环的,而且当write pos赶上checkout的时候要停下来,将checkout往后推进,那么是不是意味着write pos的位置始终在checkout后面,最多在一起,而这和老师画的图有些出入,不知道我的理解是不是有些错误,请老师指教。作者回复: 因为是“循环”的,图中这个状态下,write_pos 往前写,写到3号文件末尾,就回到0号继续写,这样你再理解看看“追”的状态。 刚好借你这个问题,说明一下,文中“write pos和checkpoint之间的是’粉板’上还空着的部分,可以用来记录新的操作。” 这句话,说的“空着的部分”,就是write pos 到3号文件末尾,再加上0号文件开头到checkpoint 的部分。
2018-11-161743 super blue cat置顶我可以认为redo log 记录的是这个行在这个页更新之后的状态,binlog 记录的是sql吗?
super blue cat置顶我可以认为redo log 记录的是这个行在这个页更新之后的状态,binlog 记录的是sql吗?作者回复: Redo log不是记录数据页“更新之后的状态”,而是记录这个页 “做了什么改动”。 Binlog有两种模式,statement 格式的话是记sql语句, row格式会记录行的内容,记两条,更新前和更新后都有。 (谢谢你提这个问题,为了不打断文章思路,这个点没在正文写,但是又是很重要的点😄😄)
2018-11-16861225 高枕我再来说下自己的理解 。 1 prepare阶段 2 写binlog 3 commit 当在2之前崩溃时 重启恢复:后发现没有commit,回滚。备份恢复:没有binlog 。 一致 当在3之前崩溃 重启恢复:虽没有commit,但满足prepare和binlog完整,所以重启后会自动commit。备份:有binlog. 一致
高枕我再来说下自己的理解 。 1 prepare阶段 2 写binlog 3 commit 当在2之前崩溃时 重启恢复:后发现没有commit,回滚。备份恢复:没有binlog 。 一致 当在3之前崩溃 重启恢复:虽没有commit,但满足prepare和binlog完整,所以重启后会自动commit。备份:有binlog. 一致作者回复: 👍🏿,get 完成
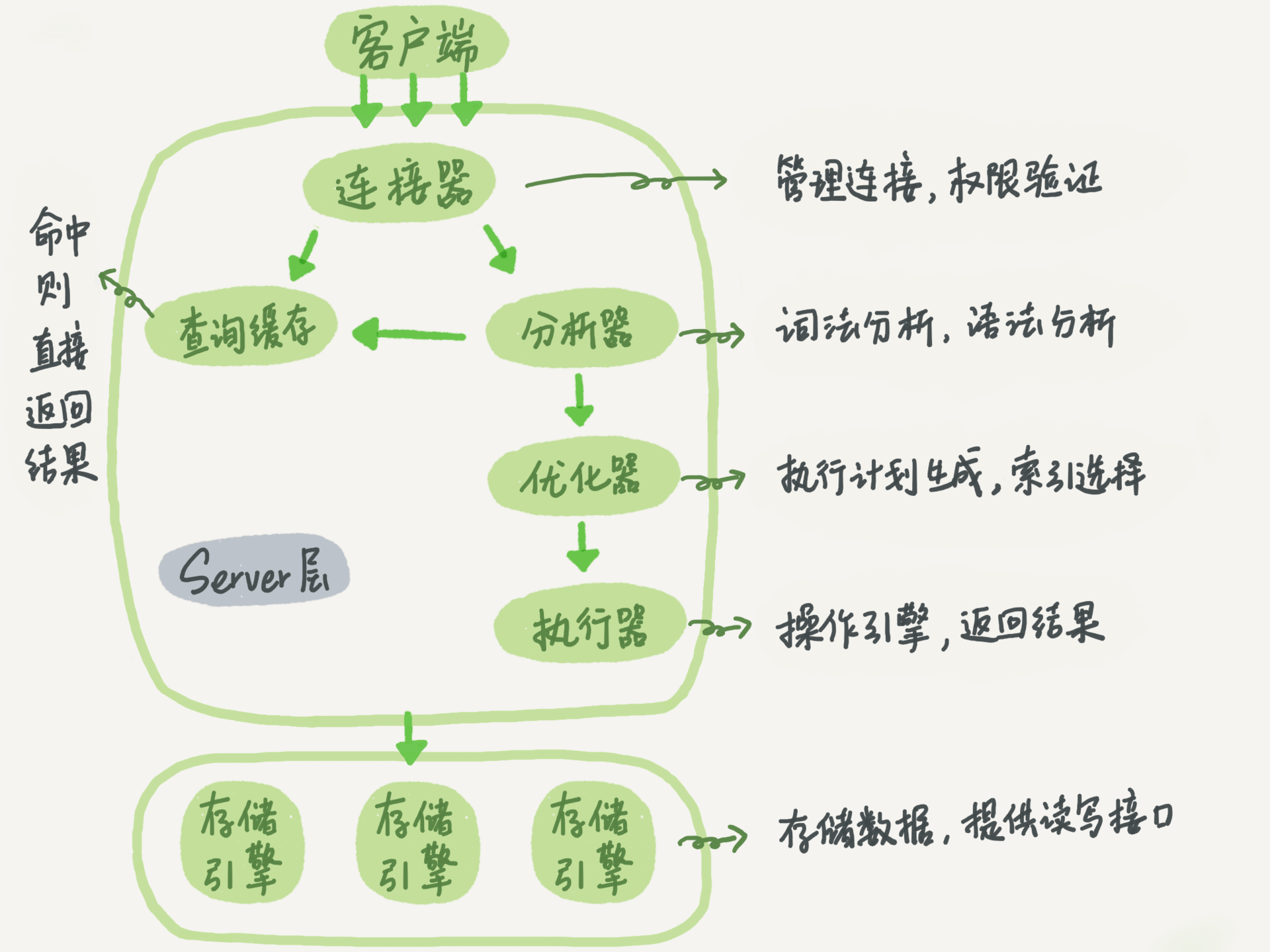
2018-11-16951064 某、人1.首先客户端通过tcp/ip发送一条sql语句到server层的SQL interface 2.SQL interface接到该请求后,先对该条语句进行解析,验证权限是否匹配 3.验证通过以后,分析器会对该语句分析,是否语法有错误等 4.接下来是优化器器生成相应的执行计划,选择最优的执行计划 5.之后会是执行器根据执行计划执行这条语句。在这一步会去open table,如果该table上有MDL,则等待。 如果没有,则加在该表上加短暂的MDL(S) (如果opend_table太大,表明open_table_cache太小。需要不停的去打开frm文件) 6.进入到引擎层,首先会去innodb_buffer_pool里的data dictionary(元数据信息)得到表信息 7.通过元数据信息,去lock info里查出是否会有相关的锁信息,并把这条update语句需要的 锁信息写入到lock info里(锁这里还有待补充) 8.然后涉及到的老数据通过快照的方式存储到innodb_buffer_pool里的undo page里,并且记录undo log修改的redo (如果data page里有就直接载入到undo page里,如果没有,则需要去磁盘里取出相应page的数据,载入到undo page里) 9.在innodb_buffer_pool的data page做update操作。并把操作的物理数据页修改记录到redo log buffer里 由于update这个事务会涉及到多个页面的修改,所以redo log buffer里会记录多条页面的修改信息。 因为group commit的原因,这次事务所产生的redo log buffer可能会跟随其它事务一同flush并且sync到磁盘上 10.同时修改的信息,会按照event的格式,记录到binlog_cache中。(这里注意binlog_cache_size是transaction级别的,不是session级别的参数, 一旦commit之后,dump线程会从binlog_cache里把event主动发送给slave的I/O线程) 11.之后把这条sql,需要在二级索引上做的修改,写入到change buffer page,等到下次有其他sql需要读取该二级索引时,再去与二级索引做merge (随机I/O变为顺序I/O,但是由于现在的磁盘都是SSD,所以对于寻址来说,随机I/O和顺序I/O差距不大) 12.此时update语句已经完成,需要commit或者rollback。这里讨论commit的情况,并且双1 13.commit操作,由于存储引擎层与server层之间采用的是内部XA(保证两个事务的一致性,这里主要保证redo log和binlog的原子性), 所以提交分为prepare阶段与commit阶段 14.prepare阶段,将事务的xid写入,将binlog_cache里的进行flush以及sync操作(大事务的话这步非常耗时) 15.commit阶段,由于之前该事务产生的redo log已经sync到磁盘了。所以这步只是在redo log里标记commit 16.当binlog和redo log都已经落盘以后,如果触发了刷新脏页的操作,先把该脏页复制到doublewrite buffer里,把doublewrite buffer里的刷新到共享表空间,然后才是通过page cleaner线程把脏页写入到磁盘中 老师,你看我的步骤中有什么问题嘛?我感觉第6步那里有点问题,因为第5步已经去open table了,第6步还有没有必要去buffer里查找元数据呢?这元数据是表示的系统的元数据嘛,还是所有表的?谢谢老师指正
某、人1.首先客户端通过tcp/ip发送一条sql语句到server层的SQL interface 2.SQL interface接到该请求后,先对该条语句进行解析,验证权限是否匹配 3.验证通过以后,分析器会对该语句分析,是否语法有错误等 4.接下来是优化器器生成相应的执行计划,选择最优的执行计划 5.之后会是执行器根据执行计划执行这条语句。在这一步会去open table,如果该table上有MDL,则等待。 如果没有,则加在该表上加短暂的MDL(S) (如果opend_table太大,表明open_table_cache太小。需要不停的去打开frm文件) 6.进入到引擎层,首先会去innodb_buffer_pool里的data dictionary(元数据信息)得到表信息 7.通过元数据信息,去lock info里查出是否会有相关的锁信息,并把这条update语句需要的 锁信息写入到lock info里(锁这里还有待补充) 8.然后涉及到的老数据通过快照的方式存储到innodb_buffer_pool里的undo page里,并且记录undo log修改的redo (如果data page里有就直接载入到undo page里,如果没有,则需要去磁盘里取出相应page的数据,载入到undo page里) 9.在innodb_buffer_pool的data page做update操作。并把操作的物理数据页修改记录到redo log buffer里 由于update这个事务会涉及到多个页面的修改,所以redo log buffer里会记录多条页面的修改信息。 因为group commit的原因,这次事务所产生的redo log buffer可能会跟随其它事务一同flush并且sync到磁盘上 10.同时修改的信息,会按照event的格式,记录到binlog_cache中。(这里注意binlog_cache_size是transaction级别的,不是session级别的参数, 一旦commit之后,dump线程会从binlog_cache里把event主动发送给slave的I/O线程) 11.之后把这条sql,需要在二级索引上做的修改,写入到change buffer page,等到下次有其他sql需要读取该二级索引时,再去与二级索引做merge (随机I/O变为顺序I/O,但是由于现在的磁盘都是SSD,所以对于寻址来说,随机I/O和顺序I/O差距不大) 12.此时update语句已经完成,需要commit或者rollback。这里讨论commit的情况,并且双1 13.commit操作,由于存储引擎层与server层之间采用的是内部XA(保证两个事务的一致性,这里主要保证redo log和binlog的原子性), 所以提交分为prepare阶段与commit阶段 14.prepare阶段,将事务的xid写入,将binlog_cache里的进行flush以及sync操作(大事务的话这步非常耗时) 15.commit阶段,由于之前该事务产生的redo log已经sync到磁盘了。所以这步只是在redo log里标记commit 16.当binlog和redo log都已经落盘以后,如果触发了刷新脏页的操作,先把该脏页复制到doublewrite buffer里,把doublewrite buffer里的刷新到共享表空间,然后才是通过page cleaner线程把脏页写入到磁盘中 老师,你看我的步骤中有什么问题嘛?我感觉第6步那里有点问题,因为第5步已经去open table了,第6步还有没有必要去buffer里查找元数据呢?这元数据是表示的系统的元数据嘛,还是所有表的?谢谢老师指正作者回复: 其实在实现上5是调用了6的过程了的,所以是一回事。MySQL server 层和InnoDB层都保存了表结构,所以有书上描述时会拆开说。 这个描述很详细,同时还有点到我们后面要讲的内通(编辑快来,有人来砸场子啦😄😄)
2018-11-16100665

