

11 | 怎么给字符串字段加索引?

该思维导图由 AI 生成,仅供参考
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

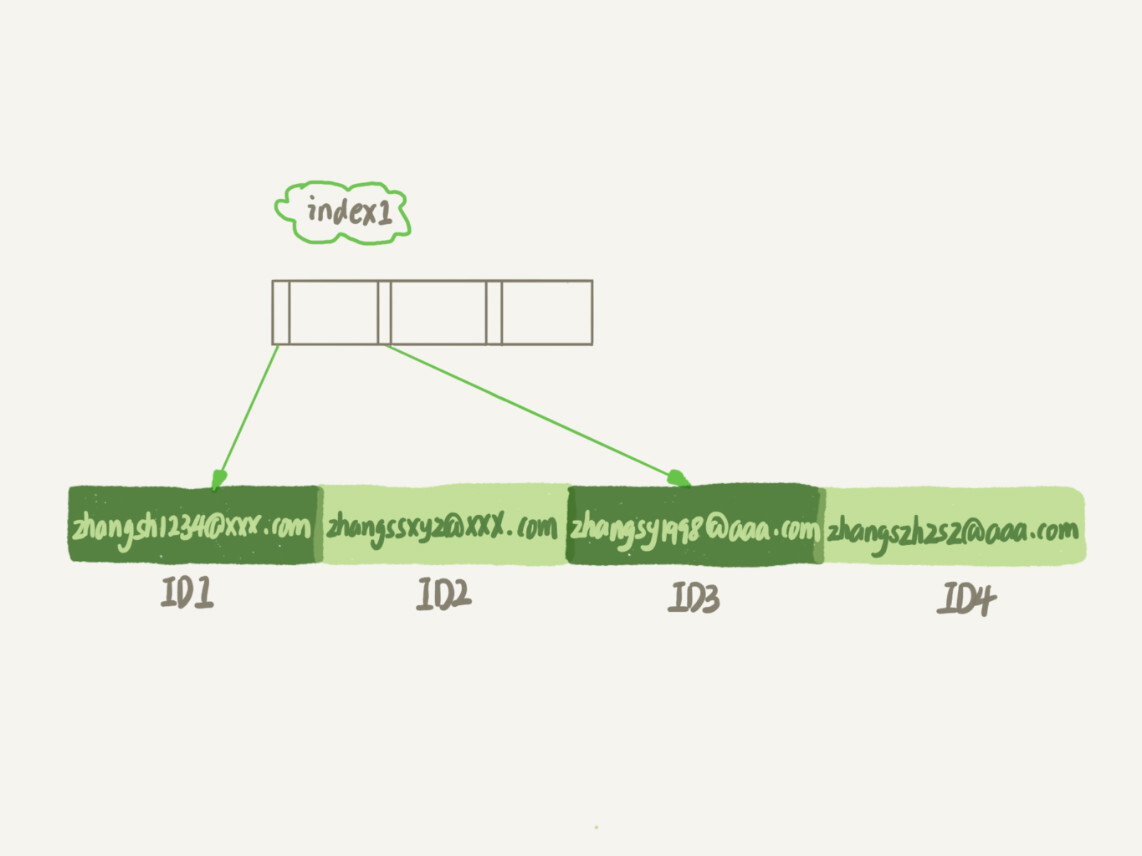
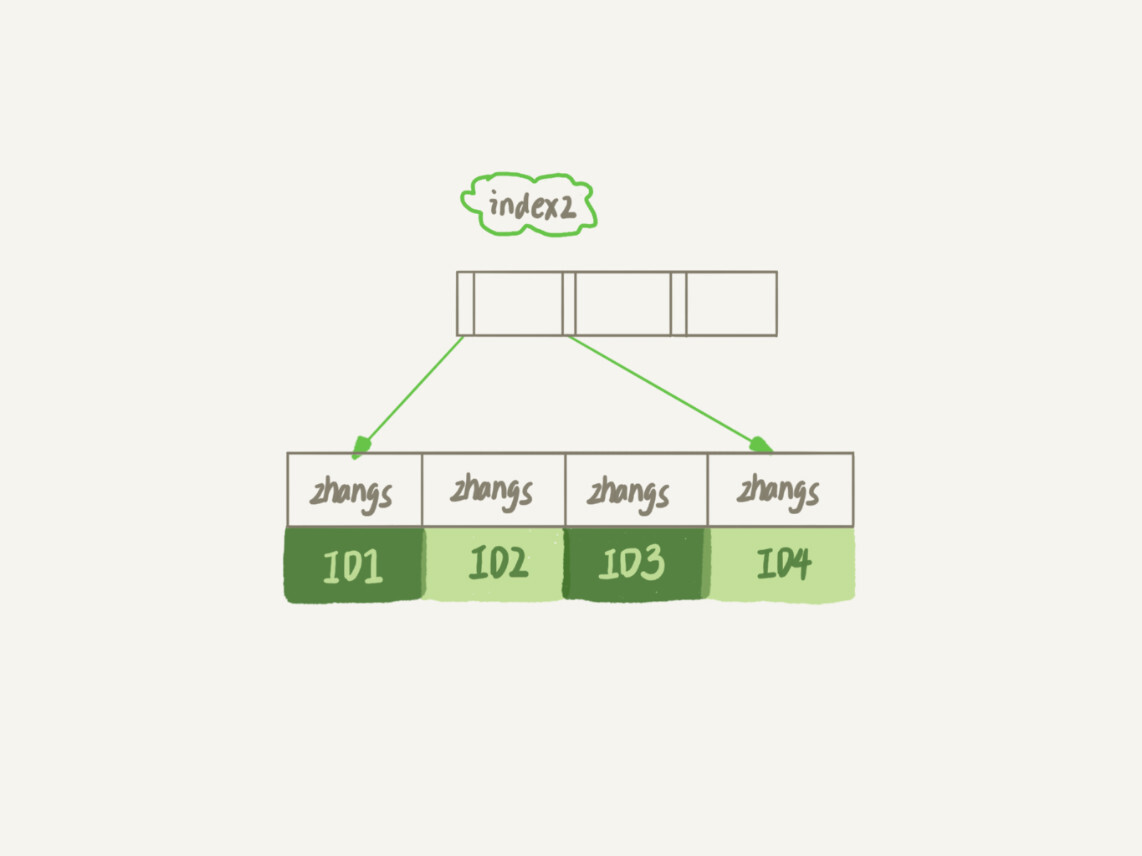
本文介绍了如何给字符串字段加索引以及前缀索引对查询性能的影响。首先,文章讨论了在支持邮箱登录的系统中,如何在邮箱字段上建立合理的索引。通过对比全字段索引和前缀索引的执行过程,阐述了前缀索引可能增加查询成本的情况。接着,文章提出了确定前缀长度的方法,即通过统计索引上不同值的数量来选择合适的前缀长度。此外,文章还掏出了前缀索引对覆盖索引的影响,指出使用前缀索引可能无法充分利用覆盖索引对查询性能的优化。总的来说,本文通过具体的案例和对比分析,帮助读者了解了如何在实际业务中合理地使用字符串字段的索引,以及前缀索引可能带来的影响。 文章还介绍了在特定场景下,如何处理前缀索引的区分度不够好的情况。举例说明了对身份证号进行索引时,可能需要使用倒序存储或者hash字段的方式来提高查询性能和节省空间。同时,对比了这两种方法在占用空间、CPU消耗和查询效率方面的异同点,为读者提供了多种处理方式的选择。 最后,文章提出了一个问题,讨论了在学生信息数据库中,如何设计学生登录名的索引。通过这些内容,读者可以了解到不同情景下索引设计的考量和选择,以及如何根据业务需求来优化索引的设计。整体而言,本文为读者提供了丰富的索引设计知识和实际应用场景,帮助他们更好地理解和应用索引技术。
《MySQL 实战 45 讲》,新⼈⾸单¥68

全部留言(221)
- 最新
- 精选
 封建的风原谅我偷懒的想法,一个学校每年预估2万新生,50年才100万记录,能节省多少空间,直接全字段索引。省去了开发转换及局限性风险,碰到超大量迫不得已再用后两种办法
封建的风原谅我偷懒的想法,一个学校每年预估2万新生,50年才100万记录,能节省多少空间,直接全字段索引。省去了开发转换及局限性风险,碰到超大量迫不得已再用后两种办法作者回复: 从业务量预估优化和收益,这个意识很好呢👍🏿
2018-12-0835703 老杨同志老师整篇都讲的是字符串索引,但是思考题的学号比较特殊,15位数字+固定后缀“@gmail.com” 这种特殊的情况,可以把学号使用bigint存储,占4个字节,比前缀索引空间占用要小。跟hash索引比, 也有区间查询的优势
老杨同志老师整篇都讲的是字符串索引,但是思考题的学号比较特殊,15位数字+固定后缀“@gmail.com” 这种特殊的情况,可以把学号使用bigint存储,占4个字节,比前缀索引空间占用要小。跟hash索引比, 也有区间查询的优势作者回复: Bigint 8 个字节哦,赞思路。 嗯问题不是唯一答案,大家集思广益哈
2018-12-0710134 某、人老师针对上一期的答案有两个问题: 1.为什么事务A未提交,之前插入的10W数据不能删除啊?不是应该都进undo和change buffer了嘛, 根据mvcc查之前的版本就可以了啊。 2.不明白为什么第二次调用插入的存储过程,id就变为100000-200000,id是固定插入的,又不是自增的
某、人老师针对上一期的答案有两个问题: 1.为什么事务A未提交,之前插入的10W数据不能删除啊?不是应该都进undo和change buffer了嘛, 根据mvcc查之前的版本就可以了啊。 2.不明白为什么第二次调用插入的存储过程,id就变为100000-200000,id是固定插入的,又不是自增的作者回复: 1. 这里说的“不能删”,其实就是说的,undo log不能删,逻辑上还在 2. 你说的对… 😓我最开始的例子是用自增主键,改完自己晕了,堪误了哈
2018-12-071365 小潘可以考虑根据字符串字段业务特性做进制压缩,业务上一般会限制每个字符的范围(如字母数字下划线)。 从信息论的角度看,每个字节并没有存8 bit的信息量。如果单个字符的取值只有n种可能性(把字符转成0到n-1的数字),可以考虑把n进制转为为更高进制存储(ascii可看做是128进制)。 这样既可以减少索引长度,又可以很大程度上兼顾前缀匹配。
小潘可以考虑根据字符串字段业务特性做进制压缩,业务上一般会限制每个字符的范围(如字母数字下划线)。 从信息论的角度看,每个字节并没有存8 bit的信息量。如果单个字符的取值只有n种可能性(把字符转成0到n-1的数字),可以考虑把n进制转为为更高进制存储(ascii可看做是128进制)。 这样既可以减少索引长度,又可以很大程度上兼顾前缀匹配。作者回复: 这个有点高端了😄
2018-12-071463 一撮韶光删的时候,由于有未提交事务开启的一致性视图read-view,所以导致了存在两个数据版本的数据,貌似优化器在"看"二级索引的时候,"看到"了多个历史版本的数据,错误以为有很多数据 而主键索引数量由于确认机制不同,数量没有变,综合考虑,优化器选择了主键索引
一撮韶光删的时候,由于有未提交事务开启的一致性视图read-view,所以导致了存在两个数据版本的数据,貌似优化器在"看"二级索引的时候,"看到"了多个历史版本的数据,错误以为有很多数据 而主键索引数量由于确认机制不同,数量没有变,综合考虑,优化器选择了主键索引作者回复: 👍🏿
2018-12-0936 Tony Du对于上一期的问题的回答,“索引 a 上的数据其实就有两份”,是不是这样理解, 其中一份是已经被标记为deleted的数据,另一份是新插入的数据,对索引数据的预估把已经被标记为deleted的数据也算上去了?MySQL对索引数据的预估为什么不去check 被标记为deleted的数据? 这种场景一旦发生,就会导致预估索引数据不准确,有什么好的方法去避免和解决?
Tony Du对于上一期的问题的回答,“索引 a 上的数据其实就有两份”,是不是这样理解, 其中一份是已经被标记为deleted的数据,另一份是新插入的数据,对索引数据的预估把已经被标记为deleted的数据也算上去了?MySQL对索引数据的预估为什么不去check 被标记为deleted的数据? 这种场景一旦发生,就会导致预估索引数据不准确,有什么好的方法去避免和解决?作者回复: 理解对的, 方法就是避免长事务(session A 就是模拟一个长事务)
2018-12-0725 叶剑峰我觉得建立索引和插入数据在实际生产过程中可能是相互迭代的。先建立索引--后插入数据--再优化索引,再插入数据,所以文中说的几种方法都要知道下,具体不同情况不同看。像人员表邮箱这个字段,会先建立全字符串索引,要是业务发展到人员表暴增,导致磁盘比较多,才会想到优化某种长度的字符串索引
叶剑峰我觉得建立索引和插入数据在实际生产过程中可能是相互迭代的。先建立索引--后插入数据--再优化索引,再插入数据,所以文中说的几种方法都要知道下,具体不同情况不同看。像人员表邮箱这个字段,会先建立全字符串索引,要是业务发展到人员表暴增,导致磁盘比较多,才会想到优化某种长度的字符串索引作者回复: 差不多是这样的 一般在你说的这个迭代之前,会再多一个“业务量预估”😆
2019-01-1611 V
V 请教一个问题, 下面这条SQL order_id 和 user_id 都是 int 类型,都加了索引,在看 EXPLAIN 的时候 执行只使用了 order_id 索引, 为什么 user_id 索引没有采用呢?如果WHERE 条件后面都有索引是否都会执行、还是优化器会选择最有效率都一个索引执行? 将两个调整成组合索引也没有效果, 如果 force index(user_id) 则全表扫描。 能帮忙解答下吗?谢谢 SELECT count(1) FROM A a WHERE EXISTS( SELECT 1 FROM B b WHERE b.order_id = a.order_id AND b.user_id = a.user_id );
请教一个问题, 下面这条SQL order_id 和 user_id 都是 int 类型,都加了索引,在看 EXPLAIN 的时候 执行只使用了 order_id 索引, 为什么 user_id 索引没有采用呢?如果WHERE 条件后面都有索引是否都会执行、还是优化器会选择最有效率都一个索引执行? 将两个调整成组合索引也没有效果, 如果 force index(user_id) 则全表扫描。 能帮忙解答下吗?谢谢 SELECT count(1) FROM A a WHERE EXISTS( SELECT 1 FROM B b WHERE b.order_id = a.order_id AND b.user_id = a.user_id );作者回复: 只能用一个索引,如果两个都用就是merge-index算法,一般优化器很少采用
2018-12-138 不似旧日干货满满, 做个笔记感觉把文章有抄了一遍。
不似旧日干货满满, 做个笔记感觉把文章有抄了一遍。作者回复: 😆 这个评价很高呢😆
2019-10-313
 Smile老师,你好,针对session A 和session B 问题统计不一致问题是否可以理解为: 1. 由于session A 对之前的记录还有引用,所以session B即便做了delete,purge还是无法删除undo log和记录本身,加上新的insert,产生了新的数据页,老的数据页和新的数据页,对采样的结果产生了影响。 2. 上述采样的影响,由于是采样,不同mysql系统的统计的结果应该是会有差别的,比如第十节课中是3W多行,而第十一节课演示中显示有10W多行。 3. 如果是一个session, 假设purge线程在回收其他内容(purge线程很繁忙),无暇回收这个session的delete的内容, 那是否可能也出现,统计结果差很大的情况呢? 还望老师抽空解答。感谢!
Smile老师,你好,针对session A 和session B 问题统计不一致问题是否可以理解为: 1. 由于session A 对之前的记录还有引用,所以session B即便做了delete,purge还是无法删除undo log和记录本身,加上新的insert,产生了新的数据页,老的数据页和新的数据页,对采样的结果产生了影响。 2. 上述采样的影响,由于是采样,不同mysql系统的统计的结果应该是会有差别的,比如第十节课中是3W多行,而第十一节课演示中显示有10W多行。 3. 如果是一个session, 假设purge线程在回收其他内容(purge线程很繁忙),无暇回收这个session的delete的内容, 那是否可能也出现,统计结果差很大的情况呢? 还望老师抽空解答。感谢!作者回复: 1. 是的 2. 你看下,三万多行的对应的key字段和十万多行的key字段不一样 3. 会的
2018-12-1033

