

26 | 备库为什么会延迟好几个小时?

该思维导图由 AI 生成,仅供参考
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

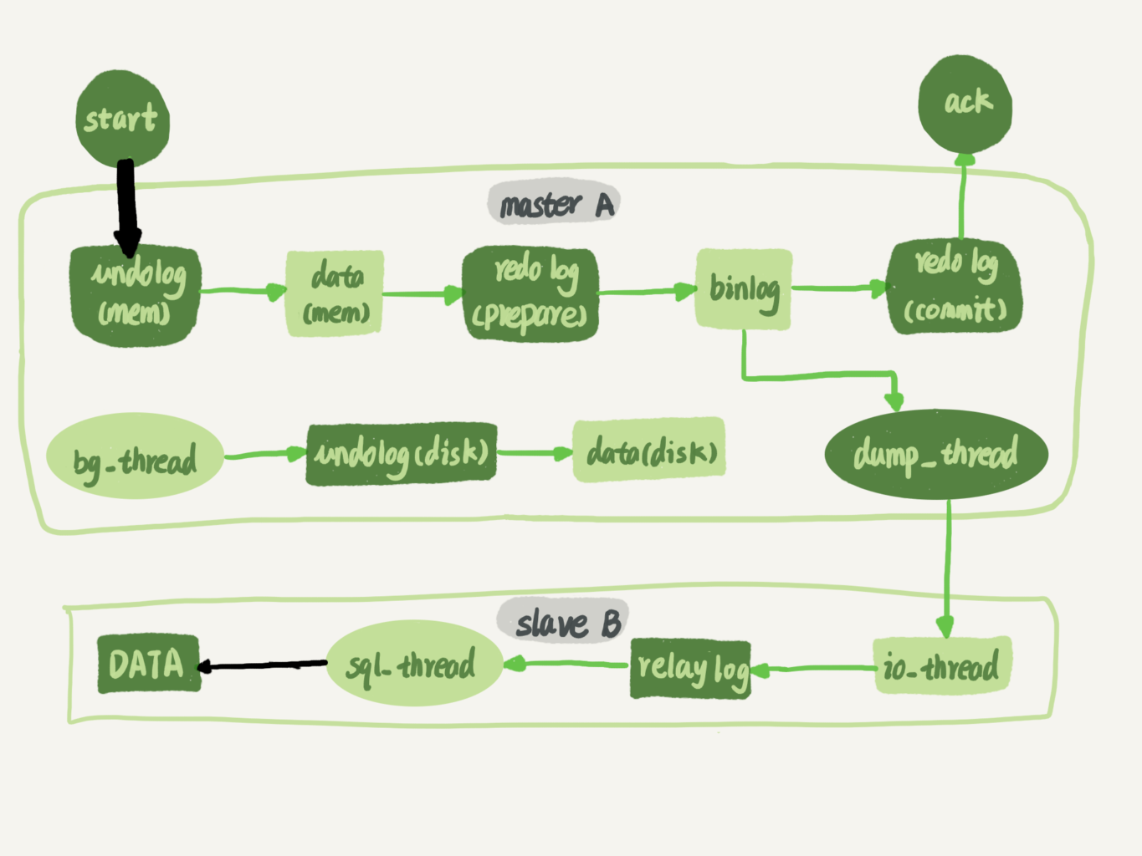
MySQL的并行复制策略是解决备库延迟问题的关键。在MySQL 5.5版本中,通过按表和按行分发策略实现多线程复制,但存在一些限制。随着版本的演进,MySQL 5.6和5.7版本新增了按库并行和基于WRITESET的并行复制策略,提高了备库的同步速度。这些策略的实现原理和优缺点都得到了详细介绍,包括对大事务的影响和参数调整的建议。此外,文章还提到了MariaDB的并行复制策略,以及备库主备延迟表现为45度线段的原因。总的来说,文章通过对MySQL的多线程复制策略进行深入分析,为读者提供了全面的技术视角和实践建议。
《MySQL 实战 45 讲》,新⼈⾸单¥68

全部留言(93)
- 最新
- 精选
- jike置顶老师您好,开启并行复制后,事务是按照组来提交的,从库也是根据commit_id来回放,如果从库也开启binlog的话,那是不是存在主从的binlog event写入顺序不一致的情况呢?
作者回复: 是有可能binlog event写入顺序不同的,好问题
2019-01-15633  长杰置顶举个例子,一个事务更新了表 t1 和表 t2 中的各一行,如果这两条更新语句被分到不同 worker 的话,虽然最终的结果是主备一致的,但如果表 t1 执行完成的瞬间,备库上有一个查询,就会看到这个事务“更新了一半的结果”,破坏了事务逻辑的原子性。 老师这块不太明白,备库有查询会看到更新了一半的结果,t1的worker执行完了更新会commit吗?如果不commit,备库查询应该看不到吧?如果commit,就破坏了事物的原子性,肯定是有问题的。
长杰置顶举个例子,一个事务更新了表 t1 和表 t2 中的各一行,如果这两条更新语句被分到不同 worker 的话,虽然最终的结果是主备一致的,但如果表 t1 执行完成的瞬间,备库上有一个查询,就会看到这个事务“更新了一半的结果”,破坏了事务逻辑的原子性。 老师这块不太明白,备库有查询会看到更新了一半的结果,t1的worker执行完了更新会commit吗?如果不commit,备库查询应该看不到吧?如果commit,就破坏了事物的原子性,肯定是有问题的。作者回复: 应该是说,它迟早要commit,但是两个worker是两个线程,没办法约好“同时提交”,这样就有可能出现一个先提交一个后提交。 这两个提交之间的时间差,就能被用户看到“一半事务”,好问题
2019-01-111458 老杨同志置顶尝试回答 慧鑫coming 的问题。 老师图片的步骤有下面5步 1 redo log prepare write 2 binlog write 3 redo log prepare fsync 4 binlog fsync 5 redo log commit write 1)如果更新通一条记录是有锁的,只能一个事务执行,其他事务等待锁。 2)第4步的时候会因为下面两个参数,等其他没有锁冲突的事务,一起刷盘,此时一起执行的事务拥有相同的commit_id binlog_group_commit_sync_delay binlog_group_commit_sync_no_delay_count 3)执行步骤5后,释放锁,等待锁的事务开始执行。 所以对同一行更新的事务,不可能拥有相同的commit_id
老杨同志置顶尝试回答 慧鑫coming 的问题。 老师图片的步骤有下面5步 1 redo log prepare write 2 binlog write 3 redo log prepare fsync 4 binlog fsync 5 redo log commit write 1)如果更新通一条记录是有锁的,只能一个事务执行,其他事务等待锁。 2)第4步的时候会因为下面两个参数,等其他没有锁冲突的事务,一起刷盘,此时一起执行的事务拥有相同的commit_id binlog_group_commit_sync_delay binlog_group_commit_sync_no_delay_count 3)执行步骤5后,释放锁,等待锁的事务开始执行。 所以对同一行更新的事务,不可能拥有相同的commit_id作者回复: 👍,你比我回复得详细,顶起
2019-01-115118 HuaMax课后题。关键点在于主库单线程,针对三种不同的策略,COMMIT_ORDER:没有同时到达redo log的prepare 状态的事务,备库退化为单线程;WRITESET:通过对比更新的事务是否存在冲突的行,可以并发执行;WRITE_SESSION:在WRITESET的基础上增加了线程的约束,则退化为单线程。综上,应选择WRITESET策略
HuaMax课后题。关键点在于主库单线程,针对三种不同的策略,COMMIT_ORDER:没有同时到达redo log的prepare 状态的事务,备库退化为单线程;WRITESET:通过对比更新的事务是否存在冲突的行,可以并发执行;WRITE_SESSION:在WRITESET的基础上增加了线程的约束,则退化为单线程。综上,应选择WRITESET策略作者回复: 准确👍
2019-01-12792 每天晒白牙我是做java的,看老师的这个专栏,确实挺吃力的,老师专栏的干货太多了,下面的留言也是相当有水平,质量都很高,互动也好,应该是好多DBA吧,做java的我,看的头大
每天晒白牙我是做java的,看老师的这个专栏,确实挺吃力的,老师专栏的干货太多了,下面的留言也是相当有水平,质量都很高,互动也好,应该是好多DBA吧,做java的我,看的头大作者回复: 这几篇偏深,但确实是大家在使用的时候需要了解的, 到30篇后面的文章会偏应用哈
2019-01-131859- 慧鑫coming老师,有个问题,mariadb的并行策略,当同一组中有3个事务,它们都对同一行同一字段值进行更改,而它们的commit_id相同,可以在从库并行执行,那么3者的先后顺序是怎么保证不影响该行该字段的最终结果与主库一致?
作者回复: 好问题 不过这个是不可能的哈,对同一行的修改,第一个拿到行锁的事务还没提交前,另外两个会被行锁堵住的,这两个进入不了commit状态。所以这三个的commit_id不会相同的😆
2019-01-11434  某、人总结下多线程复制的流程,有不对之处请老师指出: 双1,配置为logical_clock,假设有三个事务并发执行也已经执行完成(都处于prepare阶段) 1.三个事务把redo log从redo log buffer写到fs page cache中 2.把binlog_cache flush到binlog文件中,最先进入flush队列的为leader, 其它两个事务为follower.把组员编号以及组的编号写进binlog文件中(三个事务为同一组). 3.三个事务的redo log做fsync,binlog做fsync. 4.dump线程从binlog文件里把binlog event发送给从库 5.I/O线程接收到binlog event,写到relay log中 6.sql thread读取relay log,判断出这三个事务是处于同一个组, 则把这三个事务的event打包发送给三个空闲的worker线程(如果有)并执行。 配置为writeset的多线程复制流程: 1.三个事务把redo log从redo log buffer写到fs page cache中 2.把binlog_cache flush到binlog文件中,根据表名、主键和唯一键(如果有)生成hash值(writeset),保存到hash表中 判断这三个事务的writeset是否有冲突,如果没有冲突,则视为同组,如果有冲突,则视为不同组. 并把把组员编号以及组的编号写进binlog文件中 (不过一个组的事务个数也不是无限大,由参数binlog_transaction_dependency_history_size决定组内最多事务数) 3.然后做redo log和binlog的fsync 4.dump线程从binlog文件里把binlog event发送给从库 5.I/O线程接收到binlog event,写到relay log中 6.sql thread读取relay log,如果是同一个组的事务,则把事务分配到不同的worker线程去应用relay log. 不同组的事务,需要等到上一个组的事务全部执行完成,才能分配worker线程应用relay log. 老师我有几个问题想请教下: 1.在备库是单线程下,second_behind_master是通过计算T3-T1得到, 在多线程的情况下,是怎么计算出second_behind_master的值?用的是哪一个事务的时间戳? 2.多线程复制下,如果从库宕机了,是不是从库有一个记录表记录那些事务已经应用完成, 恢复的时候,只需要恢复未应用的事务. 3.binlog延迟sync的两个参数,是延迟已经flush未sync时间。意思是让事务组占用flush时间更长, 之后的事务有更多的时间,从binlog cache进入到flush队列,使得组员变多,起到从库并发的目的 因为我理解的是加入到组是在binlog cache flush到binlog文件之前做的,如果此时有事务正在flush, 未sync,则后面的事务必须等待。不知道理解得对不
某、人总结下多线程复制的流程,有不对之处请老师指出: 双1,配置为logical_clock,假设有三个事务并发执行也已经执行完成(都处于prepare阶段) 1.三个事务把redo log从redo log buffer写到fs page cache中 2.把binlog_cache flush到binlog文件中,最先进入flush队列的为leader, 其它两个事务为follower.把组员编号以及组的编号写进binlog文件中(三个事务为同一组). 3.三个事务的redo log做fsync,binlog做fsync. 4.dump线程从binlog文件里把binlog event发送给从库 5.I/O线程接收到binlog event,写到relay log中 6.sql thread读取relay log,判断出这三个事务是处于同一个组, 则把这三个事务的event打包发送给三个空闲的worker线程(如果有)并执行。 配置为writeset的多线程复制流程: 1.三个事务把redo log从redo log buffer写到fs page cache中 2.把binlog_cache flush到binlog文件中,根据表名、主键和唯一键(如果有)生成hash值(writeset),保存到hash表中 判断这三个事务的writeset是否有冲突,如果没有冲突,则视为同组,如果有冲突,则视为不同组. 并把把组员编号以及组的编号写进binlog文件中 (不过一个组的事务个数也不是无限大,由参数binlog_transaction_dependency_history_size决定组内最多事务数) 3.然后做redo log和binlog的fsync 4.dump线程从binlog文件里把binlog event发送给从库 5.I/O线程接收到binlog event,写到relay log中 6.sql thread读取relay log,如果是同一个组的事务,则把事务分配到不同的worker线程去应用relay log. 不同组的事务,需要等到上一个组的事务全部执行完成,才能分配worker线程应用relay log. 老师我有几个问题想请教下: 1.在备库是单线程下,second_behind_master是通过计算T3-T1得到, 在多线程的情况下,是怎么计算出second_behind_master的值?用的是哪一个事务的时间戳? 2.多线程复制下,如果从库宕机了,是不是从库有一个记录表记录那些事务已经应用完成, 恢复的时候,只需要恢复未应用的事务. 3.binlog延迟sync的两个参数,是延迟已经flush未sync时间。意思是让事务组占用flush时间更长, 之后的事务有更多的时间,从binlog cache进入到flush队列,使得组员变多,起到从库并发的目的 因为我理解的是加入到组是在binlog cache flush到binlog文件之前做的,如果此时有事务正在flush, 未sync,则后面的事务必须等待。不知道理解得对不作者回复: 上面的描述部分,writeset的多线程复制流程里面,这段需要修改下: 『2.把binlog_cache flush到binlog文件中,根据表名、主键和唯一键(如果有)生成hash值(writeset),保存到hash表中 【判断这三个事务的writeset是否有冲突,如果没有冲突,则视为同组,如果有冲突,则视为不同组. 并把把组员编号以及组的编号写进binlog文件中】』 上面中括号这段要去掉, 判断writeset之间是否可以并行这个逻辑,是在备库的coordinator线程做的。 ---- 1. 在多线程并发的时候,Seconds_behind_master很不准,后面会介绍别的判断方法; 2. 是的,备库有记录,就是show slave status 里面的Relay_Log_File 和 Relay_Log_Pos 这两个值表示的,好问题 3. ”加入到组是在binlog cache flush到binlog文件之前做的,如果此时有事务正在flush,未sync,则后面的事务必须等待“ 这句话是对的,但是我没看出这个跟前面提的两个延迟参数作用的关系^_^
2019-01-13629 linqw学习完这篇写下自己的理解,老师有空帮忙看下哦,备库一般会延迟分钟级别,比如主库压力比较大的时候,备库有可能会延迟小时级别,为此mysql官方提供了多种多线程复制策略 1、5.6基于库的多线程复制策略,使用hash数据库名作为key,value为多少个事务修改此数据库,使用hash来分配多线程,如果一个新事务加入进来,如果有冲突的hash,分配给此线程,如果没有冲突分配给空闲的线程,感觉实现的思路使用队列+线程池,如果线程池中没有空闲的线程,就在队列中增加事务,如果队列满,分发器阻塞,不解析binlog,分发器是生产者,线程池是消费者,基于库的多线程复制有如下优点①构造 hash 值的时候很快,只需要库名;线程的hash项也很少②binlog不需要强制指定row,statement也可以拿到库名。缺点:①如果只有一个库单线程复制,可以将其热点表分布到多个库中(不推荐使用),如果多个库的热点程度不同也会使其单线程复制。 2、基于表的多线程复制(非官方,老师实现),hash数据库名+表名作为key,value为多少个事务修改此数据表,同一个事务的多张表,在同一个线程进行处理,防止违反原子性,优点对同一个库多个热点表可以同时复制,多表负载效果很好,如果碰到热点表,比如所有的更新事务都会涉及到某一个表的时候,会使用单线程复制。 3、基于行的多线程复制,key必须是“库名 + 表名 + 唯一键的值“也需考虑唯一主键,防止唯一主键冲突(cpu的多线程调度,顺序不固定),value为修改前后key的次数,约束①表必须有主键②不能有外键③binlog格式row(表复制也一样)缺点:①大事务耗cpu②hash项多。优化可以设置阈值,如果事务修改的行大于特定值,使用单线程复制(老师自己实现)。mysql官网基于行的多线程复制,表示的是对于事务涉及更新的每一行,计算出每一行的 hash保存在writeset中,优点,①是有mysql主库写入binlog中,不需要解析 binlog 内容(event 里的行数据),节省计算量②binlog格式没要求,可以使用statement③无需扫描整个事务的binlog省内存,mysql5.7.22的多线程复制实现方式。 4、mysql5.7的多线程复制实现方式,借助于处于redo prepare到commit状态下的事务可以并行,因为执行器找引擎拿数据时,事务如果锁冲突会阻塞,无法到写redo log这一步,可以使用binlog故意延迟fsync,防止频繁写磁盘操作,不会丢失数据(redo prepar+完整的binlog事务才能提交,否则回滚),使其在备库多线程复制,主备延迟低,,但是这样有一点不好,语句的响应时间变长,感觉mysql官网故意延迟redo的fsync,在binlog write的时候(因为事务的binlog要写完整,时间较长),使其能批量提交,减少iops,感觉很巧妙
linqw学习完这篇写下自己的理解,老师有空帮忙看下哦,备库一般会延迟分钟级别,比如主库压力比较大的时候,备库有可能会延迟小时级别,为此mysql官方提供了多种多线程复制策略 1、5.6基于库的多线程复制策略,使用hash数据库名作为key,value为多少个事务修改此数据库,使用hash来分配多线程,如果一个新事务加入进来,如果有冲突的hash,分配给此线程,如果没有冲突分配给空闲的线程,感觉实现的思路使用队列+线程池,如果线程池中没有空闲的线程,就在队列中增加事务,如果队列满,分发器阻塞,不解析binlog,分发器是生产者,线程池是消费者,基于库的多线程复制有如下优点①构造 hash 值的时候很快,只需要库名;线程的hash项也很少②binlog不需要强制指定row,statement也可以拿到库名。缺点:①如果只有一个库单线程复制,可以将其热点表分布到多个库中(不推荐使用),如果多个库的热点程度不同也会使其单线程复制。 2、基于表的多线程复制(非官方,老师实现),hash数据库名+表名作为key,value为多少个事务修改此数据表,同一个事务的多张表,在同一个线程进行处理,防止违反原子性,优点对同一个库多个热点表可以同时复制,多表负载效果很好,如果碰到热点表,比如所有的更新事务都会涉及到某一个表的时候,会使用单线程复制。 3、基于行的多线程复制,key必须是“库名 + 表名 + 唯一键的值“也需考虑唯一主键,防止唯一主键冲突(cpu的多线程调度,顺序不固定),value为修改前后key的次数,约束①表必须有主键②不能有外键③binlog格式row(表复制也一样)缺点:①大事务耗cpu②hash项多。优化可以设置阈值,如果事务修改的行大于特定值,使用单线程复制(老师自己实现)。mysql官网基于行的多线程复制,表示的是对于事务涉及更新的每一行,计算出每一行的 hash保存在writeset中,优点,①是有mysql主库写入binlog中,不需要解析 binlog 内容(event 里的行数据),节省计算量②binlog格式没要求,可以使用statement③无需扫描整个事务的binlog省内存,mysql5.7.22的多线程复制实现方式。 4、mysql5.7的多线程复制实现方式,借助于处于redo prepare到commit状态下的事务可以并行,因为执行器找引擎拿数据时,事务如果锁冲突会阻塞,无法到写redo log这一步,可以使用binlog故意延迟fsync,防止频繁写磁盘操作,不会丢失数据(redo prepar+完整的binlog事务才能提交,否则回滚),使其在备库多线程复制,主备延迟低,,但是这样有一点不好,语句的响应时间变长,感觉mysql官网故意延迟redo的fsync,在binlog write的时候(因为事务的binlog要写完整,时间较长),使其能批量提交,减少iops,感觉很巧妙作者回复: 👍
2019-03-1020 Mr.Strive.Z.H.L老师您好: 关于COMMIT_ORDER的并行复制方案,从库根据 commit_id来判断“处于prepare和commit状态的事务”。这里我有个很大的疑惑:commit_id是什么时候加入到binlog的,又是在什么时候递增的?? ( 对于我这个问题的进一步解释: 既然commit_id是要被写入到binlog的,那么commit_id毫无疑问就是在write binlog阶段写入的。 我们知道redolog是组提交的,如果只是按照redolog的组提交方式生成commit_id,那么这个commit_id包含的并行事务数量并不够多!因为在binlog write阶段,又有事务进入到redolog prepare阶段,他们之间的commit_id是不一样的,但是他们是可以并行的。 所以commit_id什么时候递增?这个是非常关键的,我也很疑惑,commit_id到底是根据什么条件递增的?? )
Mr.Strive.Z.H.L老师您好: 关于COMMIT_ORDER的并行复制方案,从库根据 commit_id来判断“处于prepare和commit状态的事务”。这里我有个很大的疑惑:commit_id是什么时候加入到binlog的,又是在什么时候递增的?? ( 对于我这个问题的进一步解释: 既然commit_id是要被写入到binlog的,那么commit_id毫无疑问就是在write binlog阶段写入的。 我们知道redolog是组提交的,如果只是按照redolog的组提交方式生成commit_id,那么这个commit_id包含的并行事务数量并不够多!因为在binlog write阶段,又有事务进入到redolog prepare阶段,他们之间的commit_id是不一样的,但是他们是可以并行的。 所以commit_id什么时候递增?这个是非常关键的,我也很疑惑,commit_id到底是根据什么条件递增的?? )作者回复: 可以这么理解,每个事务都有两个数字表示它在执行提交阶段的时间范围, 构成区间(c1, c2). 如果两个事务的区间有交集,就是可以并行的。 这里c1是事务启动的时候,当前系统里最大的commit_id; 一个事务提交的时候,commit_id+1.
2019-01-17414 J!同时处于 prepare 状态的事务,在备库执行时是可以并行.复制的,是这个prepare 就可以生成了改组的commited Id吗 极客时间版权所有: https://time.geekbang.org/column/article/77083
J!同时处于 prepare 状态的事务,在备库执行时是可以并行.复制的,是这个prepare 就可以生成了改组的commited Id吗 极客时间版权所有: https://time.geekbang.org/column/article/77083作者回复: 进入prepare 的时候就给这个事务分配 commitid,这个commitid就是当前系统最大的一个commitid
2019-02-019

