

38 | 都说InnoDB好,那还要不要使用Memory引擎?

该思维导图由 AI 生成,仅供参考
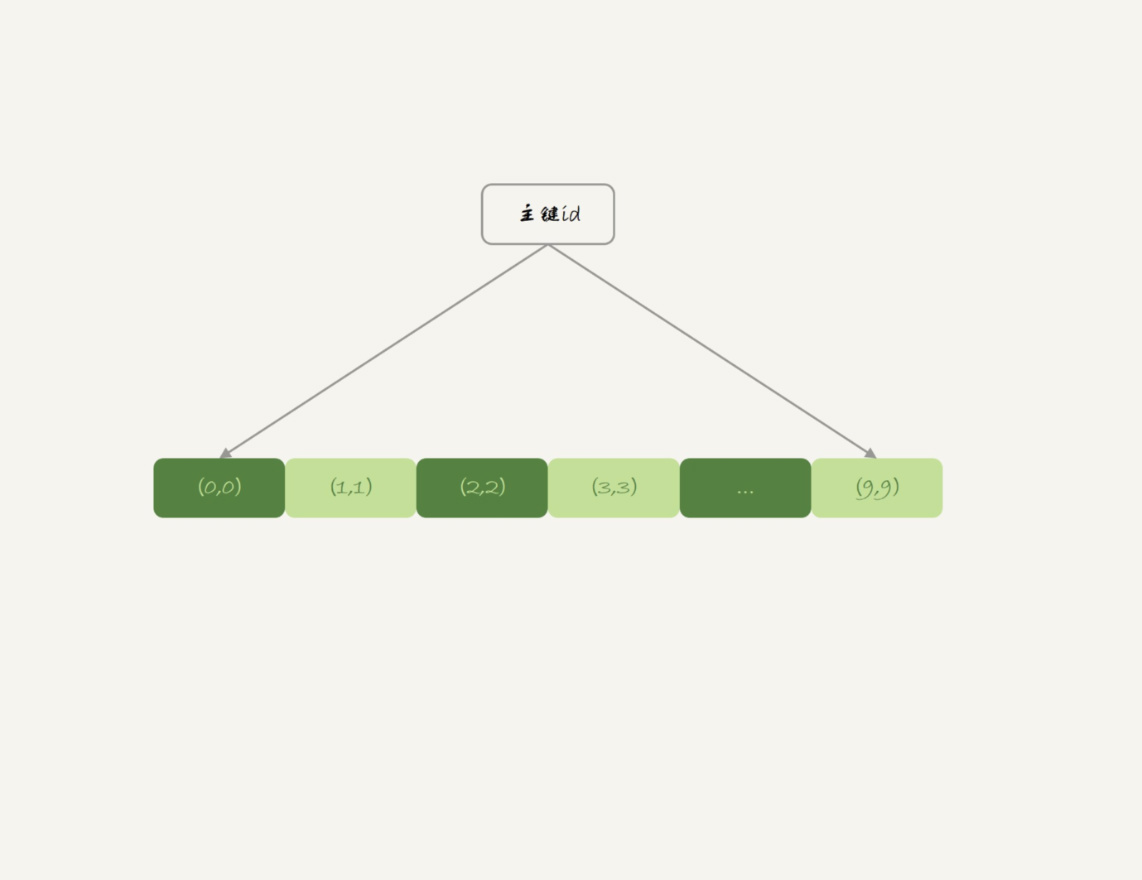
内存表的数据组织结构
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

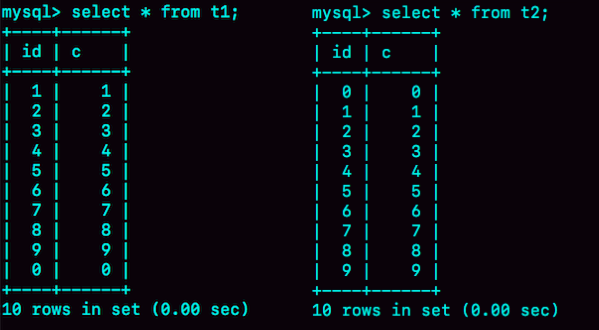
内存引擎和InnoDB引擎在数据组织方式上存在显著差异。InnoDB引擎将数据存储在主键索引上,而内存引擎则将数据和索引分开存放。这导致了内存表的数据是按照写入顺序存放的,而InnoDB表的数据总是有序存放的。此外,内存表不支持行锁,只支持表锁,这会影响并发访问的性能。尽管内存引擎速度快且支持hash索引,但在生产环境中使用时需要注意锁粒度问题和数据持久化问题。因此,尽管内存引擎有其优势,但在生产环境中的使用需要谨慎考虑。 在高可用架构下,内存表的特性可能导致主备同步停止,甚至主库的内存表数据被意外删除。因此,普通内存表并不适合在生产环境中使用,而推荐使用InnoDB表代替。然而,内存临时表在数据量可控的情况下可以考虑使用,因为它不会受到主备同步和数据持久化的影响。 总的来说,内存表的特性决定了它并不适合作为普通数据表在生产环境中使用。在实际应用中,需要根据具体场景和需求来选择合适的存储引擎,以确保数据安全和性能优化。 文章还提出了一个问题,即如何在业务场景暂时不允许修改引擎的情况下,通过自动化逻辑避免主备同步停止。这个问题需要进一步思考和讨论。 综上所述,本文从内存引擎和InnoDB引擎的特性出发,探讨了内存表在生产环境中的适用性,并提出了内存临时表的使用建议,为读者提供了对存储引擎选择和优化的思路和建议。
《MySQL 实战 45 讲》,新⼈⾸单¥68

全部留言(34)
- 最新
- 精选
 放
放 老师新年快乐!过年都不忘给我们传授知识!
老师新年快乐!过年都不忘给我们传授知识!作者回复: 新年快乐🤝
2019-02-0826 Long老师新年好 :-) 刚好遇到一个问题。 本来准备更新到,一个查询是怎么运行的里面的,看到这篇更新文章,就写在这吧,希望老师帮忙解答。 关于这个系统memory引擎表:information_schema.tables 相关信息如下 (1)Verison: MySQL 5.6.26 (2)数据量table_schema = abc的有接近4W的表,整个实例有接近10W的表。(默认innodb引擎) (3)mysql.user和mysql.db的数据量都是100-200的行数,MyISAM引擎。 (4)默认事务隔离级别RC 在运行查询语句1的时候:select * from information_schema.tables where table_schema = 'abc'; 状态一直是check permission,opening tables,其他线程需要打开的表在opend tables里面被刷掉的,会显示在opening tables,可能需要小几秒后基本恢复正常。 但是如果在运行查询语句2:select count(1) from information_schema.tables where table_schema = 'abc'; 这个时候语句2本身在profiling看长期处于check permission状态,其他线程就会出现阻塞现象,大部分卡在了opening tables,小部分closing tables。我测试下了,当个表查询的时候check permission大概也就是0.0005s左右的时间,4W个表理论良好状态应该是几十秒的事情。 但是语句1可能需要5-10分钟,语句2需要5分钟。 3个问题,请老师抽空看下: (1)information_schema.tables的组成方式,是我每次查询的时候从数据字典以及data目录下的文件中实时去读的吗? (2)语句1和语句2在运行的时候的过程分别是怎样的,特别是语句2。 (3)语句2为什么会出现大量阻塞其他事务,其他事务都卡在opening tables的状态。 PS: 最后根据audit log分析来看,语句实际上是MySQL的一个客户端Toad发起的,当使用Toad的object explorer的界面来查询表,或者设置connection的时候指定的的default schema是大域的时候就会run这个语句:(table_schema改成了abc,其他都是原样) SELECT COUNT(1) FROM information_schema.tables WHERE table_schema = 'abc' AND table_type != 'VIEW'; 再次感谢!
Long老师新年好 :-) 刚好遇到一个问题。 本来准备更新到,一个查询是怎么运行的里面的,看到这篇更新文章,就写在这吧,希望老师帮忙解答。 关于这个系统memory引擎表:information_schema.tables 相关信息如下 (1)Verison: MySQL 5.6.26 (2)数据量table_schema = abc的有接近4W的表,整个实例有接近10W的表。(默认innodb引擎) (3)mysql.user和mysql.db的数据量都是100-200的行数,MyISAM引擎。 (4)默认事务隔离级别RC 在运行查询语句1的时候:select * from information_schema.tables where table_schema = 'abc'; 状态一直是check permission,opening tables,其他线程需要打开的表在opend tables里面被刷掉的,会显示在opening tables,可能需要小几秒后基本恢复正常。 但是如果在运行查询语句2:select count(1) from information_schema.tables where table_schema = 'abc'; 这个时候语句2本身在profiling看长期处于check permission状态,其他线程就会出现阻塞现象,大部分卡在了opening tables,小部分closing tables。我测试下了,当个表查询的时候check permission大概也就是0.0005s左右的时间,4W个表理论良好状态应该是几十秒的事情。 但是语句1可能需要5-10分钟,语句2需要5分钟。 3个问题,请老师抽空看下: (1)information_schema.tables的组成方式,是我每次查询的时候从数据字典以及data目录下的文件中实时去读的吗? (2)语句1和语句2在运行的时候的过程分别是怎样的,特别是语句2。 (3)语句2为什么会出现大量阻塞其他事务,其他事务都卡在opening tables的状态。 PS: 最后根据audit log分析来看,语句实际上是MySQL的一个客户端Toad发起的,当使用Toad的object explorer的界面来查询表,或者设置connection的时候指定的的default schema是大域的时候就会run这个语句:(table_schema改成了abc,其他都是原样) SELECT COUNT(1) FROM information_schema.tables WHERE table_schema = 'abc' AND table_type != 'VIEW'; 再次感谢!作者回复: 1&2 查询information_schema.tables的时候,会把所有的表都访问到一次,这里不止是4w个表,而是这个实例上所有的表,也就是10万 3. 因为系统一般设置的table_definition_cache 都不会太大,你要打开10万张表,就只能轮流打开,然后轮流从table_definition_cache里面淘汰。这样就跟其他查询在table_definition_cache这个结构里出现了互相等待资源的情况。 嗯,这个其实就是我不建议用界面工具的原因之一 不好意思,你这个问题这么迟才回复你😆
2019-02-0821 salt新年好! 课后作业:在备库配置跳过该内存表的主从同步。 有一个问题一直困扰着我:SSD以及云主机的广泛运用,像Innodb这种使用WAL技术似乎并不能发挥最大性能(我的理解:基于SSD的WAL更多的只是起到队列一样削峰填谷的作用)。对于一些数据量不是特别大,但读写频繁的应用(比如点赞、积分),有没有更好的引擎推荐。
salt新年好! 课后作业:在备库配置跳过该内存表的主从同步。 有一个问题一直困扰着我:SSD以及云主机的广泛运用,像Innodb这种使用WAL技术似乎并不能发挥最大性能(我的理解:基于SSD的WAL更多的只是起到队列一样削峰填谷的作用)。对于一些数据量不是特别大,但读写频繁的应用(比如点赞、积分),有没有更好的引擎推荐。作者回复: 即使是SSD,顺序写也比随机写快些的。 不过确实没有机械盘那么明显。
2019-02-08321 往事随风,顺其自然为什么memory 引擎中数据按照数组单独存储,0索引对应的数据怎么放到数组的最后
往事随风,顺其自然为什么memory 引擎中数据按照数组单独存储,0索引对应的数据怎么放到数组的最后作者回复: 这就是堆组织表的数据存放方式
2019-02-09317 skyoo重启前 my.cnf 添加 skip-slave-errors 忽略 内存表引起的主从异常导致复制失败
skyoo重启前 my.cnf 添加 skip-slave-errors 忽略 内存表引起的主从异常导致复制失败作者回复: 嗯,这个也是可以的。不过也会放过其他引擎表的主备不一致的报错哈
2019-02-1115 llx1、如果临时表读数据的次数很少(比如只读一次),是不是建临时表时不创建索引效果很更好? 2、engine=memory 如果遇到范围查找,在使用哈希索引时应该不会使用索引吧
llx1、如果临时表读数据的次数很少(比如只读一次),是不是建临时表时不创建索引效果很更好? 2、engine=memory 如果遇到范围查找,在使用哈希索引时应该不会使用索引吧作者回复: 1. 取决于对临时表的访问模式哦,如果是需要用到索引查找,还是要创建的。如果创建的临时表只是用于全表扫描,就可以不创建索引; 2. 是的,如果明确要用范围查找,就得创建b-tree索引
2019-02-1112 杜嘉嘉我的认识里,有一点不是很清楚。memory这个存储引擎,最大的特性应该是把数据存到内存。但是innodb也可以把数据存到内存,不但可以存到内存(innodb buffer size),还可以进行持久化。这样一对比,我感觉memory的优势更没有了。不知道我讲的对不对
杜嘉嘉我的认识里,有一点不是很清楚。memory这个存储引擎,最大的特性应该是把数据存到内存。但是innodb也可以把数据存到内存,不但可以存到内存(innodb buffer size),还可以进行持久化。这样一对比,我感觉memory的优势更没有了。不知道我讲的对不对作者回复: 是,如我们文中说的,不建议使用普通内存表了哈
2019-02-1011- 晚风·和煦老师,内存表就是使用memory引擎创建的表吗?😂
作者回复: 对
2020-01-169  陈扬鸿老师你好,今天生产上出碰到一个解决不了的问题,php的yii框架,使用show full processlist 查看 全是如下语句有100多条 SELECT kcu.constraint_name, kcu.column_name, kcu.referenced_table_name, kcu.referenced_column_name FROM information_schema.referential_constraints AS rc JOIN information_schema.key_column_usage AS kcu ON ( kcu.constraint_catalog = rc.constraint_catalog OR (kcu.constraint_catalog IS NULL AND rc.constraint_catalog IS NULL) ) AND kcu.constraint_schema = rc.constraint_schema AND kcu.constraint_name = rc.constraint_name WHERE rc.constraint_schema = database() AND kcu.table_schema = database() AND rc.table_name = 't1' AND kcu.table_name = 't1' 这个可以优化吗 这个库是数据字典的 现在数据库无法对外提供服务 请老师指教!
陈扬鸿老师你好,今天生产上出碰到一个解决不了的问题,php的yii框架,使用show full processlist 查看 全是如下语句有100多条 SELECT kcu.constraint_name, kcu.column_name, kcu.referenced_table_name, kcu.referenced_column_name FROM information_schema.referential_constraints AS rc JOIN information_schema.key_column_usage AS kcu ON ( kcu.constraint_catalog = rc.constraint_catalog OR (kcu.constraint_catalog IS NULL AND rc.constraint_catalog IS NULL) ) AND kcu.constraint_schema = rc.constraint_schema AND kcu.constraint_name = rc.constraint_name WHERE rc.constraint_schema = database() AND kcu.table_schema = database() AND rc.table_name = 't1' AND kcu.table_name = 't1' 这个可以优化吗 这个库是数据字典的 现在数据库无法对外提供服务 请老师指教!作者回复: 你看看能不能把短连接改成长连接 还有,这个语句应该是没用的,看看能不能通过配置框架参数,来避免执行这个语句
2019-03-0626- 夹心面包我们线上就有一个因为内存表导致的主从同步异常的例子,我的做法是先跳过这个表的同步,然后开发进行改造,取消这张表的作用
作者回复: 嗯嗯,联系开发改造是对的😆
2019-02-115

