

27|DALL-E 3技术探秘(二):从unCLIP到缝合怪方案

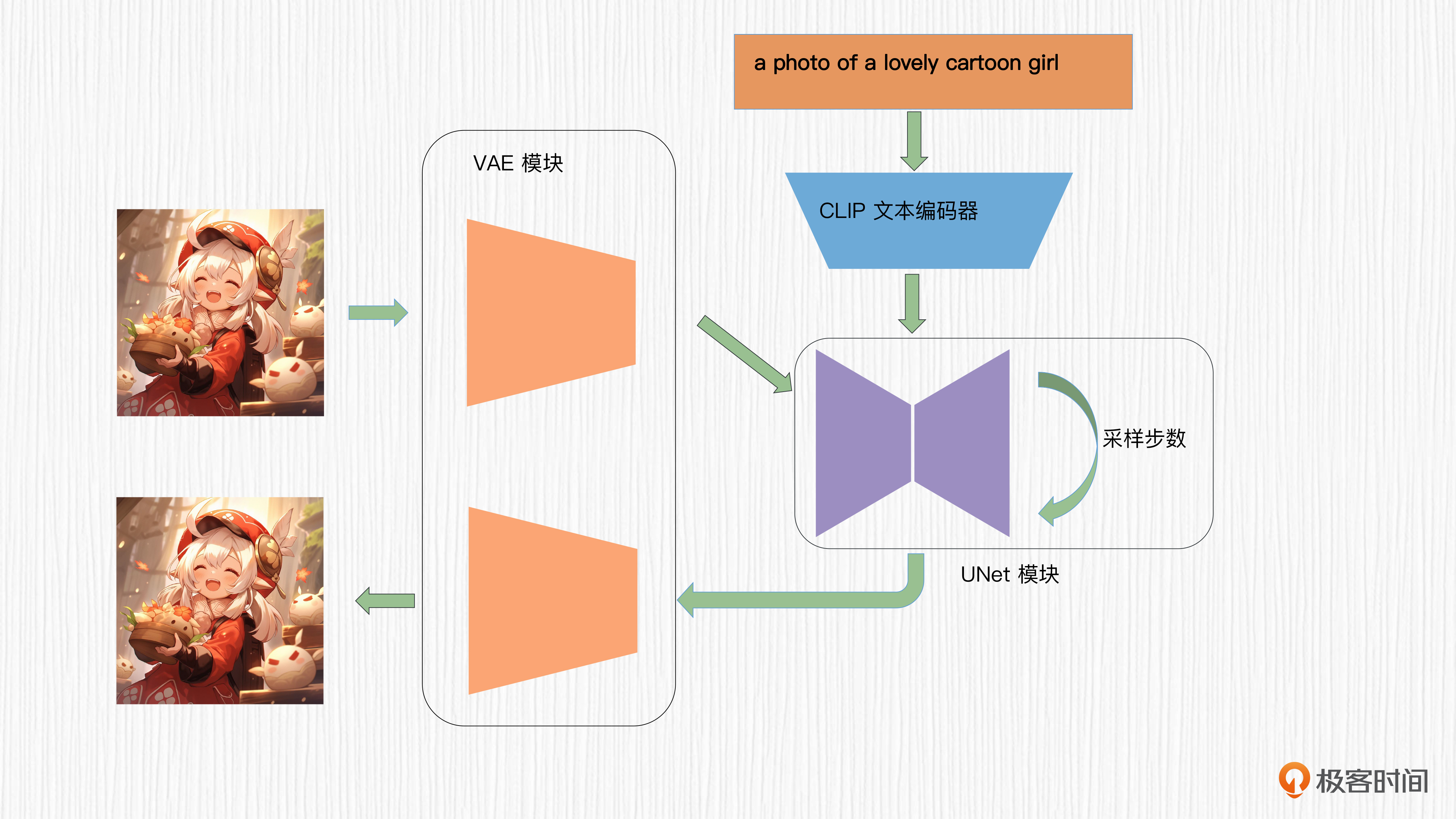
加入 VAE 结构
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

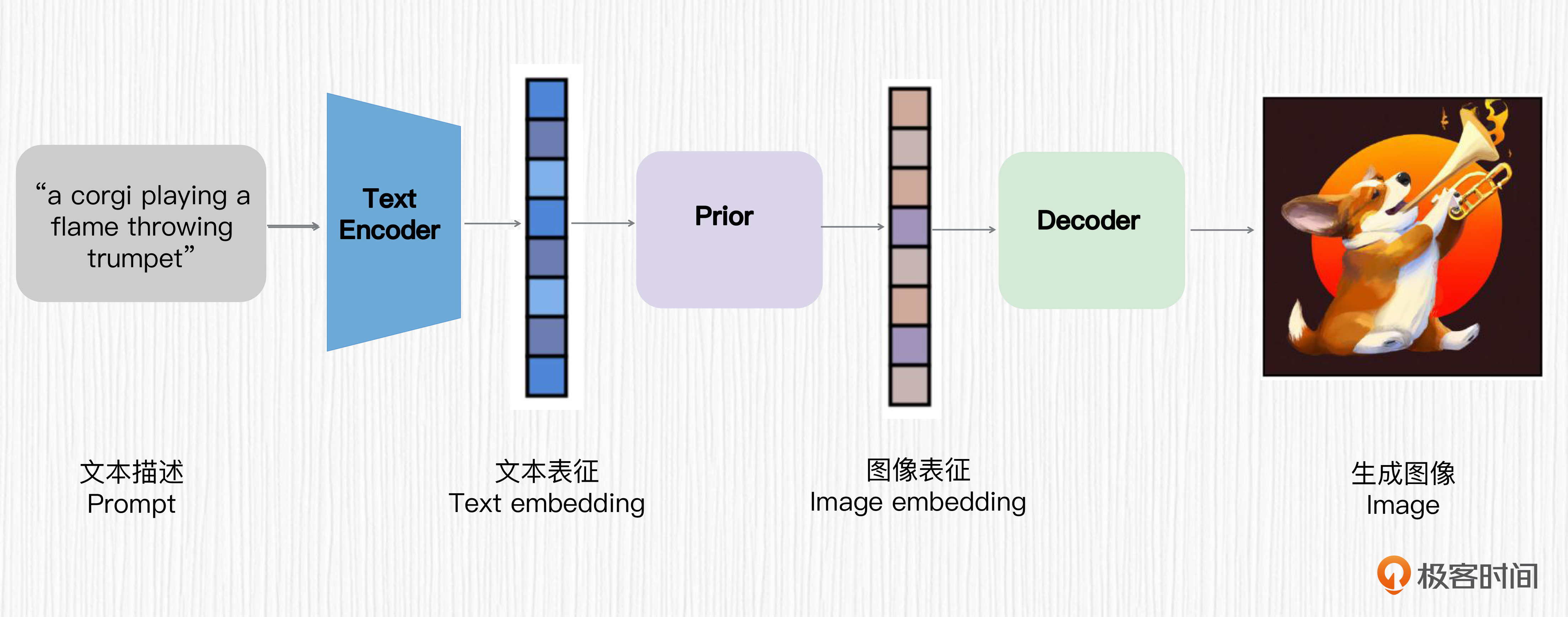
DALL-E 3技术方案的探索展现了其与DALL-E 2的巨大改变。文章首先介绍了DALL-E 3的模型结构,其中加入了VAE结构,通过对训练图像进行8倍下采样,提升了扩散模型的训练效率。其生成图片的分辨率是不固定的,并且可能采用了类似DALL-E 2、Imagen等方案的扩散模型超分方法。此外,DALL-E 3还将CLIP文本编码器换成了T5-XXL模型,并通过改进时间步编码的作用机制,提升了对时间步的处理效率。这些技术特点展现了DALL-E 3在模型设计和训练数据使用上的创新,为读者提供了对DALL-E 3技术方案的深入了解。文章还介绍了DALL-E 3中使用的GroupNorm的技术细节,以及扩散模型解码器的结构和作用。同时,文章也指出了DALL-E 3的局限性,包括在处理关于定位和空间相关的prompt、特定动植物种类、图中写文字等方面偶有翻车,并且失去了图像变体的能力。总的来说,DALL-E 3在文生图任务上表现出众,为后来者提供了诸多启发。
《AI 绘画核心技术与实战》,新⼈⾸单¥59

全部留言(3)
- 最新
- 精选
 Toni大语言模型现在本质上还是“语言接龙”或“语言填空”。这个“本领”是通过学习海量数据得来的,学习的并非是真正的“语意”,而是词与词之间的“习惯用法”,学会的是自然语言应用中的某种概率统计分布,通俗地讲就是学会了“大家都怎么说”。 这种学习过程特别适合训练英法德这样的拼音文字大语言模型。 中文和其它语言一样也有“大家都这么说”的统计规律,但做为象形文字的杰出代表,她还有一个特殊性,其表现在具有固定的偏旁部首,这些偏旁部首具有明显的分类特征,比如将与金属有关的东西都用带金属旁的字来表达,等等,自带特别容易识别的归类特征。 处理中文大语言模型时如果通过卷积运算提取文字特征,即偏旁部首,间架结构,进而学习到单词的真正语意。用一篇文章来解释一个字的语料还是很丰富的,用这样的语料训练模型更像是在训练模型理解字义。中文核心词汇,具有独立语意的有2000-4000字(大概估的),掌握这些知识的中文大语言模型一定更具优势,遣词造句出的文章水平会更高。 南柯老师: 有什么模型在做这样的事吗?
Toni大语言模型现在本质上还是“语言接龙”或“语言填空”。这个“本领”是通过学习海量数据得来的,学习的并非是真正的“语意”,而是词与词之间的“习惯用法”,学会的是自然语言应用中的某种概率统计分布,通俗地讲就是学会了“大家都怎么说”。 这种学习过程特别适合训练英法德这样的拼音文字大语言模型。 中文和其它语言一样也有“大家都这么说”的统计规律,但做为象形文字的杰出代表,她还有一个特殊性,其表现在具有固定的偏旁部首,这些偏旁部首具有明显的分类特征,比如将与金属有关的东西都用带金属旁的字来表达,等等,自带特别容易识别的归类特征。 处理中文大语言模型时如果通过卷积运算提取文字特征,即偏旁部首,间架结构,进而学习到单词的真正语意。用一篇文章来解释一个字的语料还是很丰富的,用这样的语料训练模型更像是在训练模型理解字义。中文核心词汇,具有独立语意的有2000-4000字(大概估的),掌握这些知识的中文大语言模型一定更具优势,遣词造句出的文章水平会更高。 南柯老师: 有什么模型在做这样的事吗?编辑回复: 这里把老师课程群回应过的答案再发一下,供其他同学参考。 这个想法很有意思。目前GPT这类模型,主要在学习词汇和短语在不同语境中的使用频率和搭配规律,而不是深入到每个词汇的本质意义上。 无论对于中文还是英文,都是通过分词的方式来变成token ID,然后通过查字典的方式转换为特征向量,作为大语言模型的输入。比如“大家晚上好”可以分词为“大家”、“晚上”、“好”,token ID就是三个数字。从这个意义上说,大语言模型感知不到英文和中文的区别。 至于你说的通过偏旁部首+卷积运算,我理解类似于多模态大模型,将这些文字以图片的形式作为输入,然后促进大语言模型的学习。这 个点可以这样做,比如“南辕北辙”渲染成一张图片,然后prompt问“图中的成语是什么意思”,预测目标是对这个成语的解释。用这种方式训练的模型,对于模型理解中文会有帮助。 据我所知,在多模态大模型领域还没有人这样做。至于怎么实现这个过程,则需要补充ViT、自回归模型方面的知识。 我还问了问GPT,在文字识别领域(OCR),确实有人做过类似的事情,虽然不属于大语言模型的范畴,但证明了中文特殊结构对于“学习汉字”这个问题是有帮助的。
2023-11-14归属地:瑞士- Toni目前领衔的AI绘画模型 Midjourny5.2, SDXL1.0, DALL-E3 各有各的优势,这一现象本身就表明无论哪个模型都有巨大的发展空间。AI模型的好坏主要取决于三大要素,1. 优秀的基础大语言模型,2. 优质的训练素材,3. 与任务匹配的合适算法和经过反复调优的超参数。这与人类的学习过程类似,1. 广博的知识和经验的积累,2. 读优秀经典的著作,3. 正确的学习方法和有效的知识图谱建立。 DALL-E3 依托优质大语言模型的"理解能力",不满足于现有训练资料的品质,提出质疑并力图改进,在模型训练过程中尝试不同的超参量并发现问题直至给出最优解,令人印象深刻。模型改进的背后是大量的试错,调制,经验模型的必由之路。敬佩所有付出努力的尝试。2023-11-12归属地:瑞士1
 进化论先点赞,在观看2023-11-09归属地:北京1
进化论先点赞,在观看2023-11-09归属地:北京1

