

09|采样器:龟兔赛跑,如何选择更好更快的采样器?

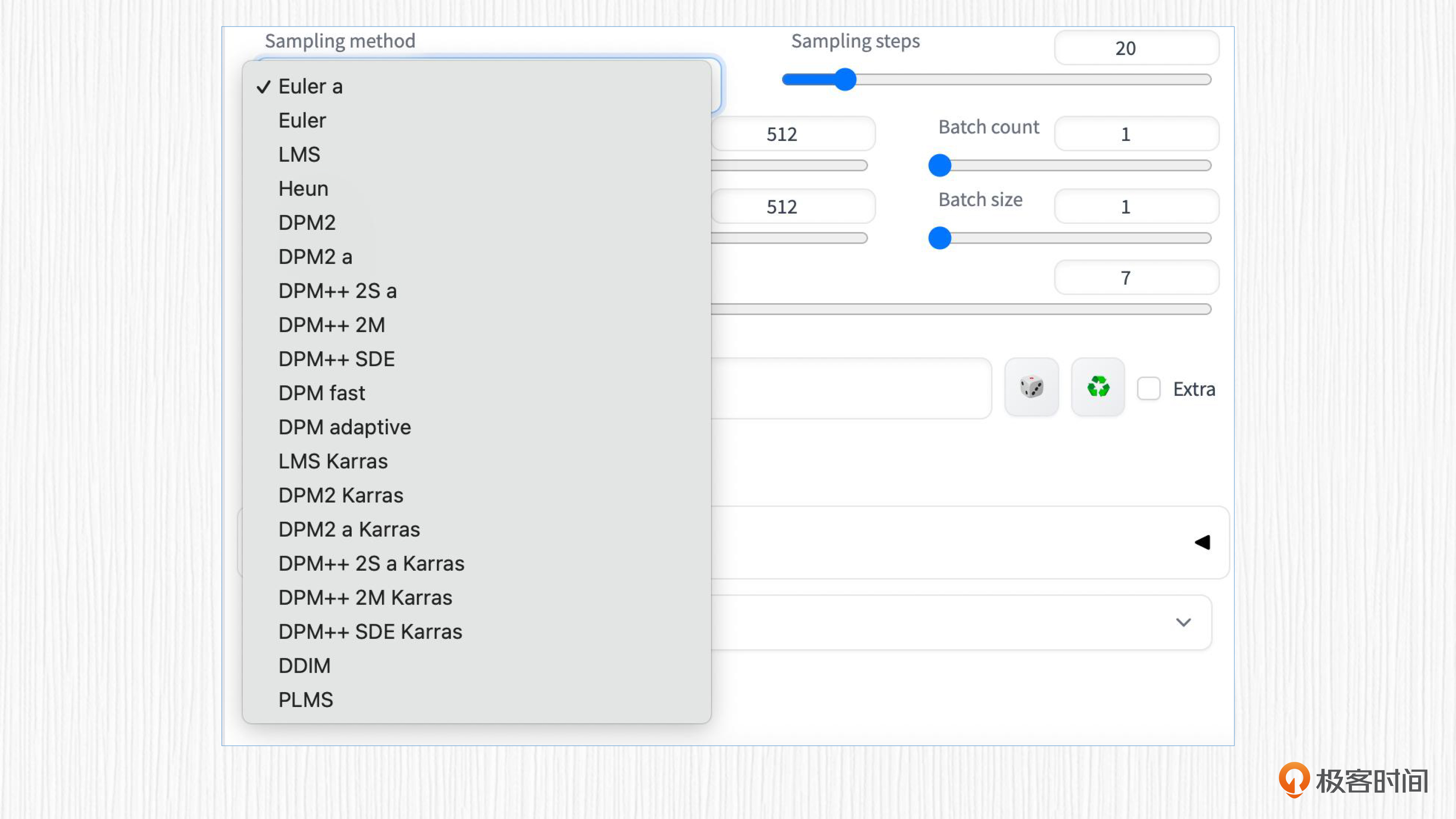

采样器基本原理
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

本文介绍了在AI绘画中采样器的重要作用以及不同类型采样器的特性和应用。文章首先介绍了采样器的基本原理和工作模式,以及UNet模型和采样器在生成清晰图像中的协同作用。随后详细对比了不同采样器的特点和应用场景,包括常微分方程求解器、祖先采样器和基于Karras论文的采样器策略。针对不同需求,提出了选择合适采样器的建议,涵盖了速度、图像质量和个人偏好等方面。最后,鼓励读者分享在使用WebUI过程中选择采样器的心得和讨论,以促进更好地消化课程内容。整体而言,本文通过深入探讨不同采样器的特点和应用,帮助读者更好地理解和选择合适的采样器,从而提高绘图效率和图像质量。
《AI 绘画核心技术与实战》,新⼈⾸单¥59

全部留言(4)
- 最新
- 精选

 石云升
石云升 如果采样器都差不多,为啥webuI有10几个这么多。除了老师总结的几个用法外,还有没有更具体的区别?我的理解是,应该是某个采集器解决不了某个场景的问题,才会有人去研发一个新的采集器。
如果采样器都差不多,为啥webuI有10几个这么多。除了老师总结的几个用法外,还有没有更具体的区别?我的理解是,应该是某个采集器解决不了某个场景的问题,才会有人去研发一个新的采集器。作者回复: 你好。我个人的看法是,采样器研究的终极目标是希望采样过程又快又好。在不同的应用场景或数据类型下,采样器设计和性能确实会有所不同,只不过在我们简单prompt场景下的AI绘画任务上差别不明显。未来采样器方向,我觉得有两个方向需要继续研究:更少的采样步数(比如2-3步出图),这部分已经有一些论文了;处理特定的挑战,比如大数据、高维度、异常值等进行特殊设计。其中第二个方向上我和你的看法是一致的。
2023-08-04归属地:广东1 peter请教老师两个问题: Q1:那个1000步是怎么来的?经验值吗? Q2:假如我要写采样器的论文,可以从哪些方面推出新的采样器?
peter请教老师两个问题: Q1:那个1000步是怎么来的?经验值吗? Q2:假如我要写采样器的论文,可以从哪些方面推出新的采样器?作者回复: 你好。针对Q1,1000步是经验值,实际扩散模型训练过程中这个参数可以调整。针对Q2,我觉得关于采样器有两个方向需要继续研究:更少的采样步数(比如2-3步出图),这部分已经有一些论文了;处理特定的挑战,比如大数据、高维度、异常值等进行特殊设计(需要先分析已有采样器在复杂场景下的差异和优劣)。希望能帮助到你。
2023-08-04归属地:北京1 王大叶仔细观察你会发现,采样器与 UNet 模型的能力是不冲突的。这便解释了为什么在 WebUI 中我们使用同样的 AI 绘画模型,却可以任意选择采样器。 ---- 这里不太理解,为什么采样器和 Unet 模型的能力不冲突?老师可以稍微多解释一下吗?
王大叶仔细观察你会发现,采样器与 UNet 模型的能力是不冲突的。这便解释了为什么在 WebUI 中我们使用同样的 AI 绘画模型,却可以任意选择采样器。 ---- 这里不太理解,为什么采样器和 Unet 模型的能力不冲突?老师可以稍微多解释一下吗?作者回复: 你好。要彻底搞懂这个问题需要很多的数学知识。简言之,UNet模型预测的目标是一个符合高斯分布的噪声,从训练过程我们可以知道,这个噪声是我们随机生成的,也我们去噪要用的采样器无关。采样器本质上是我们预先设定一个噪声去除方案,比如30步去噪得到一张清晰图片。不同采样器背后的数学原理不同,但本质上,都是以时间步t、当前时间步t的带噪图像和UNet预测噪声值作为输入,按照预定的去噪方案去抹除一个高斯噪声。
2023-08-31归属地:北京 和某欢请教老师一个问题,文中说有些采样器是执行一步,内部间隔的时间步是50步。这里间隔的时间步是怎么得出的呢? 有没有间隔时间步是1000步的呢?只需要计算一次就可以出图
和某欢请教老师一个问题,文中说有些采样器是执行一步,内部间隔的时间步是50步。这里间隔的时间步是怎么得出的呢? 有没有间隔时间步是1000步的呢?只需要计算一次就可以出图作者回复: 你好。更快的采样器也是当前研究的热点方向。据我所知,当前有一些论文中提出过少于10步的采样算法,但实际应用并不多。1步出图是最终目标,也是理想形态。至于间隔步的计算,比如我们训练过程总的加噪步数是1000,推理的时候指定采样步数是20,那么相当于一次去除了1000/20=50步的噪声。希望能帮助到你。
2023-08-20归属地:四川

