

05 | 深入浅出索引(下)

该思维导图由 AI 生成,仅供参考
覆盖索引
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

本文深入探讨了MySQL索引相关的概念,包括覆盖索引、最左前缀原则和索引下推。覆盖索引能减少树的搜索次数,提升查询性能;最左前缀原则强调索引的复用能力,建议为高频请求创建联合索引;索引下推优化可减少回表次数,提高查询效率。通过具体案例和图示,文章深入浅出地解释了这些索引概念,为读者提供了宝贵的技术知识。同时,文章提出了一个问题,让读者思考和讨论。文章内容涵盖了数据库设计原则和技术优化手段,对于数据库从业者具有重要参考价值。
《MySQL 实战 45 讲》,新⼈⾸单¥68

全部留言(668)
- 最新
- 精选
 loCust置顶老师,有这么个问题 一张表两个字段id, uname,id主键,uname普通索引 SELECT * FROM test_like WHERE uname LIKE 'j'/ 'j%' / '%j'/ '%j%' 模糊查询like后面四种写法都可以用到uname的普通索引 添加一个age字段 like后面的'%j'/ '%j%' 这两种情况用不到索引 把select * 改为 select id / select uname / select id,uname like后面'j'/ 'j%' / '%j'/ '%j%' 这四种情况又都可以用到uname普通索引 建立uname,age的联合索引 模糊查询还是 LIKE 'j'/ 'j%' / '%j'/ '%j%'四种情况 其中select id / select uname / select id,uname 会用到uname的普通索引 select * 会用到uname,age的组合索引 看到好些文章会说模糊查询时以%开头不会用到索引,实践后发现结论跟文章描述的有出入。 看了索引的这两节内容对上面的各种情况有的可以解释通了,有的仍然有些模糊,想问下老师上面这些情况使用索引时为什么是这样的?
loCust置顶老师,有这么个问题 一张表两个字段id, uname,id主键,uname普通索引 SELECT * FROM test_like WHERE uname LIKE 'j'/ 'j%' / '%j'/ '%j%' 模糊查询like后面四种写法都可以用到uname的普通索引 添加一个age字段 like后面的'%j'/ '%j%' 这两种情况用不到索引 把select * 改为 select id / select uname / select id,uname like后面'j'/ 'j%' / '%j'/ '%j%' 这四种情况又都可以用到uname普通索引 建立uname,age的联合索引 模糊查询还是 LIKE 'j'/ 'j%' / '%j'/ '%j%'四种情况 其中select id / select uname / select id,uname 会用到uname的普通索引 select * 会用到uname,age的组合索引 看到好些文章会说模糊查询时以%开头不会用到索引,实践后发现结论跟文章描述的有出入。 看了索引的这两节内容对上面的各种情况有的可以解释通了,有的仍然有些模糊,想问下老师上面这些情况使用索引时为什么是这样的?作者回复: 好问题,这个是关于“用索引” 和 “用索引快速定位记录”的区别。 08 篇讲到这个问题了,周五关注一下。 简单回答:“用索引”有一种用法是 “顺序扫描索引”
2018-11-2865236 老北置顶背景: 我们现在有一张表,每天生成300W数据, 然后每天用delete xx where id = x 这样的方式来删除. 不用truncate是因为DBA说truncate会重建自适应哈希索引,可能对整个库性能有影响. 操作: 这个表的主键id是递增的. 当我执行 explain select min(id) from t 时,是走的全表扫描. 而且我目前在从库执行这个sql,直接就卡住了. 执行 explain select max(id) from t 时, 结果是 Select tables optimized away (目前最大id 5亿左右,实际数据量只有300W) 问题: 想问下老师 1. 为什么 min(id) 会是全表扫描呢? 是和存在大量的delete后未释放空间有关系吗? 2. 像这种业务场景,mysql怎么处理比较快速呢? 使用rename 表名有什么风险吗?
老北置顶背景: 我们现在有一张表,每天生成300W数据, 然后每天用delete xx where id = x 这样的方式来删除. 不用truncate是因为DBA说truncate会重建自适应哈希索引,可能对整个库性能有影响. 操作: 这个表的主键id是递增的. 当我执行 explain select min(id) from t 时,是走的全表扫描. 而且我目前在从库执行这个sql,直接就卡住了. 执行 explain select max(id) from t 时, 结果是 Select tables optimized away (目前最大id 5亿左右,实际数据量只有300W) 问题: 想问下老师 1. 为什么 min(id) 会是全表扫描呢? 是和存在大量的delete后未释放空间有关系吗? 2. 像这种业务场景,mysql怎么处理比较快速呢? 使用rename 表名有什么风险吗?作者回复: 额你们DBA可能对自适应哈希索引(AHI)有误解…有其他同学也在评论中有提到AHI,我答疑文章会安排说明。 看你的描述,最好就是rename 重建一个新的,然后找低峰期删掉旧的表。 还有你这么说,应该id就是这个表的自增主键了,正常即使删除也不会全表扫描。不过我现在怀疑可能删的事务有没提交的,导致MySQL 没法回收复用旧空间。(这个可以简单从文件大小判断) 不过总之,rename +新建表,上面这个问题也自动解决了😓
2018-11-2441122 发条橙子 。置顶老师, 因为正文不能无限细节和篇幅的缘故, 有些细节点没有说, 我也一直很困惑, 希望能帮忙解答下,辛苦了 1. 表的逻辑结构 ,表 —> 段 —> 段中存在数据段(leaf node segment) ,索引段( Non-leaf node segment),请问数据段就是主键索引的数据, 索引段就是二级索引的数据么 2. 建立的每个索引都有要维护一个数据段么 ?? 那么新插入一行值 , 岂不是每个索引段都会维护这个值 3. 索引的n阶表示n个数据页么。那是不是插入第一行数据树高1 ,就是一个数据页, 插入二三行,树高是二,那就是两个数据页,而且B+树只有leaf node存数据,所以父节点实际上有没有数据,但是占一个页 ,好浪费 , 是我理解有误么 4. 树高取决于数据页的大小么 , 这个不是很能理解 ,数据页为16k 。 那么树高不是一个定值了么,难道还和里面存数据的大小有关么 5. 查询数据的时候,大致的流程细化来说 ,我这么理解对么 。 通过优化器到表里的数据段/索引段取数据 ,数据是按照段->区->页维度去取 , 取完后先放到数据缓冲池中,再通过二分法查询叶结点的有序链表数组找到行数据返回给用户 。 当数据量大的时候,会存在不同的区,取范围值的时候会到不同的区取页的数据返回用户。 这块知识有点比较难理解,看书和一些文章的时候也比较晦涩,希望老师能解答下,感觉这块啃不透 是不是索引设计起来就比较吃力
发条橙子 。置顶老师, 因为正文不能无限细节和篇幅的缘故, 有些细节点没有说, 我也一直很困惑, 希望能帮忙解答下,辛苦了 1. 表的逻辑结构 ,表 —> 段 —> 段中存在数据段(leaf node segment) ,索引段( Non-leaf node segment),请问数据段就是主键索引的数据, 索引段就是二级索引的数据么 2. 建立的每个索引都有要维护一个数据段么 ?? 那么新插入一行值 , 岂不是每个索引段都会维护这个值 3. 索引的n阶表示n个数据页么。那是不是插入第一行数据树高1 ,就是一个数据页, 插入二三行,树高是二,那就是两个数据页,而且B+树只有leaf node存数据,所以父节点实际上有没有数据,但是占一个页 ,好浪费 , 是我理解有误么 4. 树高取决于数据页的大小么 , 这个不是很能理解 ,数据页为16k 。 那么树高不是一个定值了么,难道还和里面存数据的大小有关么 5. 查询数据的时候,大致的流程细化来说 ,我这么理解对么 。 通过优化器到表里的数据段/索引段取数据 ,数据是按照段->区->页维度去取 , 取完后先放到数据缓冲池中,再通过二分法查询叶结点的有序链表数组找到行数据返回给用户 。 当数据量大的时候,会存在不同的区,取范围值的时候会到不同的区取页的数据返回用户。 这块知识有点比较难理解,看书和一些文章的时候也比较晦涩,希望老师能解答下,感觉这块啃不透 是不是索引设计起来就比较吃力作者回复: 1. 这样理解也算对,不过要记得 主键也是索引的一种哈 2. 是的,所以说索引越多,“维护成本”越大 3. 如果是几百个儿子节点共用一个父节点,是不是就不会看上去那么浪费啦 4. 树高其实取决于叶子树(数据行数)和“N叉树”的N。 而N是由页大小和索引大小决定的。 5. 基本是你说的流程。不过不是“优化器”去取的,是执行器调用引擎,引擎内部才管理了你说的 段、页这些数据
2018-11-2419214 我来也置顶老师的每一篇都会讲到平常工作用遇到的事情. 这个专栏真的很值. 今天这个 alter table T engine=InnoDB 让我想到了我们线上的一个表, 记录日志用的, 会定期删除过早之前的数据. 最后这个表实际内容的大小才10G, 而他的索引却有30G. 在阿里云控制面板上看,就是占了40G空间. 这可花的是真金白银啊. 后来了解到是 InnoDB 这种引擎导致的,虽然删除了表的部分记录,但是它的索引还在, 并未释放. 只能是重新建表才能重建索引. 如果当时看到了这个专栏,把这个语句拿来用,就可以省下不少钱了.
我来也置顶老师的每一篇都会讲到平常工作用遇到的事情. 这个专栏真的很值. 今天这个 alter table T engine=InnoDB 让我想到了我们线上的一个表, 记录日志用的, 会定期删除过早之前的数据. 最后这个表实际内容的大小才10G, 而他的索引却有30G. 在阿里云控制面板上看,就是占了40G空间. 这可花的是真金白银啊. 后来了解到是 InnoDB 这种引擎导致的,虽然删除了表的部分记录,但是它的索引还在, 并未释放. 只能是重新建表才能重建索引. 如果当时看到了这个专栏,把这个语句拿来用,就可以省下不少钱了.作者回复: 😄确实例子都是血泪史,有些是我的血泪、有些是帮助人擦眼泪💧 也鼓励大家把平时碰到的问题提出来,大家一起未雨绸缪🤝
2018-11-2469821 约书亚置顶疑问: 1. 有些资料提到,在不影响排序结果的情况下,在取出主键后,回表之前,会在对所有获取到的主键排序,请问是否存在这种情况? 2. 索引下推那个例子,感觉5.6之前的机制很匪夷所思:感觉判断'张%'之后再“看age的值”是顺理成章的事。难道联合索引的底层实现结构在这期间发生了变化?
约书亚置顶疑问: 1. 有些资料提到,在不影响排序结果的情况下,在取出主键后,回表之前,会在对所有获取到的主键排序,请问是否存在这种情况? 2. 索引下推那个例子,感觉5.6之前的机制很匪夷所思:感觉判断'张%'之后再“看age的值”是顺理成章的事。难道联合索引的底层实现结构在这期间发生了变化?作者回复: 1. 有的, Multi-Range Read (MRR) 由于不论是否使用这个策略,SQL语句写法不变,就没有在正文中提 2. 不是,是接口能力发生了变化,以前只能传“搜索关键字” 。 如果你用过5.1 甚至5.0, 在从现在的观点看,你会发现很多“匪夷所思”。还有:并行复制官方5.6才引入、MDL 5.5 才有、Innodb 自增主键持久化、多源复制、online DDL ... 只能说,持续进化,幸甚至哉😄
2018-11-2326115 狼的诱惑踩过坑:有人问我联合索引的技巧,回答的不是很好 总结: 1、覆盖索引:如果查询条件使用的是普通索引(或是联合索引的最左原则字段),查询结果是联合索引的字段或是主键,不用回表操作,直接返回结果,减少IO磁盘读写读取正行数据 2、最左前缀:联合索引的最左 N 个字段,也可以是字符串索引的最左 M 个字符 3、联合索引:根据创建联合索引的顺序,以最左原则进行where检索,比如(age,name)以age=1 或 age= 1 and name=‘张三’可以使用索引,单以name=‘张三’ 不会使用索引,考虑到存储空间的问题,还请根据业务需求,将查找频繁的数据进行靠左创建索引。 4、索引下推:like 'hello%’and age >10 检索,MySQL5.6版本之前,会对匹配的数据进行回表查询。5.6版本后,会先过滤掉age<10的数据,再进行回表查询,减少回表率,提升检索速度
狼的诱惑踩过坑:有人问我联合索引的技巧,回答的不是很好 总结: 1、覆盖索引:如果查询条件使用的是普通索引(或是联合索引的最左原则字段),查询结果是联合索引的字段或是主键,不用回表操作,直接返回结果,减少IO磁盘读写读取正行数据 2、最左前缀:联合索引的最左 N 个字段,也可以是字符串索引的最左 M 个字符 3、联合索引:根据创建联合索引的顺序,以最左原则进行where检索,比如(age,name)以age=1 或 age= 1 and name=‘张三’可以使用索引,单以name=‘张三’ 不会使用索引,考虑到存储空间的问题,还请根据业务需求,将查找频繁的数据进行靠左创建索引。 4、索引下推:like 'hello%’and age >10 检索,MySQL5.6版本之前,会对匹配的数据进行回表查询。5.6版本后,会先过滤掉age<10的数据,再进行回表查询,减少回表率,提升检索速度作者回复: 赞,下次再问你就这么答,棒棒哒
2018-11-2736462 某、人先回答老师的问题: 如果c列上重复率很低的情况下,两个索引都可以不用建。因为如果过滤只剩下几条数据,排序也不影响 如果C列重复度比较高,就需要建立(c,b)的联合索引了,来消除排序了。因为在数据量大的情况下,排序是一个非常耗时的操作, 很有可能还需要磁盘临时表来做排序。而且如果没有(c,b)联合索引,limit 1仅仅表示返回给客户端一条数据,没有起到限制扫描行数的作用 ca列上的索引,由于满足最左前缀,不用加。因为c是固定值,那么a列就是有序的.那么这里limit 1就很好限制了只用精准扫描一条数据. 所以有时候如果在where条件建立索引的效率差的情况下,在order by limit这一列建索引也是很好的方案,排好序,在回表,只要过滤出满足条件的limit行,就能及时停止扫描 老师我有几个问题: 1.using where的时候,需要回表,然后把数据传输给server层,server层来过滤数据。那么这些数据是存在server层的哪个地方呢? 2.limit起到限制扫描行数作用并且有using where的时候,limit这个操作时在存储引擎层做的还是在server层做的? 3.ICP是不是做得不太好,感觉很多地方没有用到索引下推,都会显示using index condition
某、人先回答老师的问题: 如果c列上重复率很低的情况下,两个索引都可以不用建。因为如果过滤只剩下几条数据,排序也不影响 如果C列重复度比较高,就需要建立(c,b)的联合索引了,来消除排序了。因为在数据量大的情况下,排序是一个非常耗时的操作, 很有可能还需要磁盘临时表来做排序。而且如果没有(c,b)联合索引,limit 1仅仅表示返回给客户端一条数据,没有起到限制扫描行数的作用 ca列上的索引,由于满足最左前缀,不用加。因为c是固定值,那么a列就是有序的.那么这里limit 1就很好限制了只用精准扫描一条数据. 所以有时候如果在where条件建立索引的效率差的情况下,在order by limit这一列建索引也是很好的方案,排好序,在回表,只要过滤出满足条件的limit行,就能及时停止扫描 老师我有几个问题: 1.using where的时候,需要回表,然后把数据传输给server层,server层来过滤数据。那么这些数据是存在server层的哪个地方呢? 2.limit起到限制扫描行数作用并且有using where的时候,limit这个操作时在存储引擎层做的还是在server层做的? 3.ICP是不是做得不太好,感觉很多地方没有用到索引下推,都会显示using index condition作者回复: 回答得很好。 1. 没有存,就是一个临时内存,读出来马上判断,然后扫描下一行可以复用 2. Server层。 接上面的逻辑,读完以后顺便判断一下够不够limit 的数了,够就结束循环 3. 嗯,你很细心,其实它表示的是“可以下推”,实际上是“可以,但没有”😄
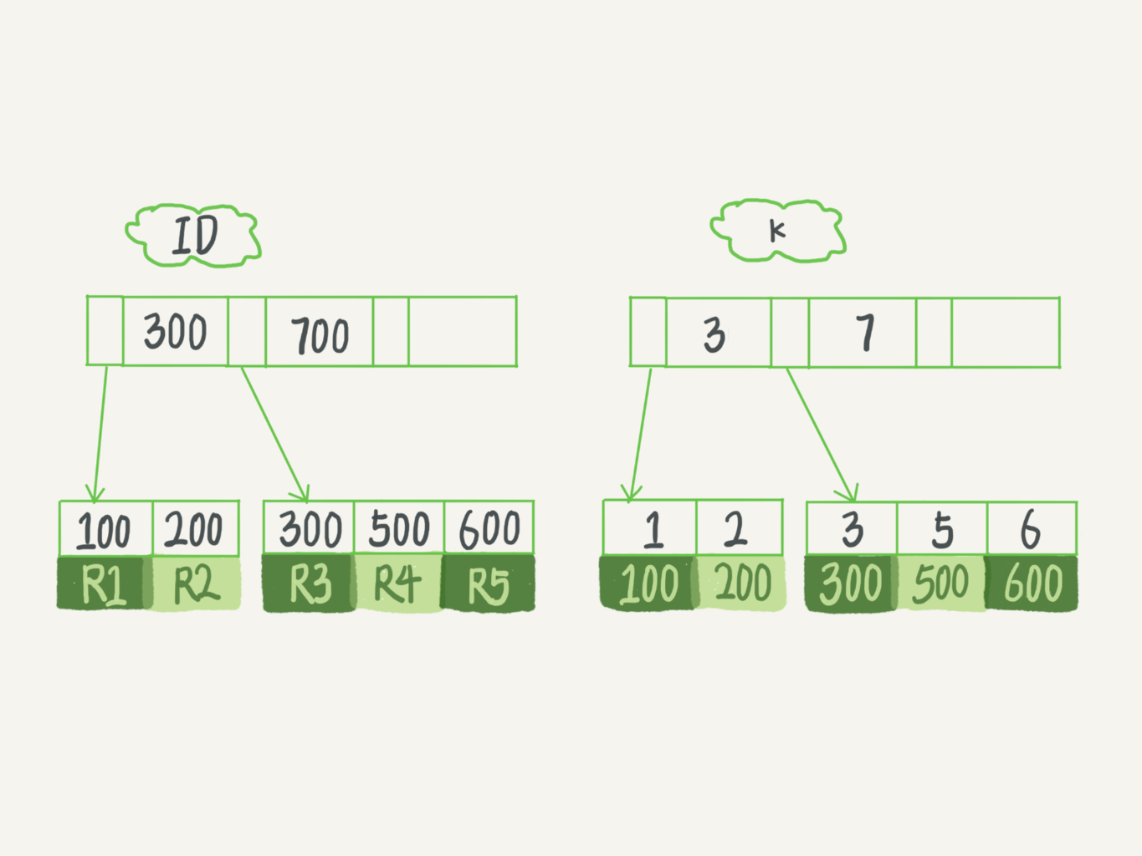
2018-11-2328271- 不二很二老师,下面两条语句有什么区别,为什么都提倡使用2: 1.select * from T where k in(1,2,3,4,5) 2.select * from T where k between 1 and 5
作者回复: 好问题, 第一个要树搜素5次 第二个搜索一次
2018-12-2634261  melon关于联合索引我的理解是这样的:比如一个联合索引(a,b,c),其实质是按a,b,c的顺序拼接成了一个二进制字节数组,索引记录是按该字节数组逐字节比较排序的,所以其是先按a排序,再按b排序,再按c排序的,至于其为什么是按最左前缀匹配的也就显而易见了,没看过源码,不知道理解的对不对,希望老师指正。 给表创建索引时,应该创建哪些索引,每个索引应该包含哪些字段,字段的顺序怎么排列,这个问题没有标准答案,需要根据具体的业务来做权衡。不过有些思路还是可供参考的: 1.既然是一个权衡问题,没有办法保证所有的查询都高效,那就要优先保证高频的查询高效,较低频次的查询也尽可能的使用到尽可能长的最左前缀索引。可以借助pt-query-digest来采样统计业务查询语句的访问频度,可能需要迭代几次才能确定联合索引的最终字段及其排序。 2.业务是在演进的,所以索引也是要随着业务演进的,并不是索引建好了就万事大吉了,业务发生变化时,我们需要重新审视当初建的索引是不是还依然高效,依然能满足业务需求。 3.业内流传的有一些mysql 军规,其实这些并不是真正的军规,只是典型场景下的最佳实践。真正的军规其实就一条:高效的效满足业务需求。比如有个军规规定一个表上的索引数不超过5个,但如果我们现在有一些历史数据表、历史日志表,我们很明确的知道这些表上不会再有数据写入了,但我们的查询需求很多也很多样化,那我们在这些表上的索引数能不能超过5个?当然是没有任何问题的。当然关于这份军规还是要认真看一下的,但看的重点不是去记住它,而是要弄明白每一条军规它为什么这么规定,它这样规定是基于什么考虑,适用的场景和前提是什么,这些都弄明白了,你记不记得住这些军规都无所谓了,因为你已经把它溶化到了你的血液中,具体到自己的具体业务时游刃有余将是必然。
melon关于联合索引我的理解是这样的:比如一个联合索引(a,b,c),其实质是按a,b,c的顺序拼接成了一个二进制字节数组,索引记录是按该字节数组逐字节比较排序的,所以其是先按a排序,再按b排序,再按c排序的,至于其为什么是按最左前缀匹配的也就显而易见了,没看过源码,不知道理解的对不对,希望老师指正。 给表创建索引时,应该创建哪些索引,每个索引应该包含哪些字段,字段的顺序怎么排列,这个问题没有标准答案,需要根据具体的业务来做权衡。不过有些思路还是可供参考的: 1.既然是一个权衡问题,没有办法保证所有的查询都高效,那就要优先保证高频的查询高效,较低频次的查询也尽可能的使用到尽可能长的最左前缀索引。可以借助pt-query-digest来采样统计业务查询语句的访问频度,可能需要迭代几次才能确定联合索引的最终字段及其排序。 2.业务是在演进的,所以索引也是要随着业务演进的,并不是索引建好了就万事大吉了,业务发生变化时,我们需要重新审视当初建的索引是不是还依然高效,依然能满足业务需求。 3.业内流传的有一些mysql 军规,其实这些并不是真正的军规,只是典型场景下的最佳实践。真正的军规其实就一条:高效的效满足业务需求。比如有个军规规定一个表上的索引数不超过5个,但如果我们现在有一些历史数据表、历史日志表,我们很明确的知道这些表上不会再有数据写入了,但我们的查询需求很多也很多样化,那我们在这些表上的索引数能不能超过5个?当然是没有任何问题的。当然关于这份军规还是要认真看一下的,但看的重点不是去记住它,而是要弄明白每一条军规它为什么这么规定,它这样规定是基于什么考虑,适用的场景和前提是什么,这些都弄明白了,你记不记得住这些军规都无所谓了,因为你已经把它溶化到了你的血液中,具体到自己的具体业务时游刃有余将是必然。作者回复: 非常赞,尤其是第三段对“军规”的理解👍🏿
2018-11-2710207 司徒公子面试官问:说下怎么让mysql的myisam引擎支持事务,网上搜了下,也没有结果!
司徒公子面试官问:说下怎么让mysql的myisam引擎支持事务,网上搜了下,也没有结果!作者回复: ……… 面试官是魔鬼吗😄 我怀疑他是想说用lock table 来实现,但是这样只能实现串行化隔离级别, 其它隔离都实现不了。 但是因为mysiam不支持崩溃恢复,所以即使用lock table硬实现,也是问题多多: ACID里面, 原子性和持久性做不到; 隔离性只能实现基本用不上的串行化; 一致性在正常运行的时候依赖于串行化,在异常崩溃的时候也不能保证。 这样实现的事务不要也罢。 你这么答复面试官,应该能加到分吧😄
2018-12-1916130

