

12|基于热度的召回:如何使用热门内容来吸引用户?
黄鸿波

你好,我是黄鸿波。
在上一节课中,我们整体了解召回以及关于规则召回的相关知识,今天我们将聚焦在基于规则召回的另外一个分支:基于热度的召回。
基于热度的召回
基于热度的召回是召回算法中最直观且最简单的一种召回算法,它通过计算内容与用户之间交互的各个维度,从而设计出一套能够反映出内容受欢迎程度的算法,再根据这个算法进行召回。
我们通过微博这个 App 来简单说明一下基于热度的召回算法。
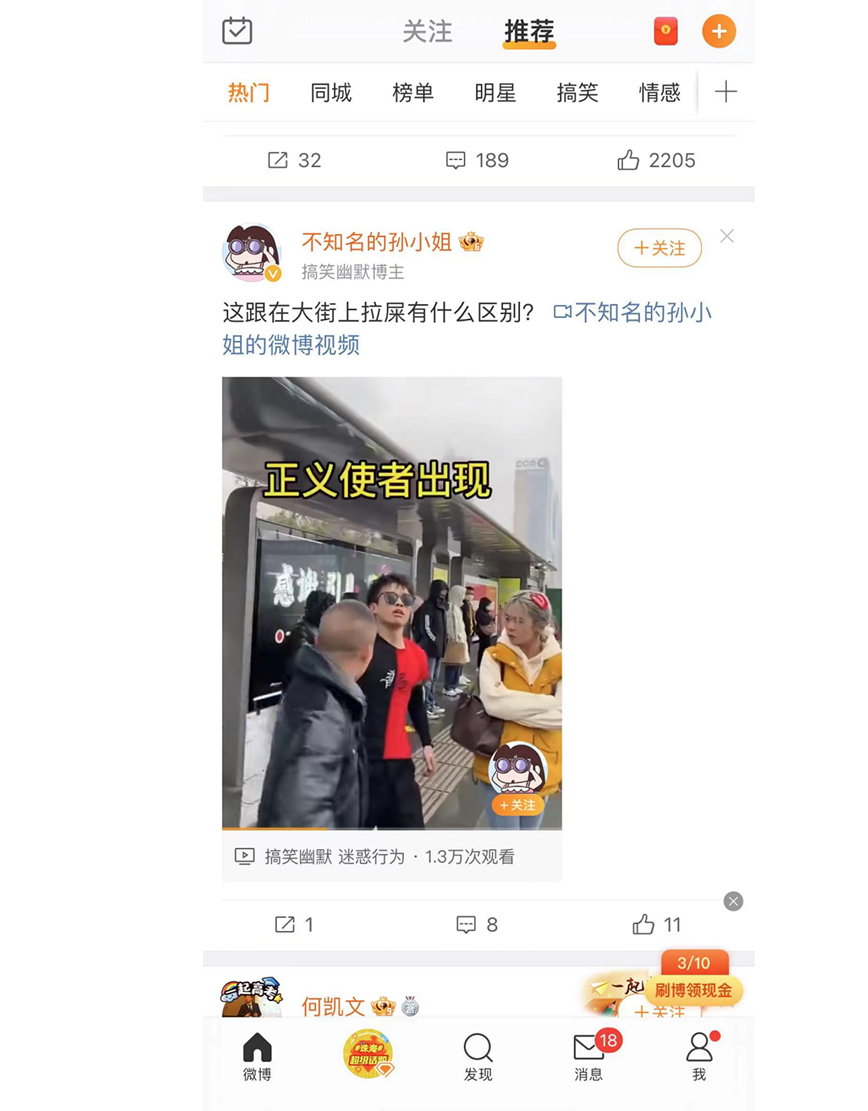
我们可以看到在这个界面中的每一个条目中都有三个指标:转发、评论和点赞。当然,在画像中一定还有阅读指标。一般来讲,如果一篇内容的这四个指标越高,说明这篇内容就越受欢迎。
我们可以根据这四个指标的重要性,赋予相应的权重值。对于一篇文章来讲,如果没有任何阅读行为,我们可以认为这篇文章的热度值为 0,因为没有阅读行为也就不会有点赞,更不会有评论的产生。在这篇文章有阅读行为的基础上,如果这篇文章被用户喜欢,用户可能会点赞以及评论。如果非常喜欢,用户还会进行转发。
因此,对于转发、评论、点赞和阅读这四种操作类型,我们可以将其分别设置为权重为 0.4、0.3、0.2、0.1,针对上图中的帖子,假设这里的阅读数为 27000,点赞数为 11,评论数为 8,转发数为 1,就可以设计一个这样的公式。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

本文介绍了基于热度的召回算法及热度衰减算法的设计原理和实现方法。首先,作者介绍了基于热度的召回算法的实现思路,包括召回算法和结果的实现以及热度值的更新。其次,文章强调了热度不仅需要增加,还需要有衰减的过程,并提出了基于牛顿冷却定律的热度衰减算法。最后,总结了基于热度召回的主要知识点,包括热度值的计算和变化更新,以及实现思路。整体而言,本文深入浅出地介绍了基于热度的召回算法及热度衰减算法的设计原理和实现方法,对于想要吸引用户的产品开发者和技术人员具有一定的参考价值。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《手把手带你搭建推荐系统》,新⼈⾸单¥59
《手把手带你搭建推荐系统》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(4)
- 最新
- 精选
 peter请教老师几个问题: Q1:权重的设置有什么根据?完全是经验值吗?还是说有一个计算公式?本专栏类似于培训课程,在公司的实际开发中也是凭经验设置权重吗? Q2:衰减系数公式的设置,也不是理性推导得来的,似乎也是根据经验,理论性不强啊。公司实际开发中也是这么实现的吗? Q3:权重设置、衰减系数计算,是否用到了仿真?
peter请教老师几个问题: Q1:权重的设置有什么根据?完全是经验值吗?还是说有一个计算公式?本专栏类似于培训课程,在公司的实际开发中也是凭经验设置权重吗? Q2:衰减系数公式的设置,也不是理性推导得来的,似乎也是根据经验,理论性不强啊。公司实际开发中也是这么实现的吗? Q3:权重设置、衰减系数计算,是否用到了仿真?作者回复: A1:这里的权重一般是由产品经理来评估每个参数和指标对于整个产品的重要性,以此来进行设置,没有具体的公式,在实际工作中也是如此,都是凭借经验然后慢慢调整; A2:衰减实际上是根据牛顿冷却定律的思路来做的,在实际工作中一般也是沿用这个思路来做; A3:没太理解这里的仿真指的是什么?
2023-05-16归属地:北京- Geek_ccc0fd实现代码: from dao.mongo_db import MongoDB import datetime import math class ContentLabel(object): def __init__(self): self.mongo_recommendation = MongoDB(db='recommendation') self.content_label_collection = self.mongo_recommendation.db_recommendation['content_label'] def get_data_from_mongodb(self): datas = self.content_label_collection.find() return datas def update_content_hot(self): datas = self.get_data_from_mongodb() for data in datas: self.content_label_collection.update_one({"_id": data['_id']}, {"$set": {"hot_heat": self.hot_time_alpha(data['hot_heat'], data['news_date'])}}) def hot_time_alpha(self, hot_value, news_date, alpha=0.01): # 计算当前时间和新闻时间天数差 day = (datetime.datetime.now() - news_date).days hot = hot_value / math.pow(day, alpha) return hot
作者回复: 感谢你提供的代码
2023-05-12归属地:广东2  moonfeeling老师您好,如何理解这段话:在这里,我们还要考虑一个特殊的情况:如果短时间内一个关键词被频繁搜索或关注,就说明这个内容是一个最近突然非常热的话题,我们在求其热度值的时候就要做一个时间的加权。 是不是这样理解的:如果短时间内某几个关键词被频繁搜索,对具有这些热搜关键词的内容要增加热度呢? Q1:要查找具有热搜关键词的内容,是不是需要对内容进行关键词提取?当出现高频搜索的词汇时,就要对所有内容根据热搜词汇检索,找出这些内容来增加热度呢? Q2:具体热度值是如何增加的呢?另外您文中提到的“求其热度值的时候就要做一个时间的加权”,这个时间的加权是什么意思呢?如何实现的呢?2024-01-04归属地:河南
moonfeeling老师您好,如何理解这段话:在这里,我们还要考虑一个特殊的情况:如果短时间内一个关键词被频繁搜索或关注,就说明这个内容是一个最近突然非常热的话题,我们在求其热度值的时候就要做一个时间的加权。 是不是这样理解的:如果短时间内某几个关键词被频繁搜索,对具有这些热搜关键词的内容要增加热度呢? Q1:要查找具有热搜关键词的内容,是不是需要对内容进行关键词提取?当出现高频搜索的词汇时,就要对所有内容根据热搜词汇检索,找出这些内容来增加热度呢? Q2:具体热度值是如何增加的呢?另外您文中提到的“求其热度值的时候就要做一个时间的加权”,这个时间的加权是什么意思呢?如何实现的呢?2024-01-04归属地:河南 悟尘在实现过程中,我们需要对模块有一个基本的权重定义,我们可以根据用户的兴趣程度以及运营需求来设置模块的权重。例如在上面的例子中,我们可以假设财经、体育、娱乐、教育的权重分别为 0.4、0.3、0.2、0.1 “0.4、0.3、0.2、0.1”这四个权重值,是针对每一位用户都要设置不同的权重还是针对这四个模块设置的权重?如果只是针对这四个模块设置的权重,那给所有用户推荐的文章类别顺序都是按照【财经、体育、娱乐、教育】这四个顺序进行推荐的吗?2023-12-12归属地:北京
悟尘在实现过程中,我们需要对模块有一个基本的权重定义,我们可以根据用户的兴趣程度以及运营需求来设置模块的权重。例如在上面的例子中,我们可以假设财经、体育、娱乐、教育的权重分别为 0.4、0.3、0.2、0.1 “0.4、0.3、0.2、0.1”这四个权重值,是针对每一位用户都要设置不同的权重还是针对这四个模块设置的权重?如果只是针对这四个模块设置的权重,那给所有用户推荐的文章类别顺序都是按照【财经、体育、娱乐、教育】这四个顺序进行推荐的吗?2023-12-12归属地:北京
收起评论

