

02|Netflix推荐系统:企业级的推荐系统架构是怎样的?

什么是 Netflix 系统?
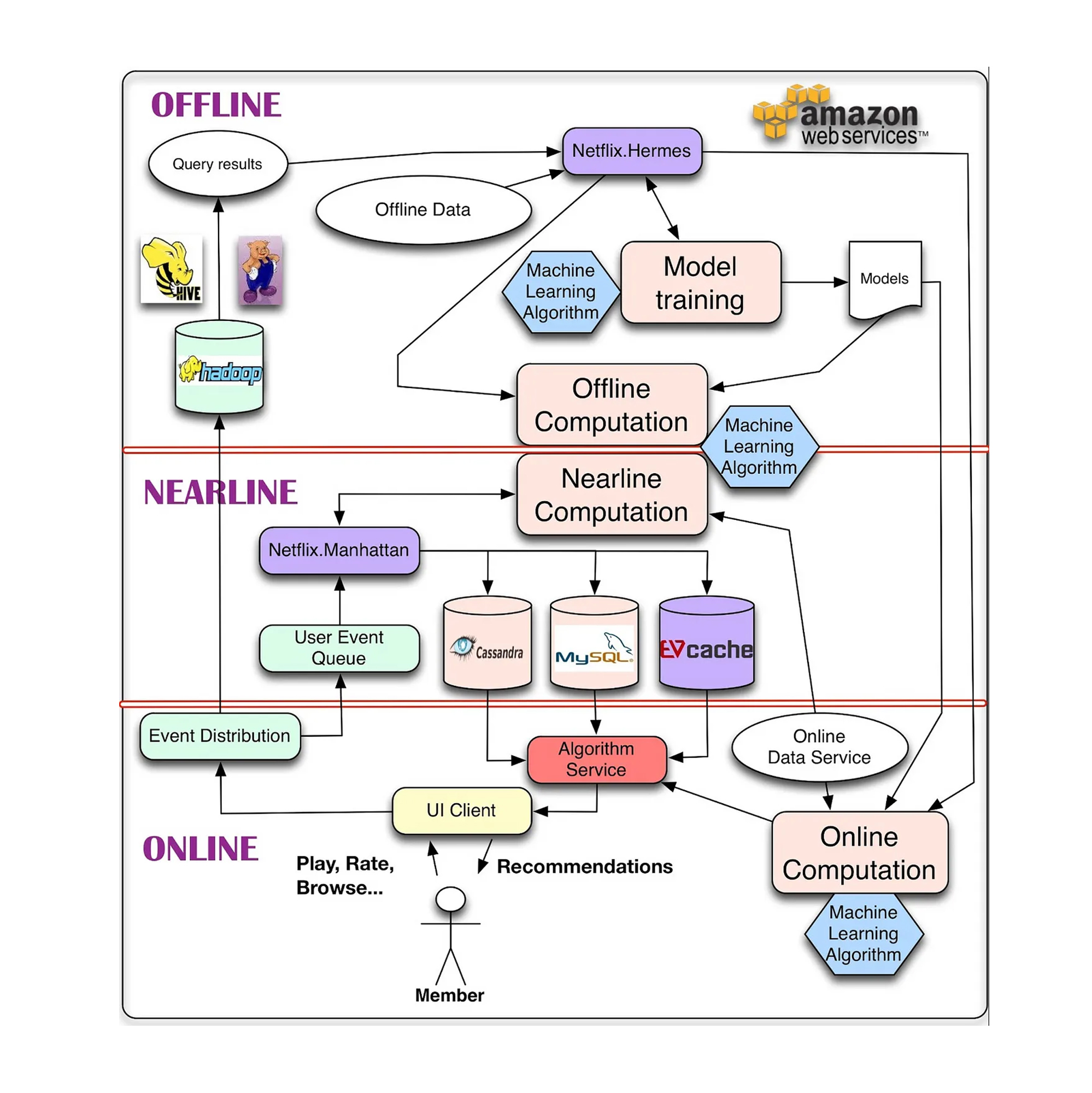
离线层、在线层和近似在线层
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

Netflix推荐系统架构为例,详细介绍了企业级推荐系统的离线层、在线层和近似在线层的工作内容和关系。离线层主要进行数据库查询、特征工程和数据处理等工作,不需要实时反馈给用户;在线层需要实时反馈给用户推荐结果,对模型和算法的实时性要求很高;而近似在线层介于两者之间,对实时性的要求贴近于在线层。这三层结构的工作内容和实时性要求,为企业级推荐系统的架构提供了清晰的指导。整个推荐过程需要层与层之间的协同配合,Netflix在整体的设计里也对此做了充分的考量。企业级推荐系统还会涉及各种对于评分的计算、点击率的预估等,这些内容都是一个完整的企业级推荐系统必不可少的。
《手把手带你搭建推荐系统》,新⼈⾸单¥59

全部留言(3)
- 最新
- 精选
 一五一十1. 在线层对响应时间要求较高,因此用 redis 这种内存数据结构较好;近似在线层可以用 Mysql 这种存储非海量的数据;离线曾用 hadoop hive 这些存储海量数据。 2. 后端会对召回数据做一些精细的筛选和重排后返回给用户 topN,然后将用户的操作行为再收集给到离线层。 自己理解,如果不对还请老师和同学们批评指正哈。
一五一十1. 在线层对响应时间要求较高,因此用 redis 这种内存数据结构较好;近似在线层可以用 Mysql 这种存储非海量的数据;离线曾用 hadoop hive 这些存储海量数据。 2. 后端会对召回数据做一些精细的筛选和重排后返回给用户 topN,然后将用户的操作行为再收集给到离线层。 自己理解,如果不对还请老师和同学们批评指正哈。作者回复: 答:同学你好,你的理解是完全正确的。另外,近似在线层也可以使用Redis这类的数据库,主要是看你的近似在线层对实时性的要求有多高。
2023-04-27归属地:北京2 peter请教老师几个问题: Q1:Netflix推荐系统“开放”具体指什么?是指开源吗?或者是类似工具一类的可以拿来直接用?或者SDK?或者只是提供架构图一类的原理性解释? Q2:近似在线层,既然是“粗排序”,怎么会是“精召回”呢?应该是“粗召回”才更合理啊。 Q3:在线层依赖近似在线层的话,怎么保证在线层的实时性? 文中提到“等到近似在线层处理完成后,会将结果输入到在线层。而在线层更多地是做了一个排序工作,它把离线特征数据和从近似在线层得到的待推荐列表组合起来”,从这句话看,在线层是依赖近似在线层。如果有依赖,近似在线层是分钟级,而在线层是50毫秒,就无法保证实时性了啊。 Q4:NetFlix的三层架构是通用的吗? Q5:推荐系统对大数据依赖大吗?大数据框架出现之前有推荐系统吗?
peter请教老师几个问题: Q1:Netflix推荐系统“开放”具体指什么?是指开源吗?或者是类似工具一类的可以拿来直接用?或者SDK?或者只是提供架构图一类的原理性解释? Q2:近似在线层,既然是“粗排序”,怎么会是“精召回”呢?应该是“粗召回”才更合理啊。 Q3:在线层依赖近似在线层的话,怎么保证在线层的实时性? 文中提到“等到近似在线层处理完成后,会将结果输入到在线层。而在线层更多地是做了一个排序工作,它把离线特征数据和从近似在线层得到的待推荐列表组合起来”,从这句话看,在线层是依赖近似在线层。如果有依赖,近似在线层是分钟级,而在线层是50毫秒,就无法保证实时性了啊。 Q4:NetFlix的三层架构是通用的吗? Q5:推荐系统对大数据依赖大吗?大数据框架出现之前有推荐系统吗?作者回复: 同学你好,我来回答你的这几个问题: 1、课程中所说的开放,指的是他们的论文,而不是开源,就是Netflix已经发表了论文,详细地说明了这一套是怎么做的; 2、我是这么理解的,近似在线层是在召回层之后,实际上是对召回层的数据根据用户的信息再一次做筛选,因此可以理解为是更精细的召回,但是相对于排序来说,它的内容还是太多,所以是粗排序; 3、在线层依赖于近似在线层的结果,但是近似在线层实际上是对用户最近几分钟的历史行为来做更新,我们主要是取近似在线层更新的结果,所以,近似在线层的计算耗时并不影响在线层取内容; 4、Netflix的三层架构基本上现在的推荐系统都是这么来做的,相对通用; 5、推荐系统对大数据的依赖可大可小,主要看用户和内容的规模,因此,大数据框架出现之前,实际上也是可以利用其它的存储方式来获取数据进行计算,而且在大数据出现之前,一般业务量也不会特别大,所以,我认为,这个是时代发展的结果。
2023-04-12归属地:北京2 GAC·DU在线层存储用户实时轨迹数据,近似在线层存储业务逻辑数据,离线层存储用户历史轨迹数据。离线数据存储在Hadoop的分布式文件系统中,其余两者存储在Kafka消息队列中。后端服务系统接收数据后,做进一步的关联查询,把最终结果推给前端服务。不知道思考的对不对?思考的过程中觉得虽然做了分层,对执行性能上做了优化,但是耦合度太高,尤其是近似实时层,承上启下,重要程度不言自明,能否可以做一个降级的方案,做到即使某一层挂了也能做到最小程度的推荐?
GAC·DU在线层存储用户实时轨迹数据,近似在线层存储业务逻辑数据,离线层存储用户历史轨迹数据。离线数据存储在Hadoop的分布式文件系统中,其余两者存储在Kafka消息队列中。后端服务系统接收数据后,做进一步的关联查询,把最终结果推给前端服务。不知道思考的对不对?思考的过程中觉得虽然做了分层,对执行性能上做了优化,但是耦合度太高,尤其是近似实时层,承上启下,重要程度不言自明,能否可以做一个降级的方案,做到即使某一层挂了也能做到最小程度的推荐?作者回复: 同学你好,你的这个理解稍微有一点点偏差。首先在线层没有做存储功能,只是去收集实时数据,然后给到近似在线层和离线层。离线层存储的有2个,一个是历史轨迹,一个是本地信息,比如用户画像、用户数据、内容数据、内容画像等,kafka的消息队列,不做存储,你可以理解为一个管道,kafka只是这根管子,数据是在这里面排队的。 这些数据会经历离线的召回、近似在线层的排序和在线层的重排序,然后给到用户。 如果需要做降级的话,我们一般可以把近似在线层的值同时存入到两种数据库,比如MongoDB和Redis,如果Redis取不到就从MongoDB中取。层与层之间也是这样。
2023-04-12归属地:北京

