

09|数据存储:如何将爬取到的数据存入数据库中?

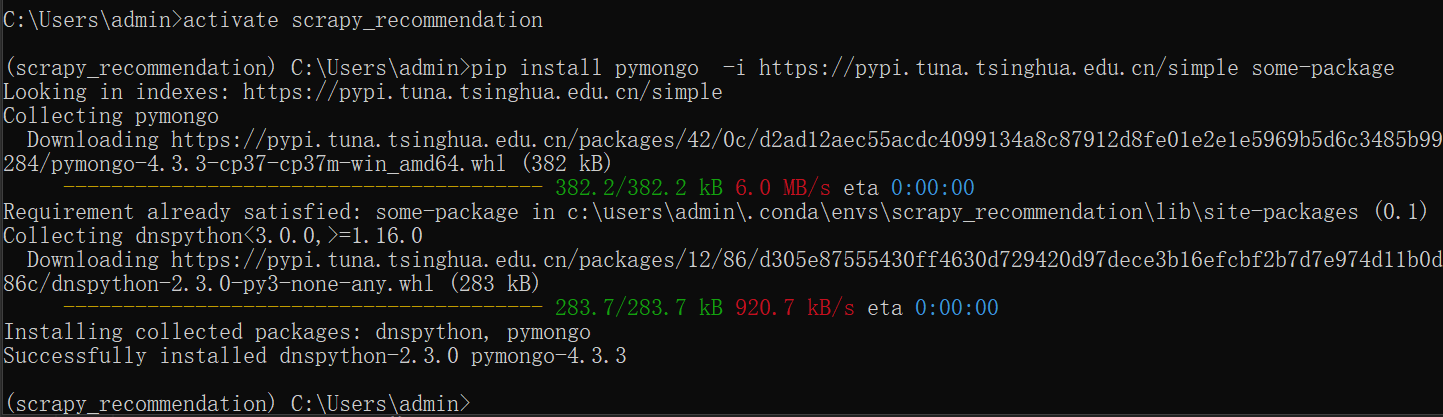
Python 中的 pymongo 库
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

本文详细介绍了如何使用Scrapy框架和pymongo库将爬取到的数据存入MongoDB数据库中。首先讲解了pymongo库的安装和基本使用方法,然后详细讲解了在Python中连接MongoDB数据库的步骤,并给出了一个简单的例子。接着,文章讲解了如何在Scrapy中使用pymongo进行数据存储,通过重写pipelines.py文件中的process_item函数,将爬取到的数据存入MongoDB数据库中。最后,文章提到了将pipeline与爬虫程序进行关联的操作,需要在settings.py文件中进行配置。整体来说,本文通过实际代码示例和详细步骤,帮助读者了解了如何使用Scrapy和pymongo库将爬取到的数据存入MongoDB数据库中。文章内容涵盖了pymongo库的安装和基本使用、Scrapy中数据处理和保存的方法,以及settings.py文件下的各个配置,对于想要学习如何进行数据爬取和存储的读者来说,是一篇很有价值的技术文章。
《手把手带你搭建推荐系统》,新⼈⾸单¥59

全部留言(8)
- 最新
- 精选
 peter第07课,创建爬虫程序出错的问题解决了,解决方法如下: E:\Javaweb\study\recommendsys,这个目录下面有env和project两个子目录,Anaconda安装在env下面,虚拟环境在Anaconda的安装目录下面。爬虫项目在project目录下面。然后执行“scrapy genspider sina_spider sina.com.cn”时候报错了几次。 后来在E盘下创建geekbang,和老师的目录一样,又创建了一个新的虚拟环境,照着老师的流程做下来,就成功创建了爬虫程序。 问题解决了,不知道具体原因,感觉是目录问题。对于这个问题,老师如果有看法就告诉我一下,比如目录位置有一些坑。
peter第07课,创建爬虫程序出错的问题解决了,解决方法如下: E:\Javaweb\study\recommendsys,这个目录下面有env和project两个子目录,Anaconda安装在env下面,虚拟环境在Anaconda的安装目录下面。爬虫项目在project目录下面。然后执行“scrapy genspider sina_spider sina.com.cn”时候报错了几次。 后来在E盘下创建geekbang,和老师的目录一样,又创建了一个新的虚拟环境,照着老师的流程做下来,就成功创建了爬虫程序。 问题解决了,不知道具体原因,感觉是目录问题。对于这个问题,老师如果有看法就告诉我一下,比如目录位置有一些坑。作者回复: 同学你好,这个我之前也遇到过,主要是由于字符集的问题,一般这种方法copy到记事本,然后用空格来重新进行缩进,就可以解决。
2023-05-03归属地:北京- peter第07课,创建爬虫程序出错的问题解决了,解决方法如下: E:\Javaweb\study\recommendsys,这个目录下面有env和project两个子目录,Anaconda安装在env下面,虚拟环境在Anaconda的安装目录下面。爬虫项目在project目录下面。然后执行“scrapy genspider sina_spider sina.com.cn”时候报错了几次。 后来在E盘下创建geekbang,和老师的目录一样,又创建了一个新的虚拟环境,照着老师的流程做下来,就成功创建了爬虫程序。 问题解决了,不知道具体原因,感觉是目录问题。对于这个问题,老师如果有看法就告诉我一下,比如目录位置有一些坑。 运行main.py后,遇到两个问题: Q1:ROBOTSTXT_OBEY = True时爬取失败 创建main.py后,settings.py中,ROBOTSTXT_OBEY = True。 运行后报告: .robotstxt] WARNING: Failure while parsing robots.txt. File either contains garbage or is in an encoding other than UTF-8, treating it as an empty file。 该错误导致另外一个错误: robotstxt.py", line 15, in decode_robotstxt robotstxt_body = robotstxt_body.decode("utf-8") UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc3 in position 93: invalid continuation byte 网上建议ROBOTSTXT_OBEY 改成 False,好像是成功了。 Q2:成功信息和老师的不同,不确定是否成功。 A 专栏上的成功信息很少,我这里的信息非常多,是log设置不同吗?(我用PyCharm4.5)。 B 专栏上的成功信息,有两个链接: Get https://news.sina.com.cn/robots.txt Get https://news.sina.com.cn/china 但我的输出信息中并没有这两个链接,还没有成功吗? 部分信息如下: 2023-05-02 12:56:00 [scrapy.core.engine] INFO: Spider opened 2023-05-02 12:56:00 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min) 2023-05-02 12:56:00 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023 2023-05-02 12:56:00 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (301) to <GET https://www.sina.com.cn/> from <GET http://sina.com.cn/> 2023-05-02 [engine] DEBUG: Crawled (200) <GET https://www.sina.com.cn/> (referer: None) 2023-05-02 [scrapy.core.engine] INFO: Closing spider (finished) 2023-05-02 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
作者回复: 不错,可以推广给同学们。
2023-05-02归属地:北京  GhostGuest第 23 行中 CONCURRENT_REQUESTS 参数解释有误, 这个参数是设置线程数,并不是多线程的开关,文中描述开启就可以利用多线程进行爬取有点歧义了,默认就是多线程爬取的,这个参数只是设置并发量
GhostGuest第 23 行中 CONCURRENT_REQUESTS 参数解释有误, 这个参数是设置线程数,并不是多线程的开关,文中描述开启就可以利用多线程进行爬取有点歧义了,默认就是多线程爬取的,这个参数只是设置并发量作者回复: 同学你好,感谢你的指正。这里我确实说的有些问题。 CONCURRENT_REQUESTS是Scrapy爬虫框架中的一个参数,表示同时发送请求数量的上限。该参数的默认值为16,可以根据具体环境和需求进行调整。例如,将CONCURRENT_REQUESTS设置为32可以在同一时间内发送更多的请求,加快爬取速度。
2023-04-30归属地:上海- 19984598515老师你好,什么时候能有完整源码呢
作者回复: 同学你好,我争取下周放上去。
2023-04-29归属地:贵州 - peter调用流程是在哪里定义的?比如,对于pipelines.py文件,框架会自动调用它,假如我改变文件名字,应该就无法正常运行了;如果知道流程调用关系在哪里定义,就可以在那里修改文件名字。 (是settings.py吗?)
作者回复: 是的,流程的整个调用是在settings.py里,主要是依靠爬虫名来调用整个流程,scrapy的框架流程一般是没办法改的。
2023-04-28归属地:北京  GAC·DU把已经爬过的新闻标题,用Redis set集合存储,作为增量过滤器,如果标题不在集合中则抓取数据并保存数据,同时将新的标题放到集合中。 测试成功,部分代码如下: redis: class RedisDB: def __init__(self): self.host = "ip地址" self.port = 6379 self.passwd = "密码" self.db = 2 self.pool = redis.ConnectionPool(host=self.host, port=self.port, password=self.passwd, db=self.db, decode_responses=True) self.client = redis.Redis(connection_pool=self.pool) def add(self, key, value): return self.client.sadd(key, value) def exists(self, key, value): return self.client.sismember(key, value) spider部分: if self.redis.exists("sina", items["news_title"]): continue self.redis.add("sina", items["news_title"]) 那里有问题,请老师指正,谢谢。
GAC·DU把已经爬过的新闻标题,用Redis set集合存储,作为增量过滤器,如果标题不在集合中则抓取数据并保存数据,同时将新的标题放到集合中。 测试成功,部分代码如下: redis: class RedisDB: def __init__(self): self.host = "ip地址" self.port = 6379 self.passwd = "密码" self.db = 2 self.pool = redis.ConnectionPool(host=self.host, port=self.port, password=self.passwd, db=self.db, decode_responses=True) self.client = redis.Redis(connection_pool=self.pool) def add(self, key, value): return self.client.sadd(key, value) def exists(self, key, value): return self.client.sismember(key, value) spider部分: if self.redis.exists("sina", items["news_title"]): continue self.redis.add("sina", items["news_title"]) 那里有问题,请老师指正,谢谢。作者回复: 同学你好,如果测试通过的话,我觉得这么写没问题。
2023-04-28归属地:北京 悟尘有微信群了吗?我遇到了一些问题,pymongo连不上mongo数据库2023-12-12归属地:北京
悟尘有微信群了吗?我遇到了一些问题,pymongo连不上mongo数据库2023-12-12归属地:北京- peter运行main.py后,遇到两个问题: Q1:ROBOTSTXT_OBEY = True时爬取失败 创建main.py后,settings.py中,ROBOTSTXT_OBEY = True。 运行后报告: .robotstxt] WARNING: Failure while parsing robots.txt. File either contains garbage or is in an encoding other than UTF-8, treating it as an empty file。 该错误导致另外一个错误: robotstxt.py", line 15, in decode_robotstxt robotstxt_body = robotstxt_body.decode("utf-8") UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc3 in position 93: invalid continuation byte 网上建议ROBOTSTXT_OBEY 改成 False,好像是成功了。 Q2:成功信息和老师的不同,不确定是否成功。 A 专栏上的成功信息很少,我这里的信息非常多,是log设置不同吗?(我用PyCharm4.5)。 B 专栏上的成功信息,有两个链接: Get https://news.sina.com.cn/robots.txt Get https://news.sina.com.cn/china 但我的输出信息中并没有这两个链接,还没有成功吗? 部分信息如下: 2023-05-02 12:56:00 [scrapy.core.engine] INFO: Spider opened2023-05-03归属地:北京

