

10|数据加工:如何将原始数据做成内容画像?

内容画像的定义与作用
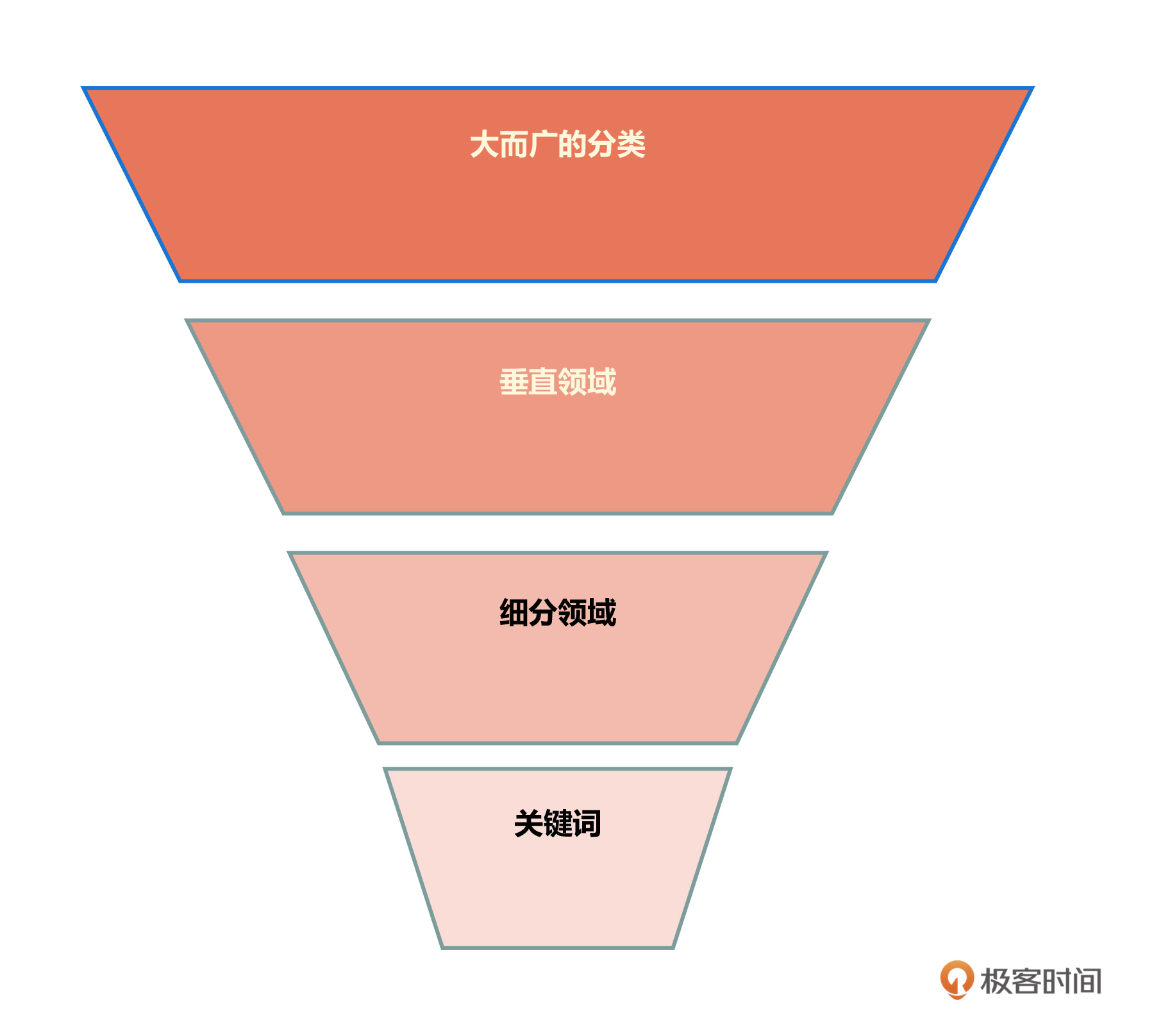
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

本文深入探讨了内容画像在推荐系统中的重要性以及其生成和应用过程。内容画像是对内容进行多维度分类的标签,可用于构建推荐算法和模型。同时,用户画像也是内容画像的一部分,包含用户行为和兴趣。文章介绍了从MongoDB中获取数据、制作内容画像的流程以及在推荐系统中的代码开发部分。通过对MongoDB数据库的操作,读者可以学习将内容画像存储在数据库中的实际操作。此外,文章还提到了如何统计文章字数和提取关键词,并鼓励读者在课后完成相关作业。整体而言,本文内容技术性较强,适合对内容画像及其在推荐系统中的应用感兴趣的读者阅读。 在本文中,读者将了解到内容画像在推荐系统中的关键作用,以及如何使用Python和MongoDB来生成内容画像。此外,课后题目也提供了进一步挖掘特征和加入关键词特征的思路,为读者提供了更多的学习和实践机会。文章内容技术性强,适合对内容画像和推荐系统感兴趣的读者阅读。
《手把手带你搭建推荐系统》,新⼈⾸单¥59

全部留言(11)
- 最新
- 精选
- Geek_ccc0fd关于画像有个问题想请教一下老师: 我们训练样本一般是过去一段时间的数据,但是画像数据保存的最新的画像标签,这里如果直接使用样本关联画像标签的话会发生特征穿越问题,这里实际工作中是如何处理的呢?
作者回复: 特征穿越问题主要是因为在训练模型时,使用了一些在未来才能得到的标签或特征,导致模型在实际使用时表现不佳。在用户画像中,由于画像数据是最新的,而训练样本是过去一段时间的数据,因此会遇到特征穿越问题。 解决这个问题的方法主要有以下几种: 1. 对历史数据进行特征工程,将历史数据中的一些特征转化为对未来数据有预测能力的特征。这样就可以使用历史数据中的特征来预测未来的画像标签,避免了特征穿越问题。 2. 将画像标签作为新的训练样本特征,同时使用前面的历史数据特征作为输入,来训练模型。这种方法可以在模型中加入画像标签的影响,提高模型的预测准确性。同时,还可以使用 rolling window 等方法,避免将未来数据引入模型中。 3. 对数据进行时间切片,将过去一段时间的数据作为一个时间窗口,来训练一个对应的模型。然后使用该模型来预测下一个时间窗口的画像标签。这样就可以保证模型只使用过去的数据,不受未来数据的影响。 综上,面对特征穿越问题,我们需要针对具体场景来选择合适的解决方案。需要考虑的因素包括数据量、数据质量、特征工程复杂度、计算资源等等。
2023-05-08归属地:广东52 - Geek_ccc0fd统计字数那里赋的代码是不是搞错了
作者回复: 这个错在哪里呢,我测试过了,没有什么问题。
2023-05-08归属地:广东51  AbigailRobo 3T is now Studio 3T https://studio3t.com/download/
AbigailRobo 3T is now Studio 3T https://studio3t.com/download/作者回复: 是的,这个是下载robo 3T的网址
2023-11-01归属地:澳大利亚 MWF请问github地址是什么?
MWF请问github地址是什么?作者回复: https://github.com/ipeaking/recommendation https://github.com/ipeaking/scrapy_sina
2023-08-02归属地:广东- MWF请问能否把每一讲的代码(包括网络上爬取到的数据)都上传到github供大家下载呢,因为不是每个人都会从头到尾跟进每一节,比如我主要想学习画像部分的内容,那么没安装数据库以及爬虫相关插件,就无法得到数据进行后面的内容了。
作者回复: https://github.com/ipeaking/recommendation https://github.com/ipeaking/scrapy_sina
2023-08-02归属地:广东  GhostGuest文稿中热度设置错了,代码写的一万,文稿写的一千
GhostGuest文稿中热度设置错了,代码写的一万,文稿写的一千作者回复: 同学你好,谢谢你的指正,已修改。
2023-05-10归属地:上海 翡翠虎除了关键词外,我感觉文章类型(文本分类)、国家地区也可以作为特征之一
翡翠虎除了关键词外,我感觉文章类型(文本分类)、国家地区也可以作为特征之一作者回复: 是的,这里只是举了个例子,实际上可以有更多特征。
2023-05-08归属地:广西 moonfeeling关键词提取可参考这篇文章实现:https://mp.weixin.qq.com/s/Vd58Hxiocx9BkcKvnGS7ng2024-01-04归属地:河南
moonfeeling关键词提取可参考这篇文章实现:https://mp.weixin.qq.com/s/Vd58Hxiocx9BkcKvnGS7ng2024-01-04归属地:河南- moonfeeling老师好,请问下文章和标题中的关键词提取部分的代码在哪里找呢?您给的github中源码好像没有2024-01-04归属地:河南
 悟尘def get_words_nums(self, contents): ch = re.findall('([\u4e00-\u9fa5])', contents) num = len(ch) return num 这个函数的入参应该是 data['desc'] ,即文章正文,具体代码如下: word_nums = self.get_words_nums(data['desc']) content_collection['word_num'] = word_nums2023-12-12归属地:北京
悟尘def get_words_nums(self, contents): ch = re.findall('([\u4e00-\u9fa5])', contents) num = len(ch) return num 这个函数的入参应该是 data['desc'] ,即文章正文,具体代码如下: word_nums = self.get_words_nums(data['desc']) content_collection['word_num'] = word_nums2023-12-12归属地:北京

