

03|数据处理:我们应该如何获取和处理数据?

数据获取方式
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

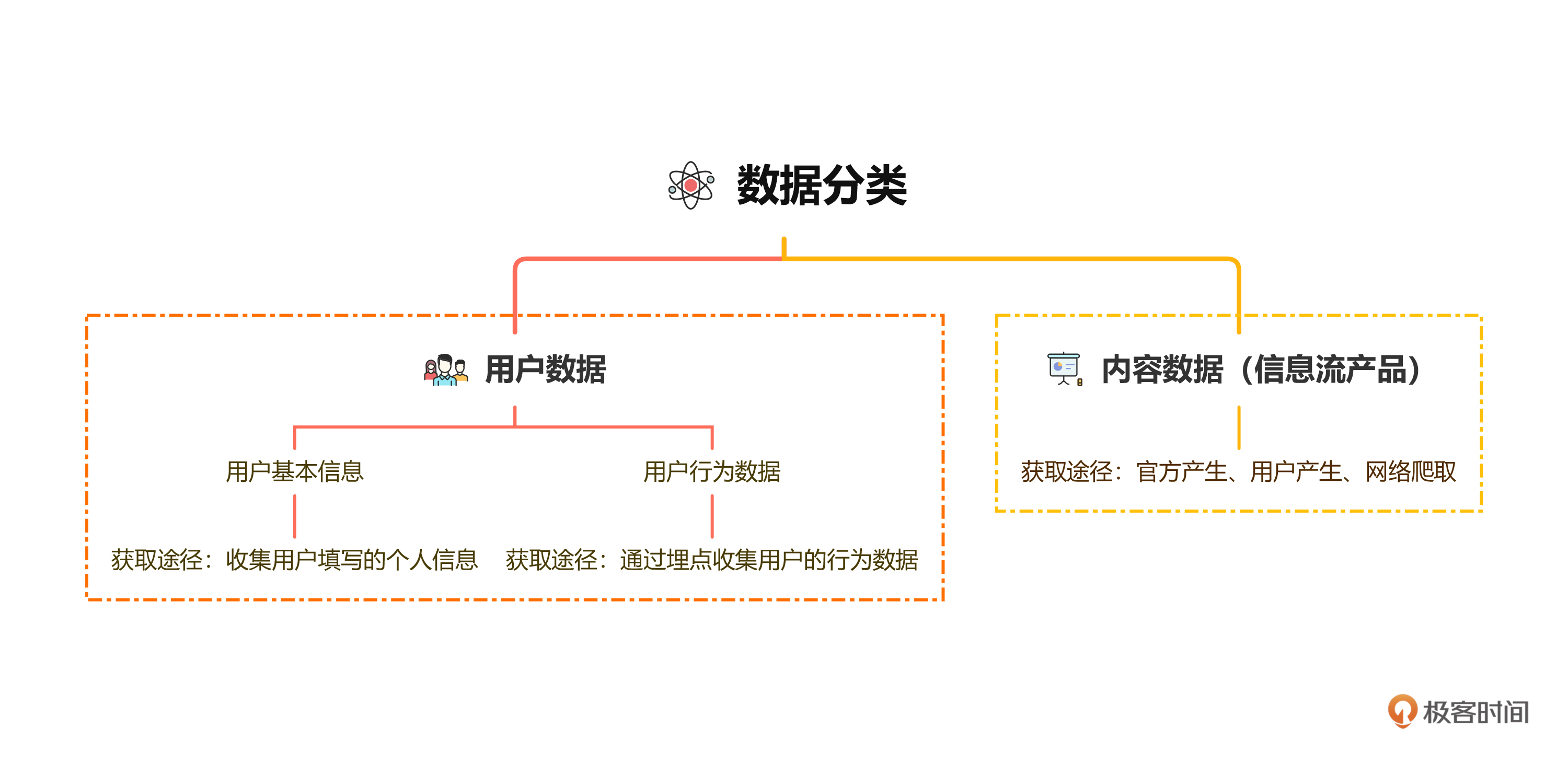
推荐系统的数据获取和处理是推荐系统开发中的关键环节。本文详细介绍了数据获取方式、数据具体形态和数据处理方法。首先,介绍了用户数据和内容数据的获取渠道和形态,包括用户属性数据、用户行为数据和内容数据的获取方式和具体信息组成。其次,针对不同的数据类型,提出了使用NLP、机器学习和统计学等不同方法进行数据处理的方案。文章强调了NLP在信息流推荐系统中的重要性,以及机器学习和统计学在特征处理中的不可替代作用。最后,总结了数据处理对于后续推荐算法的重要性。整体而言,本文为读者提供了全面的技术指导,详细介绍了推荐系统中数据获取和处理的关键内容。
《手把手带你搭建推荐系统》,新⼈⾸单¥59

全部留言(4)
- 最新
- 精选
 欢少の不忘初心电商系统,博客系统 电商需要用户的浏览记录,购买记录,性别,商品的相似性信息 博客需要用户的浏览记录,点赞,评论,收藏,关键字,技术栈,喜好
欢少の不忘初心电商系统,博客系统 电商需要用户的浏览记录,购买记录,性别,商品的相似性信息 博客需要用户的浏览记录,点赞,评论,收藏,关键字,技术栈,喜好作者回复: 是的,理解的很对,针对不同的系统要学会变通。
2023-04-30归属地:江苏1 peter请教老师几个问题: Q1:内容的质量怎么确定? Q2:开发一个新闻APP,用爬虫爬取内容后用在自己的APP上,会有法律或版权纠纷吗? Q3:推荐系统可以利用chatGPT吗?
peter请教老师几个问题: Q1:内容的质量怎么确定? Q2:开发一个新闻APP,用爬虫爬取内容后用在自己的APP上,会有法律或版权纠纷吗? Q3:推荐系统可以利用chatGPT吗?作者回复: 答:同学你好。首先,对于一个推荐系统来讲,内容的质量有几种不同的判别方式,比如人工判断,分类,以及通过优质的内容产出者进行辅助判断等。所谓的人工判断,就是由专业的审核人员对内容进行审核,从而判断质量;分类的话实际上就是把优质的内容和普通的内容提前打上标签,然后再造出一批数据集后,训练一个文本分类的模型;还有第三种方式就是很多信息流推荐系统,都会找一些优质的写手或者官方的运营人员进行写作,这部分的内容我们一般也会认为是优质的内容。 关于爬虫爬取是否有法律纠纷主要是看你的爬虫程序是否遵循了网站的robots协议,一般来讲,如果遵循其协议,不会产生纠纷。但是如果你把这些内容进行商用的话,要看对方有没有版权要求,一般来讲是需要征求原作者的同意后才可以。 推荐系统在某些情况下可以和ChatGPT进行结合,但是这样需要在ChatGPT上写很多prompt才可以完成。
2023-04-16归属地:北京
 徐石头1. 短视频内容,需要用户昵称/性别/唯一标识/ip/地址,用户点赞,收藏,评论,分享,视频时长,完播率,平均播放时长,视频分类,关键词,标签,视频地区。 另外我想强调一下视频封面,封面是用户对视频的第一印象,所以可以生成同一个视频的不同封面图推荐给不同用户,字体/颜色/内容关键字,根据用户点击和观看进行优化,具体还没实践过。 另外根据同一类用户关注的大V进行推荐,按用户之间粉丝交集关系进行推荐,A跟B都关注了C,A关注D,B没有,是不是可以给B推荐D。 2. 没有头绪,不知道从哪里下手,希望老师给答案
徐石头1. 短视频内容,需要用户昵称/性别/唯一标识/ip/地址,用户点赞,收藏,评论,分享,视频时长,完播率,平均播放时长,视频分类,关键词,标签,视频地区。 另外我想强调一下视频封面,封面是用户对视频的第一印象,所以可以生成同一个视频的不同封面图推荐给不同用户,字体/颜色/内容关键字,根据用户点击和观看进行优化,具体还没实践过。 另外根据同一类用户关注的大V进行推荐,按用户之间粉丝交集关系进行推荐,A跟B都关注了C,A关注D,B没有,是不是可以给B推荐D。 2. 没有头绪,不知道从哪里下手,希望老师给答案作者回复: 同学你好,正如你所说,一般来讲,短视频内容的画像相比于信息流文章来讲,更注重的是视频的播放完成度、视频时长、平均播放时长等,所以我们在构建内容画像的时候,应该着重去注意这几个点的特征处理,要去想,这些点应该用连续的特征还是离线的特征比较好,另外就是这类特征需要怎么去表达,才能更好的把握住重点。 封面的确是在视频推荐中最重要的一个点,对于封面特征的提取一般会用到图像特征提取的一部分,然后再根据图像的特征来进行封面的提取。另一方面,有一个简单的办法,就是把比较热门的内容的封面和普通内容的封面做一个特征或者图片的分类,也许也能找到一些比较好的特征分类点,这里面其实就不限于文字的颜色、大小和排版等。 关于你说的大V推荐的方法,其实就是协同过滤中的一部分,在后面的章节中你会看到这一部分的内容。
2023-04-14归属地:湖南 👂🏻阿难👂🏻这节内容是我比较关注的,我浏览完全篇后,对这节课的理解和定位是数据获取-数据“预处理”的一个导引。 数据处理在一个成熟商用的推荐系统按照我的理解应该是有至少:“事前-事中-事后”三部分的。这节内容更多的是在讲事前这个阶段。 那么事中:也就是训练推荐引擎,的阶段数据是如何在不同的组键和模块只用吊起,传输,存储的呢?这些组键分别支持什么样形式/格式的数据?处理完会存储在哪里?为什么要这么存储? 事后:也就是模型离线训练完成如何做预测?预测的数据形式是什么样子?是key value对吗?训练好的模型参数如何部署?为了线上大规模实时/近实时预测?什么样的数据格式更优?接口传输的数据又是如何定义,存储,流转? 希望这些唯独都能被老师和课程负责人关注到,这些对于一个完整的学习框架搭建才是有价值的。谢谢2023-05-31归属地:上海
👂🏻阿难👂🏻这节内容是我比较关注的,我浏览完全篇后,对这节课的理解和定位是数据获取-数据“预处理”的一个导引。 数据处理在一个成熟商用的推荐系统按照我的理解应该是有至少:“事前-事中-事后”三部分的。这节内容更多的是在讲事前这个阶段。 那么事中:也就是训练推荐引擎,的阶段数据是如何在不同的组键和模块只用吊起,传输,存储的呢?这些组键分别支持什么样形式/格式的数据?处理完会存储在哪里?为什么要这么存储? 事后:也就是模型离线训练完成如何做预测?预测的数据形式是什么样子?是key value对吗?训练好的模型参数如何部署?为了线上大规模实时/近实时预测?什么样的数据格式更优?接口传输的数据又是如何定义,存储,流转? 希望这些唯独都能被老师和课程负责人关注到,这些对于一个完整的学习框架搭建才是有价值的。谢谢2023-05-31归属地:上海

