

07|数据获取:什么是Scrapy框架?

Scrapy 框架概览

 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

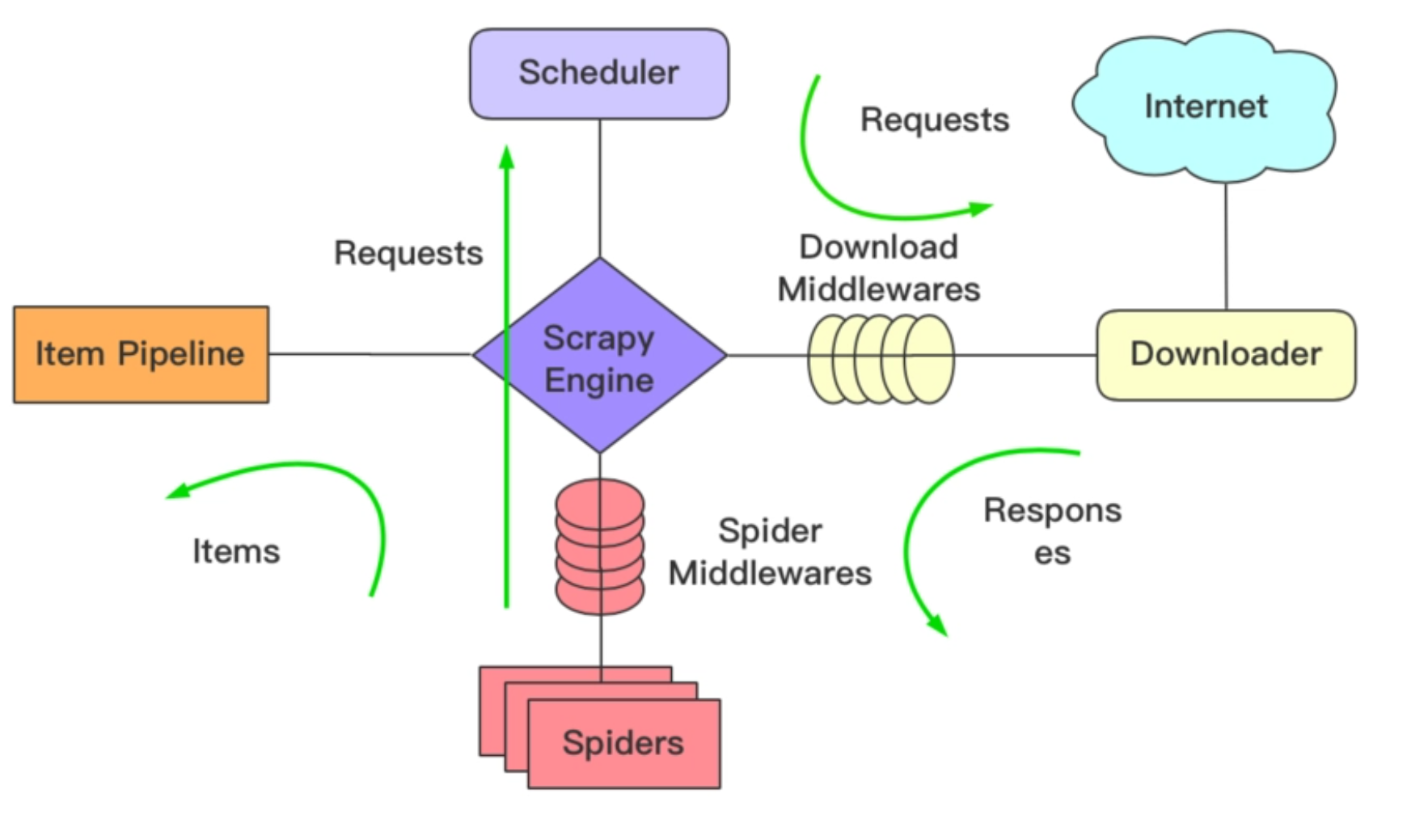
Scrapy框架是一个适用于Python的快速、高层次的屏幕抓取和Web抓取框架,用于抓取Web站点并从页面中提取结构化的数据。它提供了多种类型爬虫的基类,如BaseSpider、Sitemap爬虫等。Scrapy框架的架构包括Scrapy Engine、Scheduler、Downloader、Spiders、Item Pipline、Downloader Middlewares和Spider Middlewares。工作流程主要包括爬虫程序向引擎索要待爬取的URL、调度器将URL加入队列、下载器下载请求并返回response、Spider处理response并提取数据、以及Item Pipeline存储数据。安装Scrapy框架需要先安装Anaconda环境,然后使用pip install scrapy命令即可。Anaconda环境可以看作是一个常用的扩展库的集合,可以轻松地管理扩展库和创建多个虚拟环境。 在文章中,作者详细介绍了如何使用Scrapy框架创建爬虫开发环境。首先,作者指导读者在指定目录下创建Scrapy工程,并将项目导入到IDE环境中。然后,作者介绍了如何创建爬虫程序,包括创建爬虫文件和安装ChromeDriver插件。最后,作者展示了如何编写主文件并运行爬虫程序。通过本文,读者可以了解Scrapy框架的基本原理和主要模块,以及在Anaconda环境中创建和运行Scrapy框架的基本步骤。 总的来说,本文通过实际操作的方式,帮助读者快速了解了Scrapy框架的基本概念和使用方法,为读者提供了一份实用的技术指南。
《手把手带你搭建推荐系统》,新⼈⾸单¥59

全部留言(10)
- 最新
- 精选
- Geek_79da7f关于安装ChromeDriver, mac上面一个命令行就解决了: brew install chromedriver
作者回复: 同学你好,感谢您提交的信息。
2023-09-18归属地:美国22  未来已来遇到一个报错:Failure while parsing robots.txt. 解决:把 settings.py 文件的 `ROBOTSTXT_OBEY = True` 改为 `ROBOTSTXT_OBEY = False` 即可
未来已来遇到一个报错:Failure while parsing robots.txt. 解决:把 settings.py 文件的 `ROBOTSTXT_OBEY = True` 改为 `ROBOTSTXT_OBEY = False` 即可作者回复: 是的,如果是被robot文件给挡住了,可以通过修改ROBOTSTXT_OBEY 来改变爬虫的规则,使其不遵循robots协议。
2023-05-03归属地:广东21 peter请教老师几个问题啊 Q1:网站后端是用Java开发的,可以用Scrapy来抓取数据吗?相当于两种语言的混合使用了。 Q2:Anaconda安装的最后一步提示是“python3.9”,为什么创建虚拟环境的时候python版本是3.7? Q3:安装的这个Anaconda,是正常的python开发环境吧。比如用来学习python,编码等。 Q4:conda list命令列出的scrapy,其build channel是py37XXX, 其中的37是python版本吗?
peter请教老师几个问题啊 Q1:网站后端是用Java开发的,可以用Scrapy来抓取数据吗?相当于两种语言的混合使用了。 Q2:Anaconda安装的最后一步提示是“python3.9”,为什么创建虚拟环境的时候python版本是3.7? Q3:安装的这个Anaconda,是正常的python开发环境吧。比如用来学习python,编码等。 Q4:conda list命令列出的scrapy,其build channel是py37XXX, 其中的37是python版本吗?作者回复: 同学,你好,我来回答你的问题: A1:Scrapy是Python的爬虫框架,不是Java,所以不能直接用Scrapy来抓取Java开发的网站,但是你可以看看在Java上有没有想过的框架,原理都是一样的。 A2:因为Anaconda安装程序默认使用了Python 3.9,但在创建虚拟环境时选择了Python 3.7,所以你看到的虚拟环境版本是3.7,虚拟环境的版本可以独立于主环境的,这个没有影响。 A3:是的,是正常的Python开发环境,可以直接使用。 A4:是的,conda list命令列出的scrapy中的build channel中的37表示Scrapy依赖的Python版本为3.7。在安装Scrapy时需要使用与Python版本兼容的Scrapy版本。
2023-04-24归属地:北京31 Weitzenböck我在执行main函数的时候出现了这个错误"UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc3 in position 93: invalid continuation byte",是不是https://sina.com.cn这个网站没有用utf-8的编码格式啊
Weitzenböck我在执行main函数的时候出现了这个错误"UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc3 in position 93: invalid continuation byte",是不是https://sina.com.cn这个网站没有用utf-8的编码格式啊作者回复: 应该是掺杂了特殊字符,你可以再检查下
2023-06-14归属地:江苏5 地铁林黛玉爬取的这些数据我们需要通过哪些方法知道是不是违法的呢?
地铁林黛玉爬取的这些数据我们需要通过哪些方法知道是不是违法的呢?作者回复: 同学你好。一般来讲,在settings.py文件里有一个参数叫ROBOTSTXT_OBEY,这个文件默认为True,也就是遵循网站的robots协议,如果在true的状态下请求被拒绝,说明不能去爬取。当然,你也可以设置为Fales,也就是无视它的规则进行爬取,那么这个时候,其实就有一点违规的意思了。
2023-05-04归属地:北京4 GhostGuest更新建议改为一天一更,现在这节奏太慢了,前摇半天
GhostGuest更新建议改为一天一更,现在这节奏太慢了,前摇半天作者回复: 同学你好,非常感谢你对我的课程的关注和反馈。我理解你想尽快得到更多的内容,但我的更新频率已经是我的最大努力了,因为我需要花费时间和精力来研究和准备每个更新的内容。在你们学习课程的同时,我也在每天写课、改稿和回复同学的留言到深夜。 另外,我需要时间尽量保证内容和代码的精细化,保证其质量,这样对读者才是最好的回馈。
2023-04-24归属地:上海2 叶圣枫我的macbook上会报这个错: urllib3 v2.0 only supports OpenSSL 1.1.1+, currently the 'ssl' module is compiled with 'OpenSSL 1.0.2u 20 Dec 2019 解决方案是降级urllib3: pip install urllib3==1.26.62024-01-12归属地:上海2
叶圣枫我的macbook上会报这个错: urllib3 v2.0 only supports OpenSSL 1.1.1+, currently the 'ssl' module is compiled with 'OpenSSL 1.0.2u 20 Dec 2019 解决方案是降级urllib3: pip install urllib3==1.26.62024-01-12归属地:上海2 李老师出现这个错误是什么原因2024-02-18归属地:浙江
李老师出现这个错误是什么原因2024-02-18归属地:浙江 悟尘chrom 114 版本以上的 下载chromedriver在这里:https://registry.npmmirror.com/binary.html?path=chrome-for-testing/2023-12-11归属地:北京
悟尘chrom 114 版本以上的 下载chromedriver在这里:https://registry.npmmirror.com/binary.html?path=chrome-for-testing/2023-12-11归属地:北京- 悟尘[scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (301) to <GET https://www.sina.com.cn/> from <GET https://sina.com.cn> [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.sina.com.cn/> (referer: None) 这算是连上了?2023-12-11归属地:北京

