

20 | 推荐引擎:没有搜索词,“头条”怎么找到你感兴趣的文章?

该思维导图由 AI 生成,仅供参考
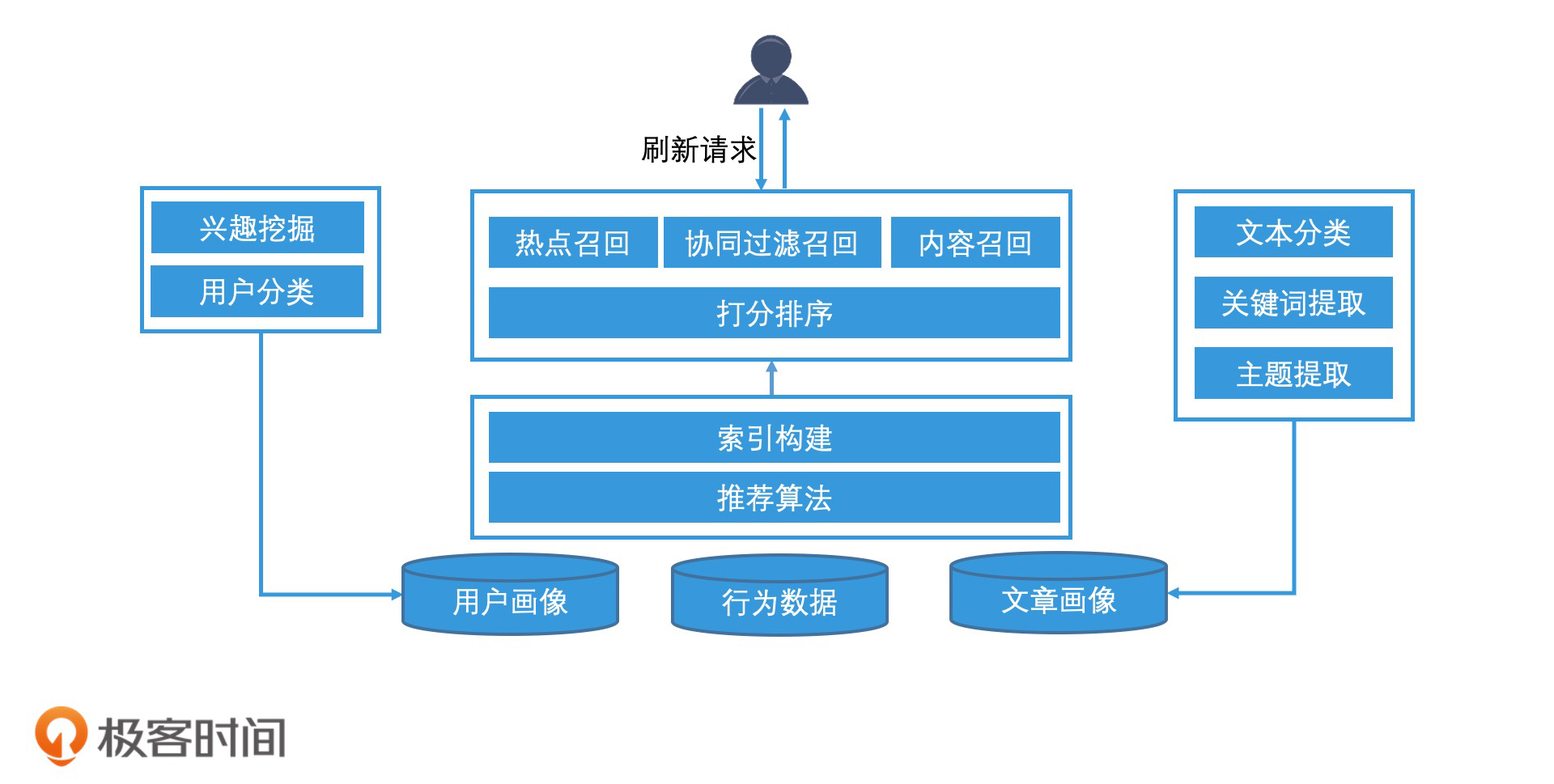
推荐引擎的整体架构和工作过程
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

推荐引擎在资讯类App中的应用通过收集用户行为数据、挖掘用户兴趣和生成用户画像,以及对文章进行语义分析和生成文章画像,实现了个性化推荐。文章介绍了基于协同过滤的召回算法,包括基于用户的协同过滤和基于物品的协同过滤。基于用户的协同过滤通过寻找相似用户并推荐其喜欢的文章,而基于物品的协同过滤则是找出用户喜欢的物品并进行推荐。推荐引擎采用混合推荐法,结合多种召回技术,并使用分层打分过滤的排序方式来解决大量候选集的排序计算代价问题。最终,推荐引擎通过非精准打分算法、机器学习模型和精准的深度学习模型,选出最终的推荐结果。总的来说,推荐引擎实现了在没有搜索词的情况下,为用户推荐感兴趣的文章,为资讯类App的用户提供了个性化的阅读体验。文章还讨论了基于内容的召回和基于协同过滤的召回的特点,以及混合推荐法和多层打分过滤的应用。
《检索技术核心 20 讲》,新⼈⾸单¥59

全部留言(6)
- 最新
- 精选
 奕将第一步“寻找每个物品的相似物品列表”放在离线环节。具体的操作是以 Item ID 为 Key,以相似物品列表为 posting list,来生成倒排索引,再把它存入线上的 Key-value 数据库中 --------------------------------- 利用这种方法的时候,每个item 都会生成一个 posting list, 这样的每个商品都会保存 n 分,这样会不会浪费空间?
奕将第一步“寻找每个物品的相似物品列表”放在离线环节。具体的操作是以 Item ID 为 Key,以相似物品列表为 posting list,来生成倒排索引,再把它存入线上的 Key-value 数据库中 --------------------------------- 利用这种方法的时候,每个item 都会生成一个 posting list, 这样的每个商品都会保存 n 分,这样会不会浪费空间?作者回复: 如果每个posting list都存了所有的商品,的确会比较浪费空间,而且其实也没必要,因为最后只会选取top k个。因此,我们可以对posting list进行截断,仅保留相似度超过一定阈值的item就好了。这样就能大幅减少空间。
2020-05-172- 奕我们就要先找出最接近的 k1 个 Item 向量,然后用 Item 1 对 User1 的权重乘上每个 Item 和 Item 1 的相似度, -------------------------- 这个应该是: 每个 Item 对 User1 的权重乘上每个 Item 和 Item 1 的相似度
作者回复: 并不是哦。在基于物品的协同过滤中,对于要推荐的item,我们之前并不知道这个item和user1有什么关系,我们知道的是两个信息: 一个是user1对item1的打分(记为w),另一个是item1和item的相似度(记为s),因此,user1和item的相关性,就是w*s
2020-05-171  易企秀-郭彦超假如user1评价过item1与item2而通过基于物品的协同过滤得到item1与item2都与item3相似,那么user1对item3的打分是如何计算的?
易企秀-郭彦超假如user1评价过item1与item2而通过基于物品的协同过滤得到item1与item2都与item3相似,那么user1对item3的打分是如何计算的?作者回复: 我的文中有写: 要查找和 Item 1 相似的物品,我们就要先找出最接近的 k1 个 Item 向量,然后用 Item 1 对 User1 的权重乘上每个 Item 和 Item 1 的相似度,就能得到这 k1 个 Item 的推荐度。 同理对于 Item 2,我们也可以找出 k2 个 Item,并计算出这 k2 个 Item 的推荐度。最后,我们将 k1 个 Item 和 k2 个 Item 进行合并,将相同 Item 的推荐度累加,就能得到每个 Item 对于 User 1 的推荐度了。
2021-01-28- 易企秀-郭彦超多路召回的结果是如何排序的 热点与模型的后选列表排序纬度是什么
作者回复: 所有的结果放一起排序的时候,其实就涉及到前面介绍过的机器学习排序的思想了。机器学习会基于大量的维度,进行综合排序打分。
2021-01-28  范闲1.关于第一个问题,其实有点疑问。每个item的向量实际上是不同用户偏好构成的。最终对不同item求出来实际上对于某个item,用户偏好相近的程度 2.整体技术上的架构是类似的,但是在场景上区分很大。
范闲1.关于第一个问题,其实有点疑问。每个item的向量实际上是不同用户偏好构成的。最终对不同item求出来实际上对于某个item,用户偏好相近的程度 2.整体技术上的架构是类似的,但是在场景上区分很大。作者回复: 1.第一个问题,的确,最后针对某个用户推荐的时候,我们是需要具体计算和这个指定用户的相关性的。不过我在文中也说过,item based方案的实现会分为两部分,第一部分是离线构建起相似item的倒排表,第二部分才是在线上环节,根据具体用户,找出推荐item。我在这道题中,其实只要求做第一步,给出每个item对应的posting list即可。如果你想把第二步对具体用户推荐也完成的话,可以以用户1为例子,看看会推荐出什么item。
2020-05-15- 知错正在改老师老师😭,我输入检索错了2023-12-06归属地:广东