

18 | 搜索引擎:输入搜索词以后,搜索引擎是怎么工作的?

该思维导图由 AI 生成,仅供参考
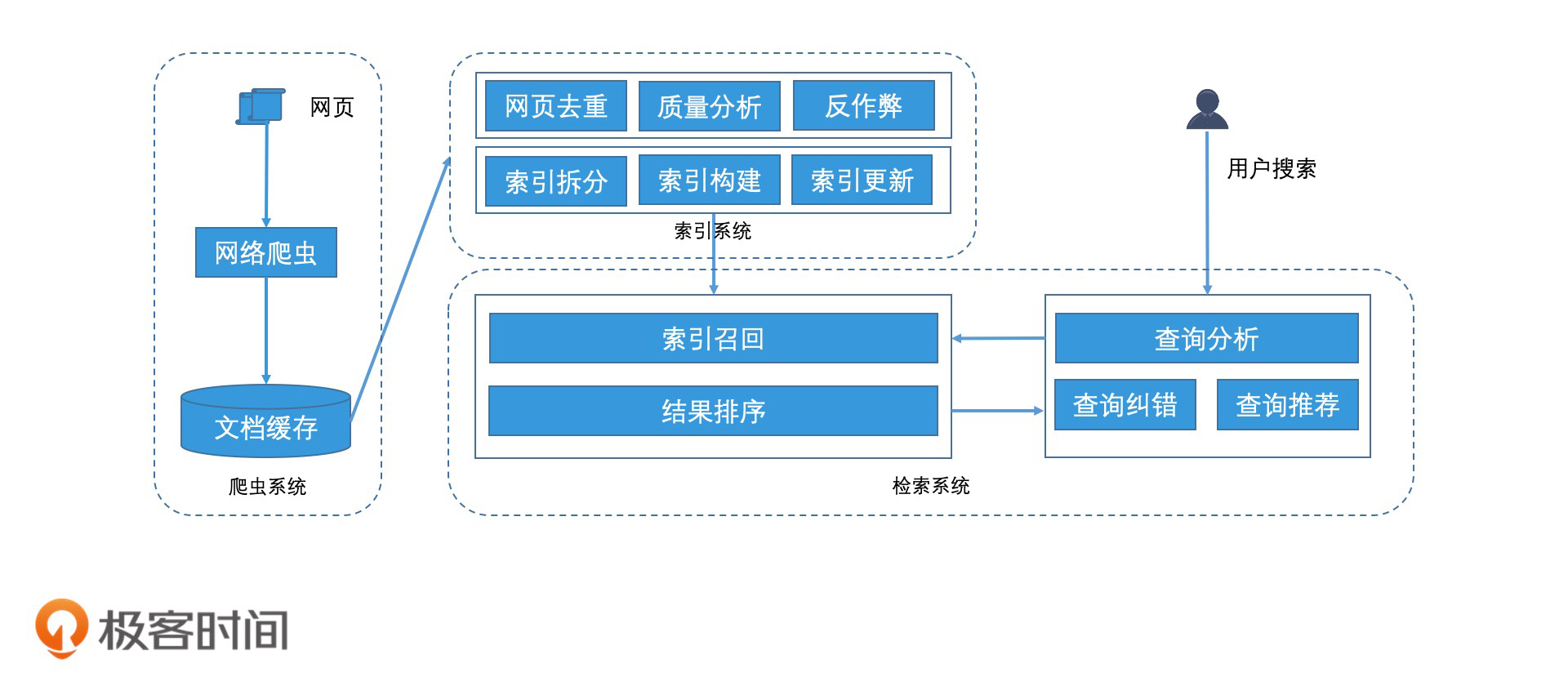
搜索引擎的整体架构和工作过程
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

搜索引擎是当今学习和工作中不可或缺的工具,它能在海量网页中快速找到所需信息。搜索引擎的核心架构包括爬虫系统、索引系统和检索系统。文章详细介绍了搜索引擎的工作过程和查询分析的重要性,展现了搜索引擎技术的复杂性和关键性。在查询分析中,搜索引擎会进行分词粒度分析、词的属性分析和用户需求分析,以理解用户意图并提供准确的搜索结果。此外,文章还介绍了搜索引擎如何进行查询纠错和查询推荐,以及搜索引擎如何完成短语检索的过程。通过查询分析、查询纠错、查询推荐的过程,搜索引擎能对用户的意图有一个更深入的理解。整体而言,搜索引擎的业务特点非常依赖用户输入的查询词,因此,对查询词进行特殊处理技术至关重要。文章还提到了位置信息索引法在短语检索中的应用,以及对搜索结果中最小窗口的长度排序的重要性。这些技术不仅适用于搜索引擎,也可以应用于广告系统和推荐系统中。
《检索技术核心 20 讲》,新⼈⾸单¥59

全部留言(11)
- 最新
- 精选
- 李老师有没有爬虫或者搜索方面的书籍推荐的
作者回复: 搜索引擎方面的书籍,其实《信息检索导论》是可以作为基础学习的。因为其中一个作者就是Google的副总裁,书中就以搜索引擎为例子。包括还有《搜索引擎:信息检索实践》。 国内还有《这就是搜索引擎:核心技术详解》这类书籍,都可以看看。 至于网络爬虫,这更偏向于实践和工程。可能要结合你使用的编程语言。比如说Python的scrapy,或者Java相关的网络爬虫书籍。
2020-05-176  那时刻请问老师,我们经常听说的page rank算法在搜索引擎中是怎么具体应用的?
那时刻请问老师,我们经常听说的page rank算法在搜索引擎中是怎么具体应用的?作者回复: page rank是Google很重要的一个专利,不过它的核心思想其实不复杂。它通过分析不同网页之间的相互链接关系,来判断网页的质量。打个比方,就像论文引用一样,被大量高质量论文引用的论文,应该也是高质量论文。page rank就是通过这样的方式,对每个网页赋予了一个质量分。 那具体会在哪些环节使用page rank质量分呢? 1.在进行索引分层时,高质量网页和普通质量网页需要区分,这时候page rank质量分就是一个很重要的参考。 2.打分排序阶段,page rank质量分也是很重要的因子。 3.在进行锚文本分析时,高质量网页出来的锚文本更重要。 4.在爬虫抓取网页时,可以优先抓取高质量的网页链接出来的网页。 以上是我想到的一些场景,供参考
2020-05-1126- 林苏荣首先,感谢老师这么多课程的专业讲解。这些课程都是从很基础的原理开始,构建出整个技术架构。请问老师,在实际工业的应用中,是否都是基于这些基础原理,结合具体的业务场景做组合优化来实现。还是有其他更加专业的算法优化和设计呢?毕竟光是考虑搜索引擎所涉及的数据量就已经是天文数字了,再考虑各种处理逻辑,,,依据这些基础原理真的足以应对吗?还是一个老套路,性能不够机器来凑^O^,用超大规模的集群来完成的,谢谢。
作者回复: 其实复杂的系统都是由简单的子系统和技术构成的。 架构设计的目的,就是希望能将复杂系统拆解成更简单的子系统,使得我们可以更容易去开发实现。 而在子系统中,在我们了解了对应的原理和解决方案以后,我相信开发起来会容易上手得多。 当然,技术也是一直在进化的,专业的技术和算法优化肯定也是一直在前进。比如说排序算法,就从bm25到机器学习再到深度学习,这就是典型的例子。工业系统中的具体优化细节有很多,肯定不是一个专栏能写得完的。但这些新技术的根源还是从原理和解决问题出发演化出来的。因此,我们要更好地去理解原理和场景,这能帮助我们更好地理解和学习新技术。 还有,关于是否堆机器的问题,现在许多大型系统都是采用分布式架构,一个好处就是可以堆机器,大家也的确都会堆机器。但是我们也不能无脑堆机器。比如说,网页的数量每年增长30%,那难道搜索引擎的服务器就要每年加30%?这是不现实的。因此,我们需要使用分层索引的设计,来保证我们不需要堆太多的机器。
2020-05-165  范闲先固定第一个词,然后找第二个词的距离。第二个词距离固定以后,找第三个词和第二个词的距离。
范闲先固定第一个词,然后找第二个词的距离。第二个词距离固定以后,找第三个词和第二个词的距离。作者回复: 是的。这其实是一个贪心算法。局部最优一定是全局最优。 首先,第一个词可能会出现在n个位置。我们遍历第一个词的所有位置。 然后,当第一个词固定位置时,我们寻找这个位置后面的最近的第二个词的位置。这样就能固定第二个词的位置。 接着,在第二个词固定以后,我们再在第二个词后面,找最近的第三个词的位置。那么,这个位置和第一个词的位置结合,就是这次计算得到的最小窗口长度。(之所以说是贪心算法,是因为我们不需要穷举所有第二个词和第三个词的位置组合,而是只需要找最近的就可以了) 然后我们把第一个词的这n个位置的最小窗口长度都算出来,取最小的一个,就得到了最终结果。 当然,在求第一个词的n个位置的n个最小窗口的过程中,我们还能利用之前计算的结果。比如说第一个词的第二个位置,其实也在第二个词的前面,那么第二个词的位置不用变,第三个词的位置也不用变了。 整体来说,你会看到,位置信息索引法,计算代价会比较大,因此,对于热门短语,能直接作为key加入倒排索引是更高效的。
2020-05-115 李小龙老师公司怎么从零搭建搜索
李小龙老师公司怎么从零搭建搜索作者回复: 如果是从零开始,进行文本搜索的话,最简单的做法是使用MySQL的全文检索功能,但是效果会比较差。 如果想更精准地进行关键词检索,那么可以使用elastic search来搭建你们的系统。当然,如果想定制各种功能,那么可以走上自研的方向。
2020-06-1043- dakingkong老师,请问下Leveldb,是一写多读的吗?内存中的memtable在一写多读时,需要加锁吗?
作者回复: 不需要加锁。memtable使用了巧妙的无锁设计,使得性能能更优。
2021-09-071 - 那时刻关于第一个讨论题,开始的想法,使用位置信息索引法中,对于3个关键词的情况,可以锁定第一个关键词,找到最小窗口的第二关键词,然后锁定这个第二个关键词,寻找最小窗口的第三个关键词。但是老师文章中提到`如果是两个以上的关键词联合查询,那我们会将同时包含所有关键词的最小片段称为最小窗口`,这个方法貌似跟这句话相违背。举个栗子,假设这三个关键词是A B C,某一篇文章中有两处含有这三个关键词,他们之间最小窗口距离是 A1~2~B1~5~C1 (A1和B1之间距离是2,B1和C1之间距离是5), A2~3~B2~3~C2。按照开始想法的解法是,锁定A,找到最小窗口的B,是B1,因最小距离是2。然后锁定B1,找到最小距离是C1(假设B1和C2之间距离远大于5)。但是单独看B和C之间的距离,B2与C2应该是最小的。另外,如果看包含所有关键词的话,A2 B2 C2之间最小窗口是最优的,如此的话,得使用动态规划方法来计算了,但是这样一来复杂度变高了。
作者回复: 其实不需要动态规划法,使用贪心法就够了。 首先我们算出来锁定A1时的最小窗口。然后我们再去计算当第一个关键词取A2位置时的最小窗口。 在计算A2的最小窗口的时候,我们可以先判断A2的位置是否小于B1,如果小于的话,那么最小窗口就是A2-B1-C1。如果A2大于B1的话,那么就重新往后找到B2。以此类推。这样,对于每个关键词的位置,我们都不会回头重复计算。
2020-05-1141  森森森老师如果使用深度学习进行排序,那么深度学习的线上预测模型是需要在搜索的排序阶段进行接口调用就可以了吗?
森森森老师如果使用深度学习进行排序,那么深度学习的线上预测模型是需要在搜索的排序阶段进行接口调用就可以了吗?作者回复: 一般来说,我们会采用微服务架构来搭建系统。系统中有一个排序模型的服务,专门负责排序功能。这个服务可以使用逻辑回归模型来实现,也能使用深度学习模型,但是不管内部怎么实现,对外提供一个统一的服务接口即可。
2020-11-02 奕在进行查询次窗口计算的时候:是只计算查询词的第一个词和最后的一个词的距离吗? 还是计算查询词中两两词之间的的距离? 我认为计算查询次中两两词之间的窗口距离推荐的效果会更好一些
奕在进行查询次窗口计算的时候:是只计算查询词的第一个词和最后的一个词的距离吗? 还是计算查询词中两两词之间的的距离? 我认为计算查询次中两两词之间的窗口距离推荐的效果会更好一些作者回复: 在标准的短语查询中,窗口的定义就是第一个词到最后一个词的距离。 你提出的两两之间的距离也是有意思的一个提法,也许在某些场景下是有效的,不过这样的判断可能会造成第一个词和最后一个词距离太远,在短语查询这个例子中可能不是很合适。
2020-05-11 ifelse
ifelse 学习打卡2023-04-20归属地:浙江1
学习打卡2023-04-20归属地:浙江1