

15 | 最近邻检索(上):如何用局部敏感哈希快速过滤相似文章?

该思维导图由 AI 生成,仅供参考
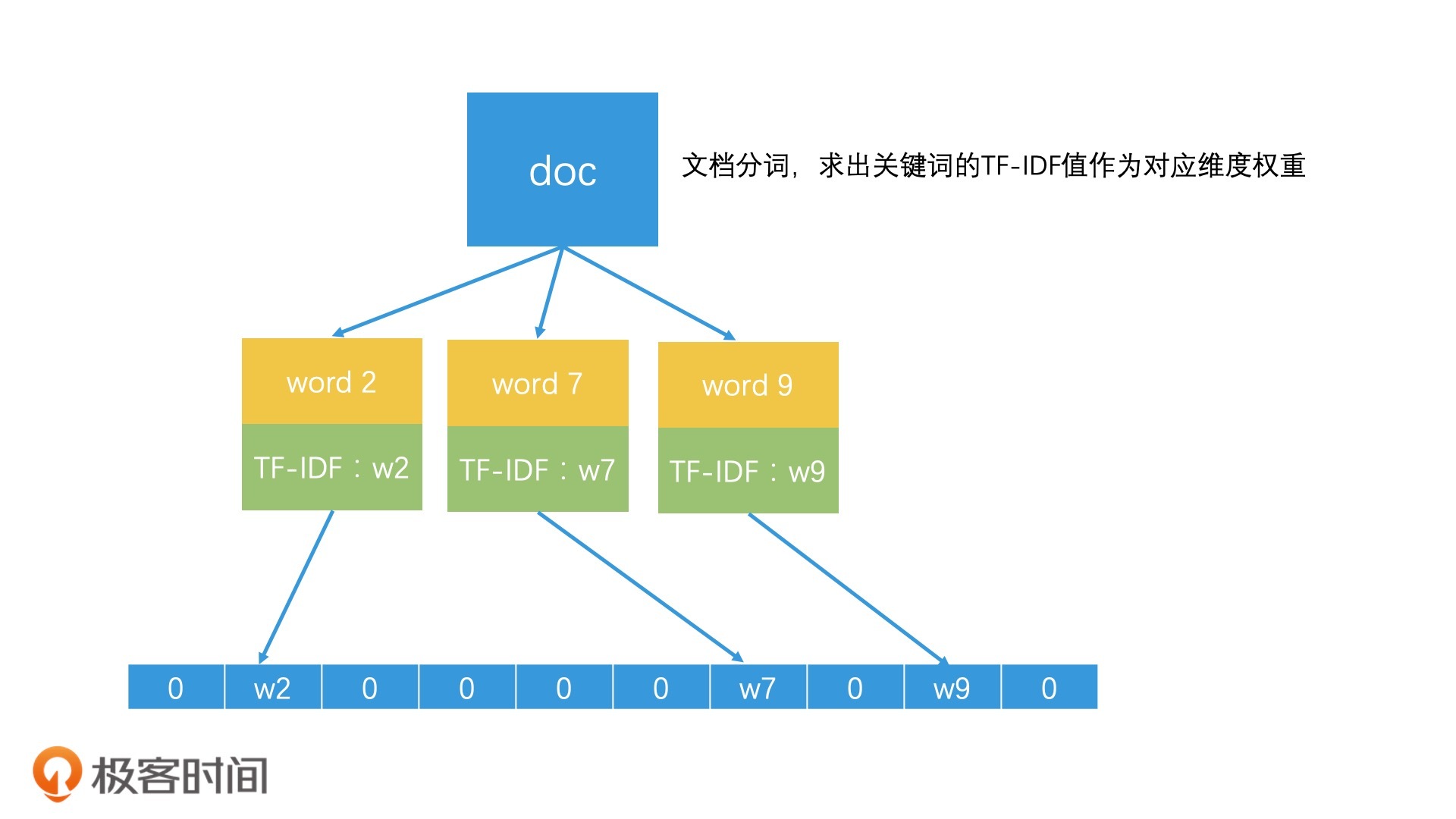
如何在向量空间中进行近邻检索?
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

局部敏感哈希(Locality-Sensitive Hashing)是一种用于快速过滤相似文章的技术。文章首先介绍了向量空间模型的基本概念,即将文档表示为n维向量,并介绍了传统的k-d树检索效率下降的问题。随后详细介绍了局部敏感哈希的原理和应用,通过随机生成超平面,将高维空间的点映射到低维空间的一维编码,实现高效的相似文章检索。SimHash是一种简单有效的局部敏感哈希函数,能保留关键词的权重,并通过海明距离进行相似检索。文章还介绍了使用抽屉原理设计的更高效的检索方法,将哈希值平均切分为4段,以每一段的比特位值作为Key,建立倒排索引,从而实现高效检索。总结指出局部敏感哈希不仅适用于相似文章检索,还可应用于图像检索等领域。然而,对于语义相似的推荐系统,局部敏感哈希存在局限性。最后,文章提出了两个课堂讨论问题,引发读者思考。
《检索技术核心 20 讲》,新⼈⾸单¥59

全部留言(17)
- 最新
- 精选
 paulhaoyi感觉局部敏感hash和深度学习中的embedding好相近啊,都是临近点的向量表示很相近。不知道应用中有没有相互替换的场景。
paulhaoyi感觉局部敏感hash和深度学习中的embedding好相近啊,都是临近点的向量表示很相近。不知道应用中有没有相互替换的场景。作者回复: 你说的很对。其实局部敏感哈希和embedding,都是对高维空间的点进行降维,用更低维的向量来表示,但又要保留原来的核心特征。从这个角度来说,它们的思路是一致的。 你可以认为局部敏感哈希是基于规则的embedding。因此在一些应用中,是有可能可以替换使用的。
2020-04-3011 那时刻与simHash类似的还有个minHash,查了资料对比了下,貌似是minHash对于权重处理不是很好,而且处理时候因为要计算多个hash函数,占用更多CPU资源,而superminhash在处理速度上更胜一筹。不知理解是否正确? 讨论问题: 1. 最开始想法是对于4位不同,采用5段分割,但是对于64bit,5段不能整除。可以增大分割的段数,可采用8段分割来计算。 2. 暂时没想到其它具体应用
那时刻与simHash类似的还有个minHash,查了资料对比了下,貌似是minHash对于权重处理不是很好,而且处理时候因为要计算多个hash函数,占用更多CPU资源,而superminhash在处理速度上更胜一筹。不知理解是否正确? 讨论问题: 1. 最开始想法是对于4位不同,采用5段分割,但是对于64bit,5段不能整除。可以增大分割的段数,可采用8段分割来计算。 2. 暂时没想到其它具体应用作者回复: minhash的确也是另一种局部敏感哈希算法。它是基于Jaccard距离的一种算法。而不是基于余弦距离。因此它更适合做集合相似度这类的判断。 包括计算过程的确比simhash更复杂。 关于课后题: 1.根据抽屉原理,的确使用五段以上的分割都可以。不能整除其实问题不大,不过考虑到代码简洁性和空间平衡划分,分成8段是不错的答案。 2.其实我文中已经举了一个例子,就是判断图片相似度,我们可以将每个维度的特征取出,用Simhash的思路进行处理即可。因此simhash不仅仅可用于文章相似度判断,而是可以用于抽象的物品相似度判断。
2020-04-2910 奕对于思考题: 1:利用抽屉性原理,可以分为 5段保证,至少有一段是相等的,但是我看下面的老师评论说,最好分为 8段,但是这样的话相似度准确性是不是会降低很多? 因为分为 8段 的话至少要有 4个是相等的, 还是分为8段的时候进行了特殊处理? 2: 还可以对其他东西,比如图片,歌曲进行特征向量提取,再利用局部敏感哈希函数,这里还不用考虑语义上的相似
奕对于思考题: 1:利用抽屉性原理,可以分为 5段保证,至少有一段是相等的,但是我看下面的老师评论说,最好分为 8段,但是这样的话相似度准确性是不是会降低很多? 因为分为 8段 的话至少要有 4个是相等的, 还是分为8段的时候进行了特殊处理? 2: 还可以对其他东西,比如图片,歌曲进行特征向量提取,再利用局部敏感哈希函数,这里还不用考虑语义上的相似作者回复: 1.其实从抽屉原理来看,五段以上都可以。比如说五段的比特位个数分为13,13,13,13,12。但是从计算机的实现来看,读取和处理13个比特位的效率并不高。不如读取和处理8个比特位(一个字节)高效。因此可以以8个比特位为单位处理。 然后,这个相似度判断的流程是分为召回和排序两阶段。分成八段只是方便召回,召回了候选集以后,我们还需要基于海明距离进行排序,海明距离小于k的元素才会被留下。因此,分段的多少只会影响检索效率,不会影响最后判断相似性的精准度。
2020-05-0327 明翼这篇文章干货很多,这是很好的思路。说下我的理解,局部敏感hash关注点在于保持相似性的原文hash也相似,我一般用hash多是检验是否修改过了,或者判断是否存在比如布隆过滤器。谷歌的那个算法更是让我开了眼界,通过计算词的hash得到64bit序列,为叠加权重将0改成-1,我们如果不修改那和权重相乘的结果是0,叠加成文章权重的时候,权重很小的关键词和权重很大的关键词在这一位的影响是一样的了,然后将所有的关键词叠加保证了大权重关键词影响大,比如大关键词在一位中为-1,那最终结果很可能这一位为负数,最终为了方便比较可以说做了另外一个映射,映射成0和1这种64位比特流,因为这样和二进制对应。后面的海明距离的就更巧妙了,分割数据看成多个段,回答下问题吧: 1. 海明距离4为区分度,那分割成五段的话,至少有一段是完全相同的,不过这样分割不太好分割,分割成8段,我理解的过程为0-7为一组8-15 16-23一次类推分成8个组后,每个组都有8位,那每组就有16个不同的key因为2*8,后面postlist为哪些文章的哪些位对应这组key,查询文章过来后,找到相同的key的所有文章,这样我们得到8组文章,然后既然距离为4,我们可以每两个组求交集,每求三次仍然保留的满足条件,抽出来作为结果集,这个求的过程好好设计。 2. 这种算法可以用在推荐爱好相似的好友上,比如我们给用户打不同的标签,所有的标签组成一个文章,按照上述算法求相近的用户,推荐为好友;相似路径是不是可以,我们把一段距离之间的几个关键经过点标记出来作为词,然后比较相似性。图片音乐这种也适合;图书如果打上标签,或者用图书关键词也合适
明翼这篇文章干货很多,这是很好的思路。说下我的理解,局部敏感hash关注点在于保持相似性的原文hash也相似,我一般用hash多是检验是否修改过了,或者判断是否存在比如布隆过滤器。谷歌的那个算法更是让我开了眼界,通过计算词的hash得到64bit序列,为叠加权重将0改成-1,我们如果不修改那和权重相乘的结果是0,叠加成文章权重的时候,权重很小的关键词和权重很大的关键词在这一位的影响是一样的了,然后将所有的关键词叠加保证了大权重关键词影响大,比如大关键词在一位中为-1,那最终结果很可能这一位为负数,最终为了方便比较可以说做了另外一个映射,映射成0和1这种64位比特流,因为这样和二进制对应。后面的海明距离的就更巧妙了,分割数据看成多个段,回答下问题吧: 1. 海明距离4为区分度,那分割成五段的话,至少有一段是完全相同的,不过这样分割不太好分割,分割成8段,我理解的过程为0-7为一组8-15 16-23一次类推分成8个组后,每个组都有8位,那每组就有16个不同的key因为2*8,后面postlist为哪些文章的哪些位对应这组key,查询文章过来后,找到相同的key的所有文章,这样我们得到8组文章,然后既然距离为4,我们可以每两个组求交集,每求三次仍然保留的满足条件,抽出来作为结果集,这个求的过程好好设计。 2. 这种算法可以用在推荐爱好相似的好友上,比如我们给用户打不同的标签,所有的标签组成一个文章,按照上述算法求相近的用户,推荐为好友;相似路径是不是可以,我们把一段距离之间的几个关键经过点标记出来作为词,然后比较相似性。图片音乐这种也适合;图书如果打上标签,或者用图书关键词也合适作者回复: simhash的设计和检索的确都很巧妙。不得不说,Google的搜索引擎中的确有着许多亮点。这些技术可以说是Google帝国的地基。 1.分组以后,每组并不是只有16个key,而是2^8共256个key。这样如果两篇文章有一段8个比特位是相同的,它们就会在这个key对应的posting list中。 2.相似路径,图片,音乐,这些都是很好地使用局部敏感哈希的场景,因为它们都是字面相似的。好友推荐和文章推荐可能会更重视语意推荐一些。不过局部敏感哈希也是可以尝试的。
2020-05-0524- 奕每一个文档都根据比特位划分为 4 段,以每一段的 16 个比特位的值作为 Key,建立 4 个倒排索引 ------------------------------- 这里是怎么 以 16 个比特位的值作为 Key 建立倒排索引的呢? 怎么把文档分配到这四个 posting list 中的? 这里没有理解 还有下面的分段查询的图中,怎么每个倒排索引里面 还有以key建的倒排索引? 这里的key是每一段的 位取值吗?0- 2^16-1 个倒排索引?
作者回复: 首先,“四个倒排索引”不是“只有四个posting list”。每个倒排索引中,都会有多个key和对应的posting list。 然后分段查询的图,你的理解是对的。我再详细描述一下。 我们将16个比特位看着是一个值。这样,就可以用这个值作为key来建立倒排索引。 比如说,我们有100个元素,我们先看它们哈希值的前16个比特位,如果这100个元素的前16个比特位几乎都是相同的,比如说只有两种情况,那么倒排索引就只有两个key,然后这100个元素就会根据自己的值,加入到对应的key的posting list中。 同理,再看下一个16个比特位,如果这100个元素在这一段上,一共有k种值的话,那么就会生成k个key,然后将这100个元素加入对应的key后面的posting list中。依此类推。 希望这样的分析能解答你的疑惑。
2020-05-0333  范闲1.距离相近的点比距离相远的点更容易发生Hash碰撞,这是局部敏感哈希的理论根据 2. LSH family有hyperplane和crosspoltye的,同样SimHash也是一种方法 3.文章中的例子都是关键词的,实际上现在可以做成embedding的比较吧,这样关键信息的丢失会更少 4.所有的ANN相关算法,都是建立在对全空间的不断划分上,将全空间划分为若干子空间,然后在子空间里搜索最近邻. 思考题目: 1.如果4位以内的不同,都可以认为比较相似,那么划分的时候64位应该划分成8段比较合适。 2.除了文章,其他的embedding的相似性求解也可以。
范闲1.距离相近的点比距离相远的点更容易发生Hash碰撞,这是局部敏感哈希的理论根据 2. LSH family有hyperplane和crosspoltye的,同样SimHash也是一种方法 3.文章中的例子都是关键词的,实际上现在可以做成embedding的比较吧,这样关键信息的丢失会更少 4.所有的ANN相关算法,都是建立在对全空间的不断划分上,将全空间划分为若干子空间,然后在子空间里搜索最近邻. 思考题目: 1.如果4位以内的不同,都可以认为比较相似,那么划分的时候64位应该划分成8段比较合适。 2.除了文章,其他的embedding的相似性求解也可以。作者回复: 你对局部敏感哈希归纳得挺好。包括ann(近似最近邻)的算法,本质都是建立在对全空间的不断划分上,在子空间进行检索。你会发现,这其实和我们在第一讲就提到过的二分查找的核心思想是一致的。 关于思考题: 1.根据抽屉原理,五段以上其实都可以。当然从代码简洁程度和空间均匀划分角度来看,八段是比较简洁的。 2.的确是这样的。有这么一句话“万物皆可embedding”。其实许多事物都可以抽象成高维向量空间的点,都可以使用局部敏感哈希的思路检索。只要把每个维度的特征拿出来,用Simhash的方法处理即可。
2020-04-293 innocent请问老师,业界主流的文本相似度计算就是采用局部哈希么
innocent请问老师,业界主流的文本相似度计算就是采用局部哈希么作者回复: 并不是哦。我在文章结尾也说了局部敏感哈希更多的是用来判断字面上是否有大范围重复,但是对于语义上的相似处理得并不好。 业界主流的文本相似度计算是这样的: 1.最基础的是基于tf-idf的向量空间,用余弦距离来求相似度。 2.但原始的向量空间维度太高,效果也不好,因此之前业界会采用分析潜在语义的PLSA和LDA主题模型进行文本分析,得到降维的向量,从而更好地计算向量相似度。 3.而现在,随着深度学习的普及,业界会使用dssm-lstm,还有doc2vec来将文本学习成低维的向量,从而可以计算向量相似度。
2020-05-142 王坤祥通过学习这一讲,我联想到了虚拟内存到物理内存的页表映射方法。在映射时,虚拟内存的高位用于从映射到物理内存,低位作为偏移量,然后得到真实的物理地址。 老师,我联想的对吗?
王坤祥通过学习这一讲,我联想到了虚拟内存到物理内存的页表映射方法。在映射时,虚拟内存的高位用于从映射到物理内存,低位作为偏移量,然后得到真实的物理地址。 老师,我联想的对吗?作者回复: 哈哈,既然是联想,那怎么想都可以。你这个联想的关键词是映射,的确计算机的世界中,会有许多映射关系。 你举的这个例子,是一一映射的关系,一个虚拟地址对应一个物理地址。 而文章中的例子,就不是一一映射了,这种高维到低维的映射,会将多个高维的地址映射到低维的同一个地址中。这样会起到降维和压缩的作用。
2020-05-122 Ignite由于每个比特位只有 0 和 1 这 2 个值,一共有 64 个比特位,也就一共有 2*64 共 128 个不同的 Key。为啥是2*64而不是2^64
Ignite由于每个比特位只有 0 和 1 这 2 个值,一共有 64 个比特位,也就一共有 2*64 共 128 个不同的 Key。为啥是2*64而不是2^64作者回复: 因为我们现在是在构造倒排索引,因此每个比特位上值相同的数都在一个posting list中。每个比特位会产生2个posting list(0和1各有一个posting list),因此一共有128个
2021-10-121 benny分八段后,要找至少四段相同的吧?这块处理有啥特殊技巧?
benny分八段后,要找至少四段相同的吧?这块处理有啥特殊技巧?作者回复: 这是一个好问题,分成八段以后,是否有啥特殊的处理技巧?其实是可以有的。 我们先看看不做特殊处理是怎么做的。常规情况下,我们只需要将这八段作为八个key去检索倒排表,然后将倒排表中的结果取并集,并对集合中的每个结果和查询的值进行比较,计算海明距离。 但如果考虑到,如果有一个文档有至少四段都是相同的才是符合条件的,而只有三段相同或者两段相同的都应该被过滤掉,那么我们可以做这么一个优化:在合并集合的时候,对每个结果进行计数,看看它在这八段中有几段是相同的。然后,我们根据这个计数,将少于四段相同的都快速过滤掉。对于剩下的结果,再来精确计算海明距离。这就是一个“粗排+精排”的两阶段排序过程了。
2020-06-111