

16丨案例:性能监控工具之Grafana+Prometheus+Exporters

该思维导图由 AI 生成,仅供参考
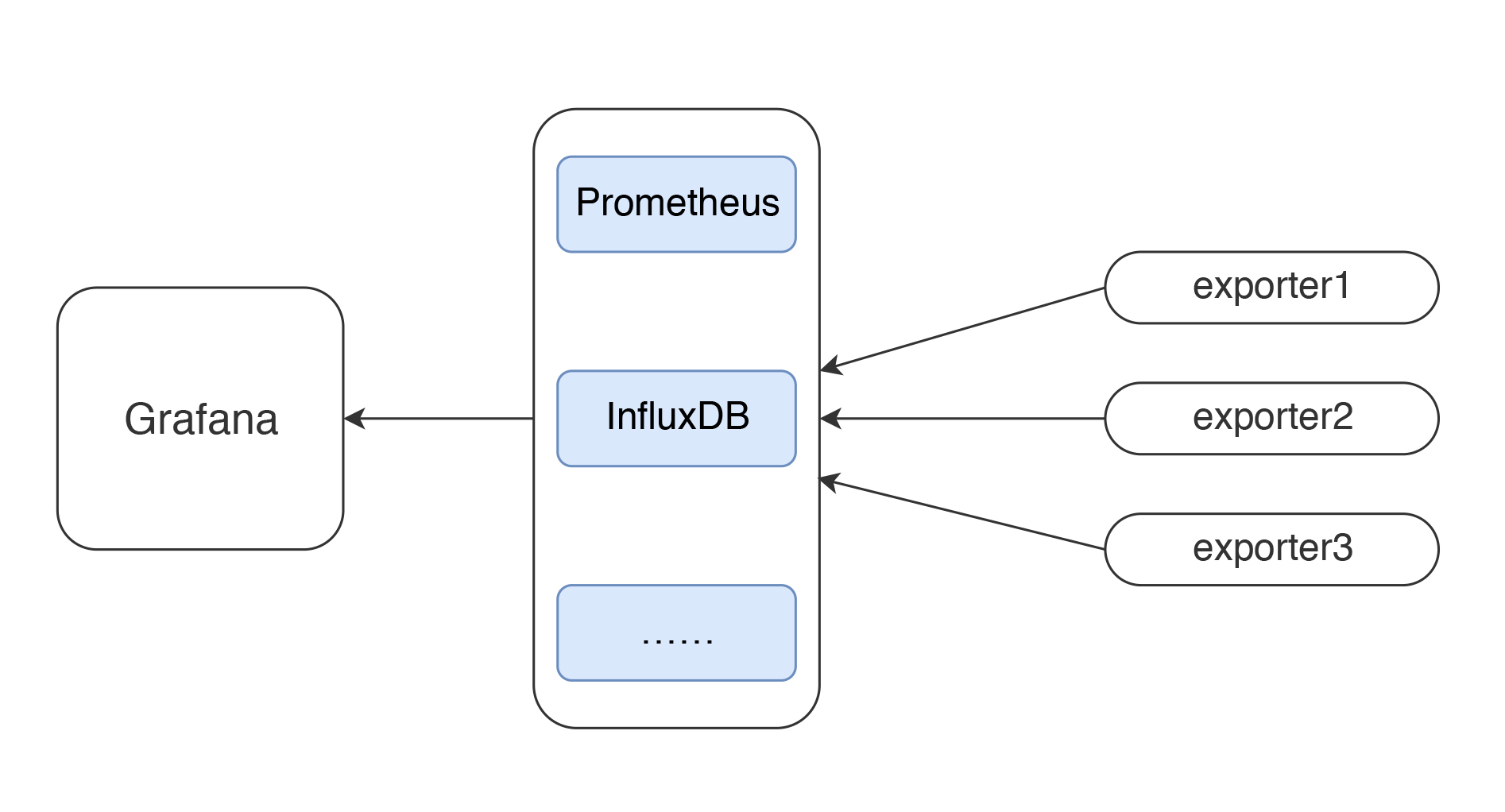
JMeter+InfluxDB+Grafana 的数据展示逻辑
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

本文详细介绍了使用Grafana、Prometheus、InfluxDB和Exporters进行监控的逻辑,并指导了如何配置JMeter的Backend Listener来实时发送数据到InfluxDB或Graphite。通过配置Backend Listener,可以将JMeter的统计结果异步发送到InfluxDB中,然后在Grafana中配置InfluxDB数据源和JMeter显示模板,实时查看测试结果。文章还介绍了InfluxDB中的存储结构,展示了如何从InfluxDB中取出数据并在Grafana中进行时序曲线展示。另外,文章还介绍了node_exporter+Prometheus+Grafana的数据展示逻辑,以及如何配置node_exporter、Prometheus和Grafana来展示操作系统资源数据。总结中还强调了对于监控平台来说,取的所有的数据必然是被监控者可以提供的数据,需要了解数据的含义和对性能测试和分析的影响。整体来说,本文通过详细的配置和代码解析,帮助读者了解了如何使用这些监控工具进行性能监控和数据展示,以及对监控数据的逻辑和含义进行解释。
《性能测试实战 30 讲》,新⼈⾸单¥59

全部留言(49)
- 最新
- 精选
 小昭
小昭 今日思考题: 问题1:JMeter 是如何把数据推送到 Grafana 中的? 共分为两个大步骤: 1、JMeter 将数据发给 InfluxDB: (1)在JMeter 中配置 Backend Listener ; (2)使用InfluxdbBackendListenerClient将JMeter运行的统计结果添加到metric中,并保存metric; (3)使用InfluxdbMetricsSender将metric发送到Influxdb; 2、Grafana从 InfluxDB获取数据: (1)在Grafana 中配置InfluxDB 数据源 (2)添加 JMeter dashboard,导入模板,选择对应的数据源即可看到界面 问题2:同样是监控操作系统的计数器,监控平台中的数据和监控命令中的数据有什么区别? 就数据的值来说,没有区别; 就数据量来说,监控平台的数据通常比监控命令中查到的数据会少一些。 今日感悟: 高老师的专栏,音频总会比文章多讲一些,知道这一点之后,我就调整了学习方式,我先听音频,再细读文章(以前我的习惯是先看文章,再听音频)。这节内容,不适用了,不知道是因为我太弱,还是老师语速变快了,边听边看文章,听的真是一脸懵。 大概听了3遍之后,这节课在我眼里变成了高不可攀的形象。甚至让我有一种,这个专栏我可能就卡在这里学不动了的感觉。然后抵触心理就出来了,有点不想学。 但是吧,不能轻言放弃,于是我不听音频了,开始细细读文章。边读边整理笔记,梳理思路。 神奇般的,我觉得我又能懂了,虽然不是说完全能把这个监控平台搭起来,但是我觉得我体会到了老师这节课想强调的东西。 最后,作为一个小白,这节课我对自己的要求就是:达到一个感性的认识。 其实归根结底还是自己手头没有实际的性能项目来练习,边学边练其实才是最好的。 最最后:文中“通过 writeAndSendMetrics,就将所有保存的 metrix 都发给了 InfluxDB。” 老师单词是不是拼错啦,应该是metric吧(或者是metrics?)
今日思考题: 问题1:JMeter 是如何把数据推送到 Grafana 中的? 共分为两个大步骤: 1、JMeter 将数据发给 InfluxDB: (1)在JMeter 中配置 Backend Listener ; (2)使用InfluxdbBackendListenerClient将JMeter运行的统计结果添加到metric中,并保存metric; (3)使用InfluxdbMetricsSender将metric发送到Influxdb; 2、Grafana从 InfluxDB获取数据: (1)在Grafana 中配置InfluxDB 数据源 (2)添加 JMeter dashboard,导入模板,选择对应的数据源即可看到界面 问题2:同样是监控操作系统的计数器,监控平台中的数据和监控命令中的数据有什么区别? 就数据的值来说,没有区别; 就数据量来说,监控平台的数据通常比监控命令中查到的数据会少一些。 今日感悟: 高老师的专栏,音频总会比文章多讲一些,知道这一点之后,我就调整了学习方式,我先听音频,再细读文章(以前我的习惯是先看文章,再听音频)。这节内容,不适用了,不知道是因为我太弱,还是老师语速变快了,边听边看文章,听的真是一脸懵。 大概听了3遍之后,这节课在我眼里变成了高不可攀的形象。甚至让我有一种,这个专栏我可能就卡在这里学不动了的感觉。然后抵触心理就出来了,有点不想学。 但是吧,不能轻言放弃,于是我不听音频了,开始细细读文章。边读边整理笔记,梳理思路。 神奇般的,我觉得我又能懂了,虽然不是说完全能把这个监控平台搭起来,但是我觉得我体会到了老师这节课想强调的东西。 最后,作为一个小白,这节课我对自己的要求就是:达到一个感性的认识。 其实归根结底还是自己手头没有实际的性能项目来练习,边学边练其实才是最好的。 最最后:文中“通过 writeAndSendMetrics,就将所有保存的 metrix 都发给了 InfluxDB。” 老师单词是不是拼错啦,应该是metric吧(或者是metrics?)编辑回复: 收到
2020-03-3027- bettynie老师,按照你讲的原理,其实我们需要搭建 jmeter+influxdb+grafana 和 prometheus+exports+grafana 2套系统来分别监控我们需要的性能指标,是么? jmeter+influxdb+grafana用来监控jmeter中的线程数,响应时间和吞吐量,prometheus+exports+grafana 用来监控系统资源或者数据库以及其他资源, 对么? 并且prometheus+exports+grafana 只能监控linux和uinx系统,无法监控windows,并且只能监控mysql数据库,感觉好像就是为监控docker之内的容器而生的~
作者回复: 你可以用grafana+prometheus+一堆exporters来实现对windows/linux/mysql/jvm/redis/kafka等的监控,同时也用同一个grafana+prometheus来监控k8s+docker。有很多的exporter可以用。 对jmeter,如果你想放进去,可以用同一个granfa,再搭配一个influxdb收集jmeter的数据就行了。
2020-02-296  SeaYang老师您好,backend listener本身没有问题,可能我描述的不够清楚,我再描述一次我的问题: 1、背景 我们基于jmeter做了个压测平台,在平台的前端页面上编写接口、场景等,点击压测,后端会调度多台压力机,每台压力机会将接口、场景数据使用jmeter的api生成jmx文件,然后调用jmeter的命令行启动压测。生成jmx文件的过程中会创建一个backend listener元件,每台压力机backend listener元件的application字段设置为了同一个值,这样子我们可以通过这个application值调用InfluxDB的http接口,获得所有压力机的tps总和 2、遇到的问题 1)实验过程 使用控制目标TPS的方式,TPS目标是2000,启动20台压力机,每台压力机的目标TPS为2000 / 20 = 100,注意,单台压力机就能达到2000TPS。 2)现象 通过观察前端页面的tps曲线,会发现TPS经常达不到2000,经常是1800, 1900左右,看上去像是有一两台压力机没有将数据抛到InfluxDB中,查看InfluxDB,会发现每秒确实只有18条、19条的数据。 3)分析 查看每台压力机的jmeter输出日志,有summary输出,说明每台压力机都正常调起了jmeter并正常压测了,查看InfluxDB的连接也没有问题。 后来同时启动30台压力机,也是看上去像是有一两台压力机没有抛数据一样,但jmeter日志都没问题,这就很奇怪了,如果是InfluxDB不支持20台压力机同时抛数据,那么30台压力机同时抛数据就应该最多每秒只有十几条数据啊。难道是因为每台压力机的application值都一样,有一定概率发生数据覆盖? 3、解决办法 将每台压力机的backend listener的application字段设置为不同的值,但是有一个相同的前缀,通过这个前缀值去查询总的TPS数据,经过几十次的测试,都是正常的,没有再出现问题了。但是之前是不是发生了数据覆盖也不确定,但暂时也不管了。
SeaYang老师您好,backend listener本身没有问题,可能我描述的不够清楚,我再描述一次我的问题: 1、背景 我们基于jmeter做了个压测平台,在平台的前端页面上编写接口、场景等,点击压测,后端会调度多台压力机,每台压力机会将接口、场景数据使用jmeter的api生成jmx文件,然后调用jmeter的命令行启动压测。生成jmx文件的过程中会创建一个backend listener元件,每台压力机backend listener元件的application字段设置为了同一个值,这样子我们可以通过这个application值调用InfluxDB的http接口,获得所有压力机的tps总和 2、遇到的问题 1)实验过程 使用控制目标TPS的方式,TPS目标是2000,启动20台压力机,每台压力机的目标TPS为2000 / 20 = 100,注意,单台压力机就能达到2000TPS。 2)现象 通过观察前端页面的tps曲线,会发现TPS经常达不到2000,经常是1800, 1900左右,看上去像是有一两台压力机没有将数据抛到InfluxDB中,查看InfluxDB,会发现每秒确实只有18条、19条的数据。 3)分析 查看每台压力机的jmeter输出日志,有summary输出,说明每台压力机都正常调起了jmeter并正常压测了,查看InfluxDB的连接也没有问题。 后来同时启动30台压力机,也是看上去像是有一两台压力机没有抛数据一样,但jmeter日志都没问题,这就很奇怪了,如果是InfluxDB不支持20台压力机同时抛数据,那么30台压力机同时抛数据就应该最多每秒只有十几条数据啊。难道是因为每台压力机的application值都一样,有一定概率发生数据覆盖? 3、解决办法 将每台压力机的backend listener的application字段设置为不同的值,但是有一个相同的前缀,通过这个前缀值去查询总的TPS数据,经过几十次的测试,都是正常的,没有再出现问题了。但是之前是不是发生了数据覆盖也不确定,但暂时也不管了。作者回复: 对influxdb这个时序数据库来说,在大压力下是会出现这样的问题的。数据时间戳一样会导致覆盖,你可以尝试修改源码里时间戳到更细的粒度。或添加个tag。
2020-11-125- 障碍物Prometheus有插件能监控sqlserver或者oracle等其他数据库么
作者回复: 都有的。你可以看一下prometheus官网中的第三方exporter,非常全面。
2020-02-115 
 dao如果有人和我一样安装的是 influxdb 2.0,那么需要在 JMeter Backend Listener 设置 influxdbUrl 和 influxdbToken。比如我的设置 influxdbUrl:http://192.168.1.196:9999/api/v2/write?bucket=test&org=dao influxdbToken:好长的一串 base64 编码的 token
dao如果有人和我一样安装的是 influxdb 2.0,那么需要在 JMeter Backend Listener 设置 influxdbUrl 和 influxdbToken。比如我的设置 influxdbUrl:http://192.168.1.196:9999/api/v2/write?bucket=test&org=dao influxdbToken:好长的一串 base64 编码的 token作者回复: 不错,这是一个知识点。
2021-05-0423 涓涓高老师,好。 你看这样配置行不行: 1. 要监控的每台服务器都配置一个node_exporter 2. 然后再找台服务器安装prometheus,在prometheus.yml中添加每个node_exporter的配置 3. 最后在grafana中配置prometheus,查看采集的各台服务器数据。
涓涓高老师,好。 你看这样配置行不行: 1. 要监控的每台服务器都配置一个node_exporter 2. 然后再找台服务器安装prometheus,在prometheus.yml中添加每个node_exporter的配置 3. 最后在grafana中配置prometheus,查看采集的各台服务器数据。作者回复: 就是这样的逻辑呀。
2021-01-083- SeaYang1、JMeter 是如何把数据推送到 Grafana 中呢? JMeter实际上是将数据推送到Influxdb中,Influxdb本身对外提供了HTTP接口,Grafana通过HTTP接口轮询性能指标,若自己去画前端页面图表的话,也可以不用Grafana,直接调用Influxdb的HTTP接口 2、另外,同样是监控操作系统的计数器,监控平台中的数据和监控命令中的数据有什么区别? 没有区别,只是命令可能能看到更多的值 有时候压测过程中,压力机本身的资源情况也是需要关注的,通过Prometheus + node_exporter + Grafana可以很方便的查看压力机集群的资源情况,比传统一台台登录方便很多,顺便熟悉监控的部署
作者回复: 果然理解了。
2020-11-113  杜艳感觉老师讲的都是偏理论,知道数据的来龙去脉了,但是使用过程怎么搭建这个整体的监控平台步骤能不能详细介绍,让我们可以用在项目中呢?
杜艳感觉老师讲的都是偏理论,知道数据的来龙去脉了,但是使用过程怎么搭建这个整体的监控平台步骤能不能详细介绍,让我们可以用在项目中呢?作者回复: 这些不是偏理论,是偏原理逻辑。 本来想着网上有很多教人搭建的资料,自己稍微动手做一下就知道了。 所以只在专栏中体现原创的部分。 如果我把完整的搭建过程列出来就成了一步步操作的文章,担心会有人觉得不值得买这专栏了。 如果你想要详细的安装手册,可以联系我。😃
2020-02-09163 Cheese老师,如果用nodeexporter监控容器要怎么监控,因为容器IP是变化的,是通过端口来监控吗
Cheese老师,如果用nodeexporter监控容器要怎么监控,因为容器IP是变化的,是通过端口来监控吗作者回复: 容器里面不用node exporter来监控。用cadviser就可以,k8s已经集成 了。
2021-11-212 蔚来懿老师,有一个疑问,我的情况是这样的,我们公司环境有很多(测试环境,开发环境,预发布环境,开发环境),很多个项目,每个项目结构复杂,机器有很多,如果按照这样的部署的话,需要安装很多软件,还有防火墙的问题,请问是否有轻量级的监控方式,比如说,直接在服务器上装工具(类似nmon,但是直观),
蔚来懿老师,有一个疑问,我的情况是这样的,我们公司环境有很多(测试环境,开发环境,预发布环境,开发环境),很多个项目,每个项目结构复杂,机器有很多,如果按照这样的部署的话,需要安装很多软件,还有防火墙的问题,请问是否有轻量级的监控方式,比如说,直接在服务器上装工具(类似nmon,但是直观),作者回复: 用容器,把监控放到基础镜像中呀。
2021-01-132

