

10丨案例:在JMeter中如何设置参数化数据?

该思维导图由 AI 生成,仅供参考
正式场景前的基准测试
在测试工具中配置参数
参数化配置在 JMeter 中的使用说明
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

本文通过实例详细介绍了在JMeter中如何合理地设置参数化数据,包括确定业务支持量、配置参数化数据、展示执行结果和LoadRunner中的参数配置页面。读者可以快速了解在JMeter中如何设置参数化数据,以及在实际场景中的应用和效果。文章还总结了性能测试中参数化的逻辑,并提出了思考题,引发读者思考。文章内容简洁明了,适合技术人员快速了解参数化数据在性能测试中的重要性和应用方法。
《性能测试实战 30 讲》,新⼈⾸单¥59

全部留言(25)
- 最新
- 精选
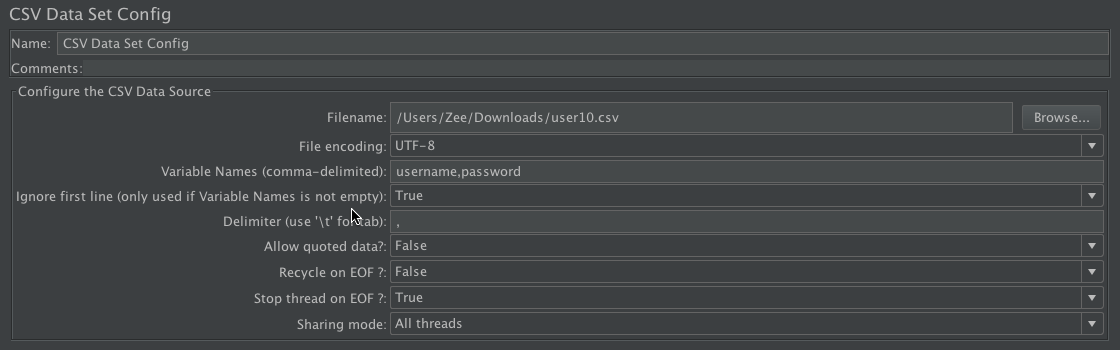
 律飛JMeter 的 CSV Data Set Config 功能用来从文件中读取数据行,并将它们拆分后存储到变量中。个人理解,Recycle on EOF的优先级高于Stop thread on EOF,也就是说,需要先判断Recycle on EOF,如果是Flase,直接在文件结束时就停止了线程,根本不考虑Stop thread on EOF参数值;如果是True,就要根据Stop thread on EOF参数值来确定线程是否停止运行。在明白组合逻辑关系后,可以更高效的设置参数、更准确的达到测试目的。 各种测试工具有各种测试功能,可能其中就会存在有关联的参数配置,这也需要我们特别关注。如果查阅资料还不能清晰认识,就按老师的做法,通过对不同组合进行实验,最终弄清楚组合关系,归纳总结出优先顺序,从而在平时测试中帮助我们快速有效地找到最优的组合。
律飛JMeter 的 CSV Data Set Config 功能用来从文件中读取数据行,并将它们拆分后存储到变量中。个人理解,Recycle on EOF的优先级高于Stop thread on EOF,也就是说,需要先判断Recycle on EOF,如果是Flase,直接在文件结束时就停止了线程,根本不考虑Stop thread on EOF参数值;如果是True,就要根据Stop thread on EOF参数值来确定线程是否停止运行。在明白组合逻辑关系后,可以更高效的设置参数、更准确的达到测试目的。 各种测试工具有各种测试功能,可能其中就会存在有关联的参数配置,这也需要我们特别关注。如果查阅资料还不能清晰认识,就按老师的做法,通过对不同组合进行实验,最终弄清楚组合关系,归纳总结出优先顺序,从而在平时测试中帮助我们快速有效地找到最优的组合。作者回复: 我觉得你写的比我写的好。哈。
2020-01-07516 小昭
小昭 今日思考题: 为什么参数化数据要符合生产环境的数据分布? 因为如果不符合生产环境的话,我们做这个性能测试就没有意义了。 为什么参数化数据要关注组合逻辑关系,而不是随意设置组合? 随意设置就会出现逻辑矛盾或者没有意义的组合。这样看上去节省了时间,其实反而浪费了时间。 今日感悟: CSV Data Set Config这个功能之前学过,但是只是别人告诉我怎么填,我就照着填了,没有深入思考各个参数不同组合会有什么样的效果。这节课听下来,对这个功能的理解又深入了些。超值超值,感谢老师。 看了评论为了验证Recycle on EOF和Stop thread on EOF这两个参数的关系,我去JMeter里实践了一下,我的CSV文件里有7条数据,线程数我设置的8。 得出结论是:如果Recycle on EOF是Flase,Stop thread on EOF是Flase,由于线程数比文件数据多,JMeter会继续执行,但是由于没有数据,会报错,然后停止;如果Recycle on EOF是Flase,Stop thread on EOF是True,就直接停止。所以两个参数我认为需要结合起来看,虽然Recycle on EOF的优先级高一些,但也不是能起决定性作用的。 然后回过头来再看一遍文章发现其实我练习的这两种情况老师都讲了并且举了例子。我刚学完的时候是清楚的(至少自己感觉是清楚的),但是看了评论我发现还是有点懵,然后决定自己试一试。练习过之后,是真的明白了。所以真的要动手去做呀。
今日思考题: 为什么参数化数据要符合生产环境的数据分布? 因为如果不符合生产环境的话,我们做这个性能测试就没有意义了。 为什么参数化数据要关注组合逻辑关系,而不是随意设置组合? 随意设置就会出现逻辑矛盾或者没有意义的组合。这样看上去节省了时间,其实反而浪费了时间。 今日感悟: CSV Data Set Config这个功能之前学过,但是只是别人告诉我怎么填,我就照着填了,没有深入思考各个参数不同组合会有什么样的效果。这节课听下来,对这个功能的理解又深入了些。超值超值,感谢老师。 看了评论为了验证Recycle on EOF和Stop thread on EOF这两个参数的关系,我去JMeter里实践了一下,我的CSV文件里有7条数据,线程数我设置的8。 得出结论是:如果Recycle on EOF是Flase,Stop thread on EOF是Flase,由于线程数比文件数据多,JMeter会继续执行,但是由于没有数据,会报错,然后停止;如果Recycle on EOF是Flase,Stop thread on EOF是True,就直接停止。所以两个参数我认为需要结合起来看,虽然Recycle on EOF的优先级高一些,但也不是能起决定性作用的。 然后回过头来再看一遍文章发现其实我练习的这两种情况老师都讲了并且举了例子。我刚学完的时候是清楚的(至少自己感觉是清楚的),但是看了评论我发现还是有点懵,然后决定自己试一试。练习过之后,是真的明白了。所以真的要动手去做呀。作者回复: 认真的同学。你全学会了,我可怎么混。😀😀😀
2020-03-20210 zuozewei第一个问题:为什么参数化数据要符合生产环境的数据分布? 在「01丨性能综述:性能测试的概念到底是什么」中已经讲过,性能模型中的业务模型是真实场景的抽象,即需要的数据通常都是从生产环境中的数据中统计来的,其关键就是「数据必须保证仿真」。 那么性能测试的时候我们需要特别注意压测流量以及相关的数据,必须保证它们的多样化和代表性,否则会导致测试结果会严重失真。 比如,当使用相同的测试数据进行重复测试时,如果压测请求不够大,那么各种缓存可能会严重影响测试结果。 第二个问题:为什么参数化数据要关注组合逻辑关系,而不是随意设置组合? 因为参数化数据要组合逻辑关系会直接影响参数化数据的分布情况,即数据是否均匀?数据是否稳定?是保否证测试时间足够长?满足测试的负载请求足够多和数据足够多样化,从而最大限度地减少或者掩盖缓存等其他因素的影响。
zuozewei第一个问题:为什么参数化数据要符合生产环境的数据分布? 在「01丨性能综述:性能测试的概念到底是什么」中已经讲过,性能模型中的业务模型是真实场景的抽象,即需要的数据通常都是从生产环境中的数据中统计来的,其关键就是「数据必须保证仿真」。 那么性能测试的时候我们需要特别注意压测流量以及相关的数据,必须保证它们的多样化和代表性,否则会导致测试结果会严重失真。 比如,当使用相同的测试数据进行重复测试时,如果压测请求不够大,那么各种缓存可能会严重影响测试结果。 第二个问题:为什么参数化数据要关注组合逻辑关系,而不是随意设置组合? 因为参数化数据要组合逻辑关系会直接影响参数化数据的分布情况,即数据是否均匀?数据是否稳定?是保否证测试时间足够长?满足测试的负载请求足够多和数据足够多样化,从而最大限度地减少或者掩盖缓存等其他因素的影响。作者回复: 已经理解的很深刻了。
2020-01-2037 善行通感谢老师总结; 1、罗列出需要参数化的数据及相对应的关系; 2、将参数化数据从数据库中取出或设计对应的生成规则; 3、合理地将参数化数据保存在不同的文件中; 4、在压力工具中设置相应的参数组合关系,以便实模拟真实场景 之前做行测不太去理解: Recycle on EOF? :这里有三个选择,False、True 和 Edit。 Stop thread on EOF?:这里有三个选择,False、True 和 Edit。含义和上面一致。 Sharing mode : 这里有四个选择,All threads、Current thread group、Current thread、Edit。 这几个用户,经过老师这样一步一步分析,收获很大,谢谢老师分享 第一个问题:为什么参数化数据要符合生产环境的数据分布? 1、减少数据命中率; 2、减少缓存命中率; 3、符合性能压测价值,测试结果更真实; 第二个:为什么参数化数据要关注组合逻辑关系,而不是随意设置组合? 1、业务规则决定参数文件不能随便组合; 2、如果随意组合参数,会影响事务成功率;
善行通感谢老师总结; 1、罗列出需要参数化的数据及相对应的关系; 2、将参数化数据从数据库中取出或设计对应的生成规则; 3、合理地将参数化数据保存在不同的文件中; 4、在压力工具中设置相应的参数组合关系,以便实模拟真实场景 之前做行测不太去理解: Recycle on EOF? :这里有三个选择,False、True 和 Edit。 Stop thread on EOF?:这里有三个选择,False、True 和 Edit。含义和上面一致。 Sharing mode : 这里有四个选择,All threads、Current thread group、Current thread、Edit。 这几个用户,经过老师这样一步一步分析,收获很大,谢谢老师分享 第一个问题:为什么参数化数据要符合生产环境的数据分布? 1、减少数据命中率; 2、减少缓存命中率; 3、符合性能压测价值,测试结果更真实; 第二个:为什么参数化数据要关注组合逻辑关系,而不是随意设置组合? 1、业务规则决定参数文件不能随便组合; 2、如果随意组合参数,会影响事务成功率;作者回复: 有收获我就值得了。
2020-01-065 筱の简單1、为什么参数化数据要符合生产环境的数据分布? 因为压测本身就是服务于生产环境,为使项目满足真实用户的需要,所以做压测的宗旨都是以实际业务逻辑出发满足用户需要,所以参数化也依赖业务逻辑,故在参数化之前,需要分析真实业务逻辑中如何使用数据,再在工具中选择相对应的组合参数的方式去实现。 2、为什么参数化数据要关注组合逻辑关系,而不是随意设置组合? 因为不关注组合的逻辑关系而随意设置组合,有些组合会存在没有意义且不符合逻辑关系的情况。影响参数化设置的有效性,也侧面反映压测人员的技术专业性。
筱の简單1、为什么参数化数据要符合生产环境的数据分布? 因为压测本身就是服务于生产环境,为使项目满足真实用户的需要,所以做压测的宗旨都是以实际业务逻辑出发满足用户需要,所以参数化也依赖业务逻辑,故在参数化之前,需要分析真实业务逻辑中如何使用数据,再在工具中选择相对应的组合参数的方式去实现。 2、为什么参数化数据要关注组合逻辑关系,而不是随意设置组合? 因为不关注组合的逻辑关系而随意设置组合,有些组合会存在没有意义且不符合逻辑关系的情况。影响参数化设置的有效性,也侧面反映压测人员的技术专业性。作者回复: 理解的非常对。
2020-02-223 陈陈陈小芮老师您好,我是刚接触性能测试没多久,所以有点疑问想请教下: 1、tps每秒100,5分钟需要的用户数据就是5x60x100,意思就是一秒钟需要的用户数据就是100个吗?举个例子,我的线程数、循环数都设置为1,一个线程组下有13个接口请求,但其中只有login这一个请求需要用到账号密码,其余的12个都不需要,此时执行显示13个请求在3秒处理完成,tps为平均每秒4.2个请求,按上面的逻辑,也就是一秒需要4.2个用户账号密码吗,但是这就跟我原本只需要一个账号密码相悖了,所以不太理解这个所需用户数的计算 2、在之前的基础篇您有讲过,tps是指的一个完整的事物,这个事物可以自己定义,若按这个理解,那么tps就应该是一个登陆操作带来的一系列请求(用我举的例子就是包含login在内的13个请求),可是此处的tps似乎是每秒处理的请求数(3秒请求数13,每秒就是4.2左右),好像又并不是事物数,这个点也不太理解
陈陈陈小芮老师您好,我是刚接触性能测试没多久,所以有点疑问想请教下: 1、tps每秒100,5分钟需要的用户数据就是5x60x100,意思就是一秒钟需要的用户数据就是100个吗?举个例子,我的线程数、循环数都设置为1,一个线程组下有13个接口请求,但其中只有login这一个请求需要用到账号密码,其余的12个都不需要,此时执行显示13个请求在3秒处理完成,tps为平均每秒4.2个请求,按上面的逻辑,也就是一秒需要4.2个用户账号密码吗,但是这就跟我原本只需要一个账号密码相悖了,所以不太理解这个所需用户数的计算 2、在之前的基础篇您有讲过,tps是指的一个完整的事物,这个事物可以自己定义,若按这个理解,那么tps就应该是一个登陆操作带来的一系列请求(用我举的例子就是包含login在内的13个请求),可是此处的tps似乎是每秒处理的请求数(3秒请求数13,每秒就是4.2左右),好像又并不是事物数,这个点也不太理解作者回复: 1. 如果你是13个请求是一个完整的业务流,那就是13个请求是一个事务。那tps的t就是完整的业务流了,而不是请求级的了。 2. 没看懂。
2021-08-2322 兰澜高楼老师,听了这个课收获很多,理清了一些思路。刚刚学习性能测试,做了一些简单的项目,有一个很问题一直很困惑,做一个项目的性能测试是我们获得了项目中需要测试性能的各接口的TPS和响应时间指标,跑基准场景测试时,使用LR工具,我要如何来设置start new iteration中的第3个选项中的每间隔多长时间迭代一次的值呢,这个可以依据什么来计算呢?或者怎么设置比较合理?还有就是start vusers中的用户数,每隔多长时间启动多少个用户,这个怎么设置比较合理呢?刚踏入性能测试,不知道如何去设置跑场景时的这些参数值,不知道怎样才是合理的
兰澜高楼老师,听了这个课收获很多,理清了一些思路。刚刚学习性能测试,做了一些简单的项目,有一个很问题一直很困惑,做一个项目的性能测试是我们获得了项目中需要测试性能的各接口的TPS和响应时间指标,跑基准场景测试时,使用LR工具,我要如何来设置start new iteration中的第3个选项中的每间隔多长时间迭代一次的值呢,这个可以依据什么来计算呢?或者怎么设置比较合理?还有就是start vusers中的用户数,每隔多长时间启动多少个用户,这个怎么设置比较合理呢?刚踏入性能测试,不知道如何去设置跑场景时的这些参数值,不知道怎样才是合理的作者回复: ”跑基准场景测试时,使用LR工具,我要如何来设置start new iteration中的第3个选项中的每间隔多长时间迭代一次的值呢,这个可以依据什么来计算呢?“ 答:我记得第二个是start new iteration at fixed/random intervals,every x second(s),如果是这个的话,就是指在设置的时间间隔之内只迭代一次。比如说,你设置为固定时长1秒,而迭代一次只需要500毫秒,那剩下的500毫秒就等待;如果再迭代一次需要400毫秒,则剩下的600毫秒就等待。 这个值的设置前提就是希望如何来控制单线程的TPS。 这个只有根据实际情况来判断合理值,比如说如何控制tps的比例。 “还有就是start vusers中的用户数,每隔多长时间启动多少个用户,这个怎么设置比较合理呢?” 答:这个设置在场景篇有描述。
2020-03-1022- 武先生爱学习请问,在公司里,做性能测试用的是什么负载机,用的自己的机器还是Linux负载机呢,这一块能否介绍下?
作者回复: 这个并没有特定的。只要能压得起来,负载机本身不会成为瓶颈点就可以了。
2020-02-242  小老鼠1,EOF处理不同对性能测试有什么影响?2,参数化用DB来获取,对性能测试结果的有无影响。
小老鼠1,EOF处理不同对性能测试有什么影响?2,参数化用DB来获取,对性能测试结果的有无影响。作者回复: 我觉得你思考问题的角度和我要说的话题都不在一个层面上。 1. EOF多明显对测试有影响,那使用数据的逻辑,我都列的那么清晰了,已经说明了影响了。 2. 参数化用不用DB来做,只会影响压力工具的处理过程。我反复强调了,对什么样的工具来做压力,对性能差的好的性能工具,都无所谓。像jmeter就不是性能高的工具。但是现在还是有很多人在用,对服务器的性能测试结果肯定是没什么影响的,服务器的处理能力是服务器的,是另一个角度。
2020-01-102 VintageCatJava summary + 125 in 00:00:04 = 31.0/s Avg: 28 Min: 0 Max: 869 Err: 0 (0.00%) Active: 1 Started: 1 Finished: 0 summary + 3404 in 00:00:30 = 113.2/s Avg: 31 Min: 0 Max: 361 Err: 0 (0.00%) Active: 6 Started: 6 Finished: 0 summary + 4444 in 00:00:30 = 148.4/s Avg: 57 Min: 0 Max: 623 Err: 10 (0.23%) Active: 11 Started: 11 Finished: 0 这个登录接口的数据是怎么来的呢?我是指用什么策略执行的 ,没有很明白,看active分别是1 6 11这个是指不同的压力线程组情况下吧
VintageCatJava summary + 125 in 00:00:04 = 31.0/s Avg: 28 Min: 0 Max: 869 Err: 0 (0.00%) Active: 1 Started: 1 Finished: 0 summary + 3404 in 00:00:30 = 113.2/s Avg: 31 Min: 0 Max: 361 Err: 0 (0.00%) Active: 6 Started: 6 Finished: 0 summary + 4444 in 00:00:30 = 148.4/s Avg: 57 Min: 0 Max: 623 Err: 10 (0.23%) Active: 11 Started: 11 Finished: 0 这个登录接口的数据是怎么来的呢?我是指用什么策略执行的 ,没有很明白,看active分别是1 6 11这个是指不同的压力线程组情况下吧作者回复: 就是递增的压力策略。
2023-05-26归属地:湖南1

