

06丨倾囊相授:我毕生所学的性能分析思路都在这里了

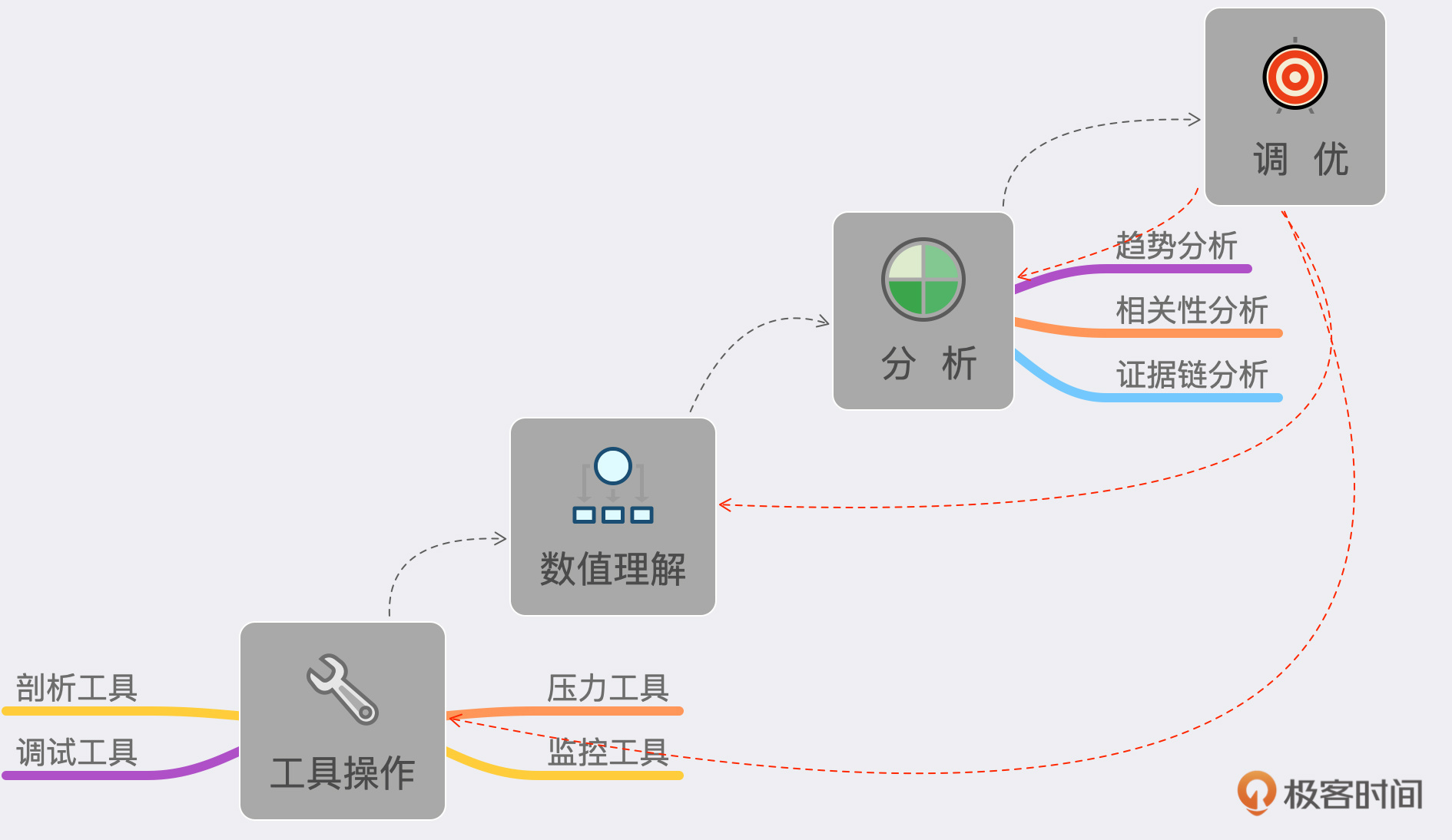
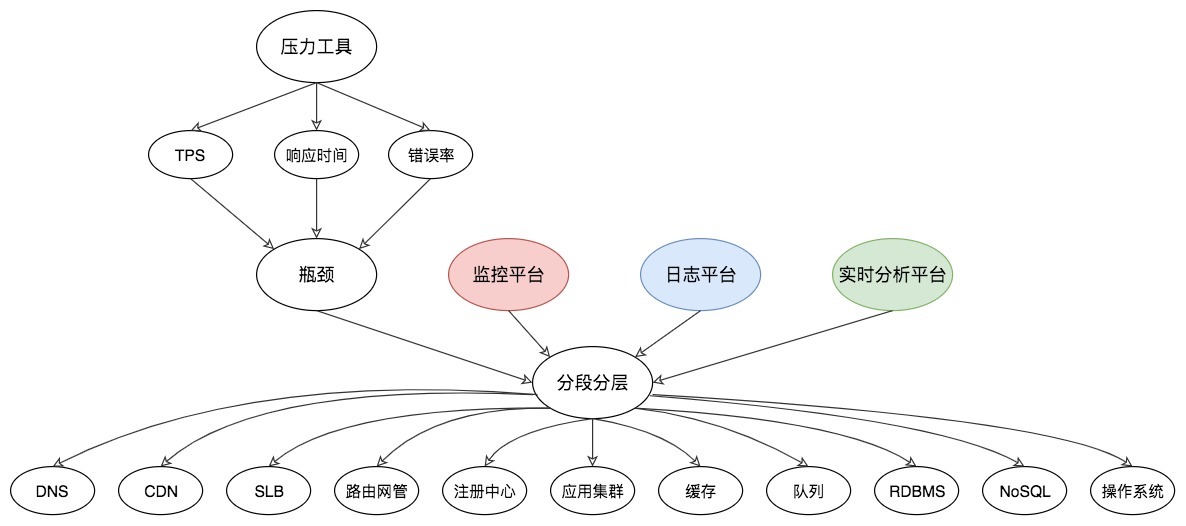
瓶颈的精准判断
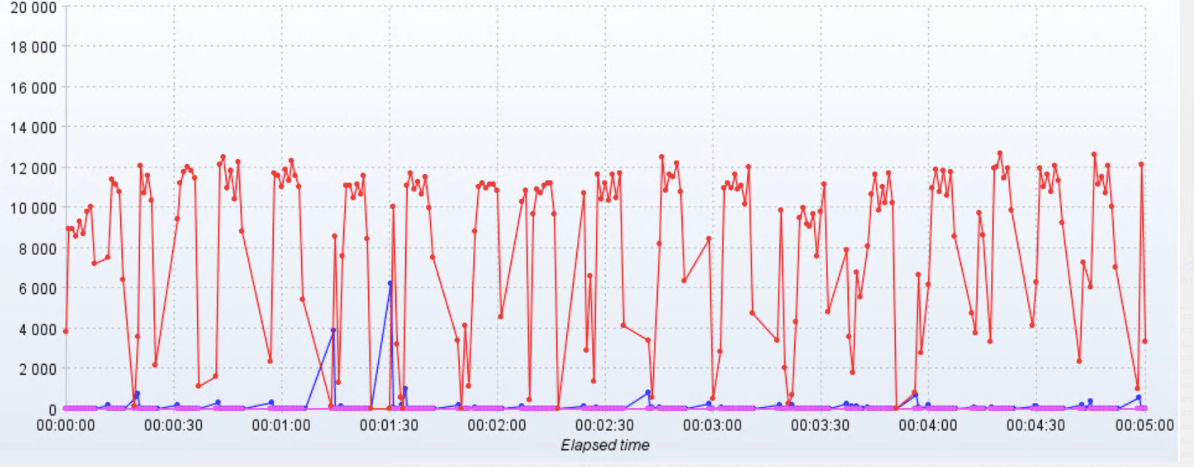
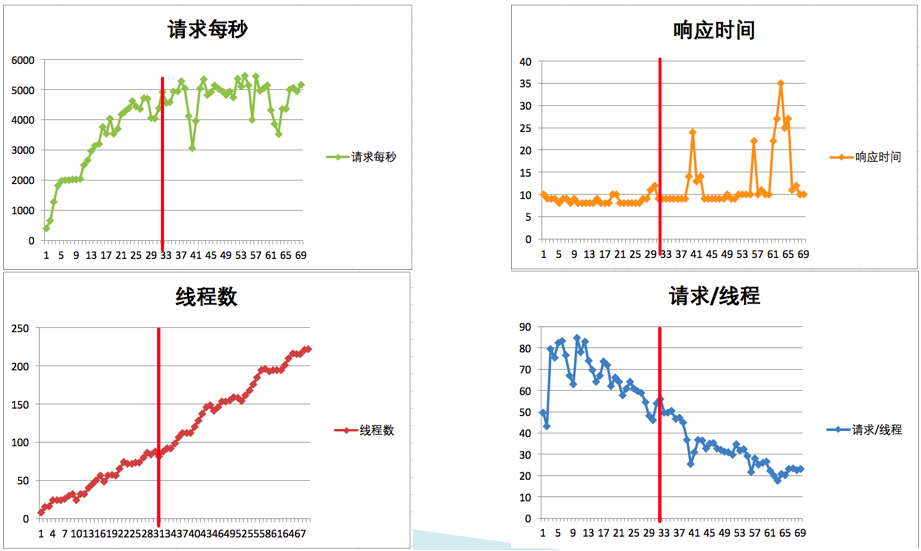
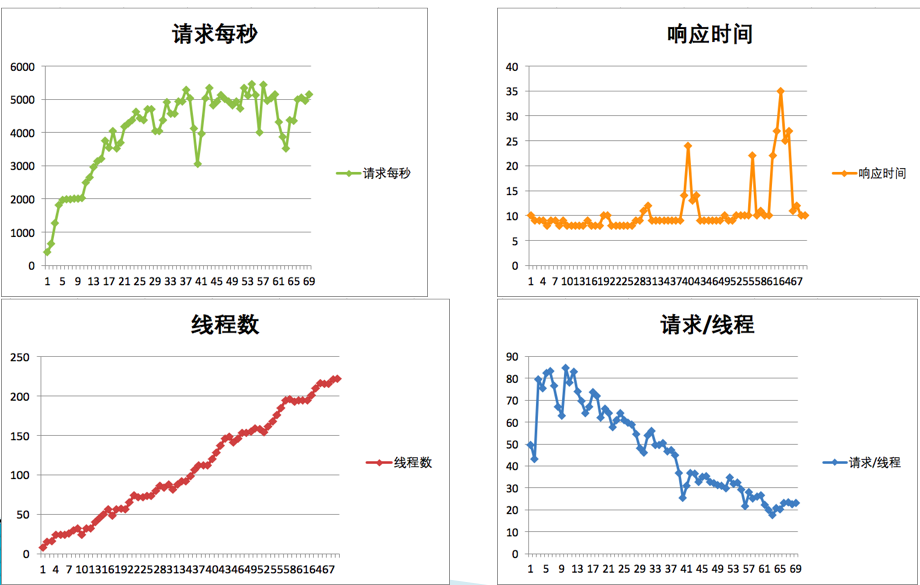
TPS 曲线
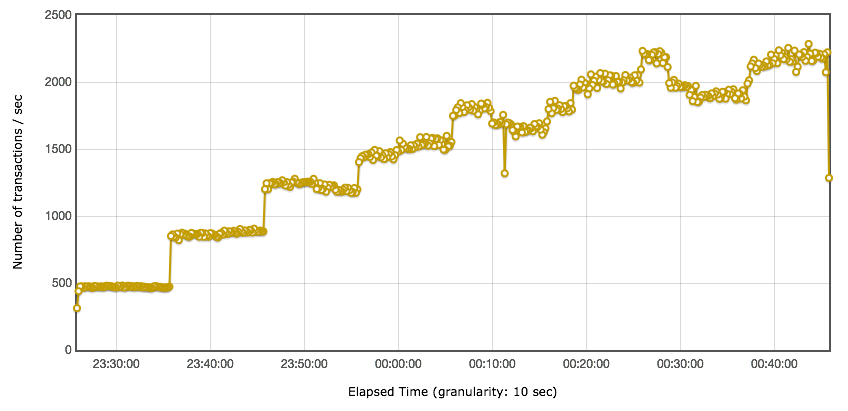
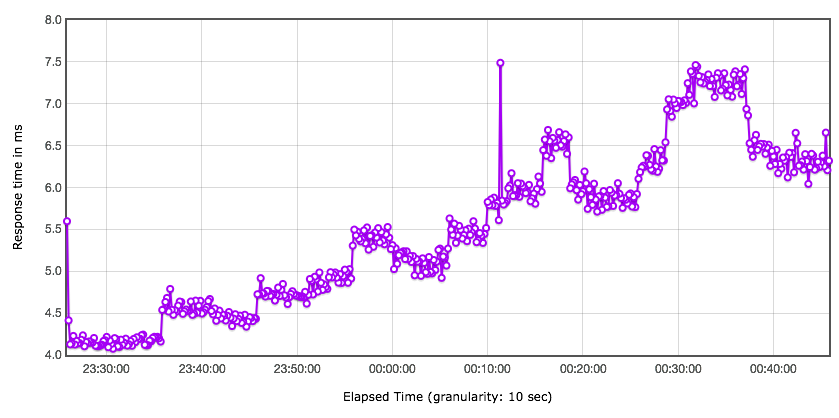
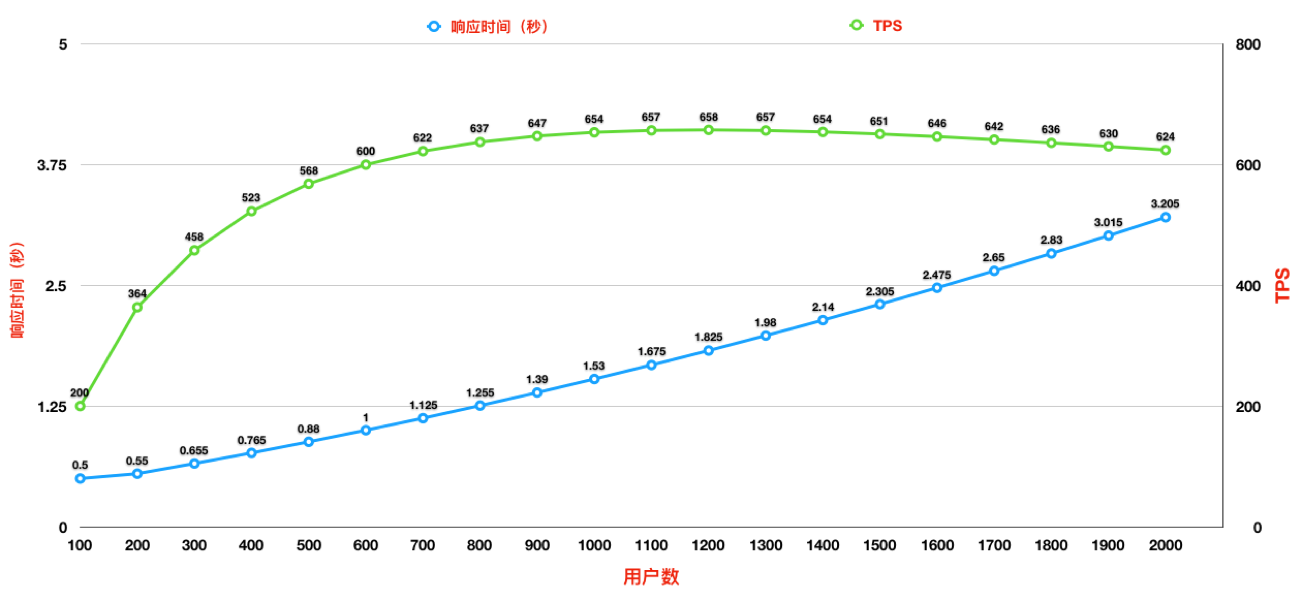
响应时间的曲线
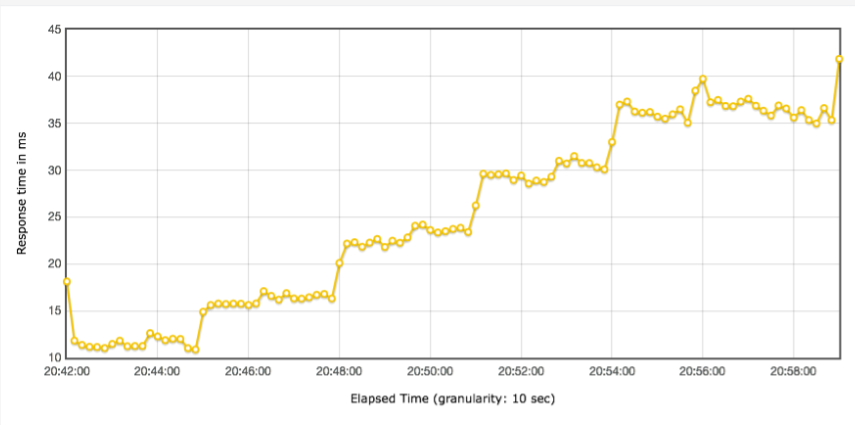
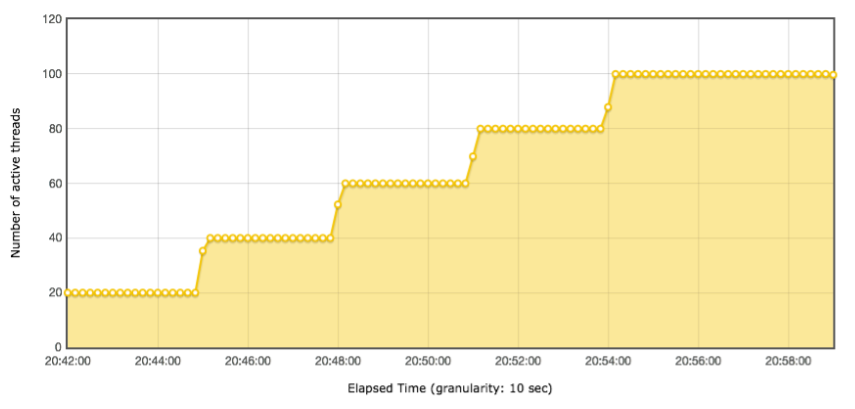
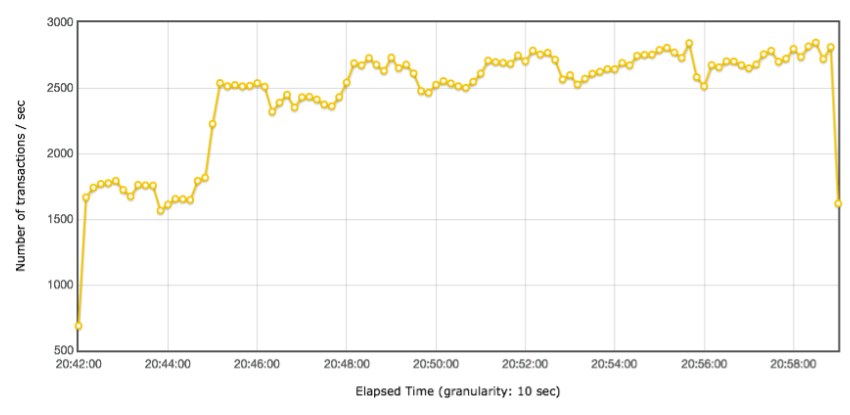
线程递增的策略
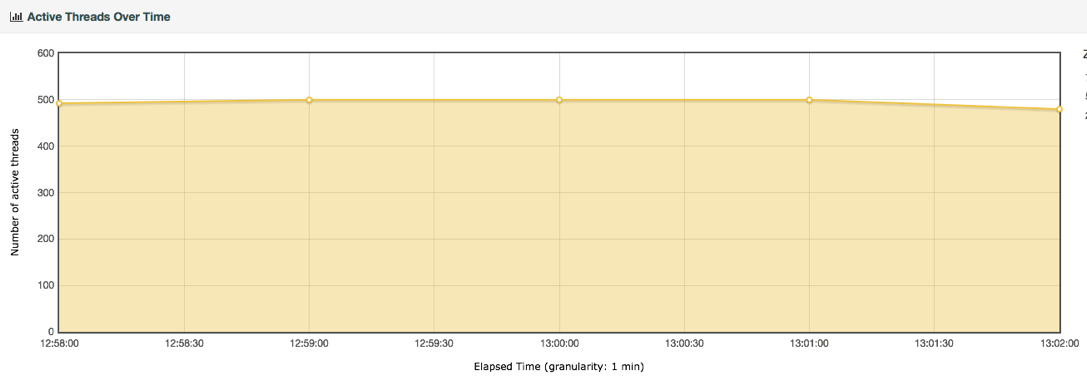
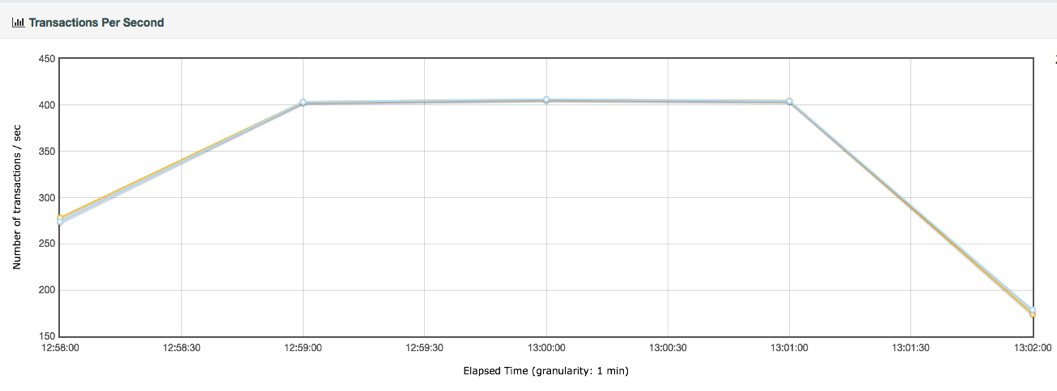
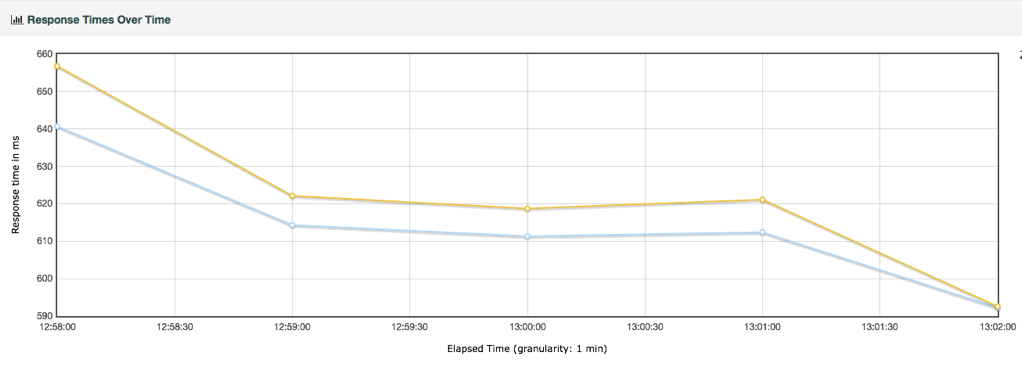
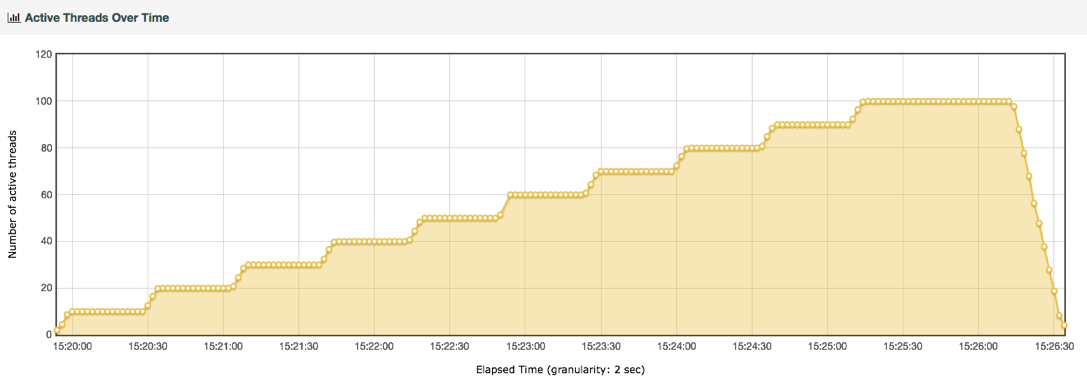
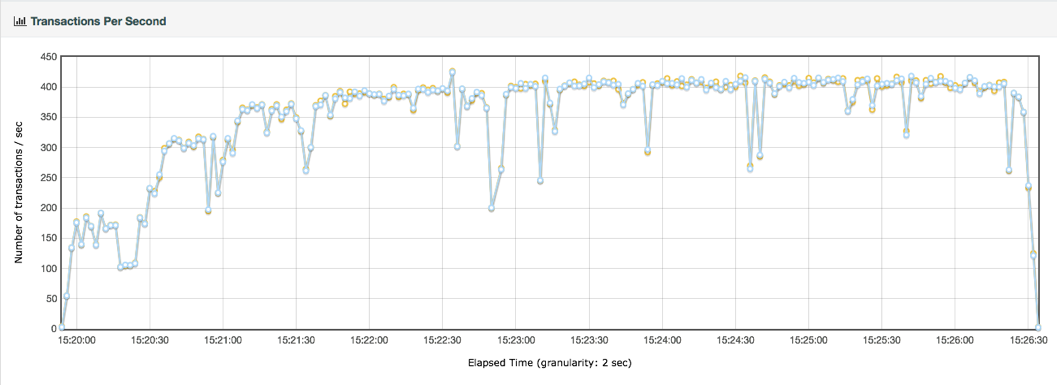
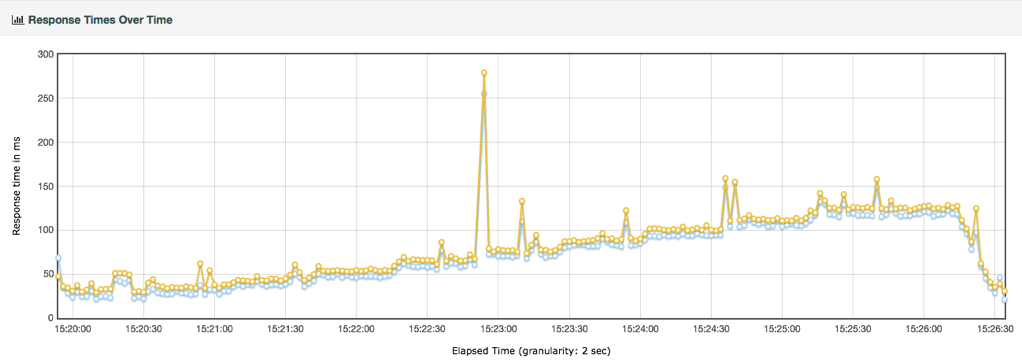
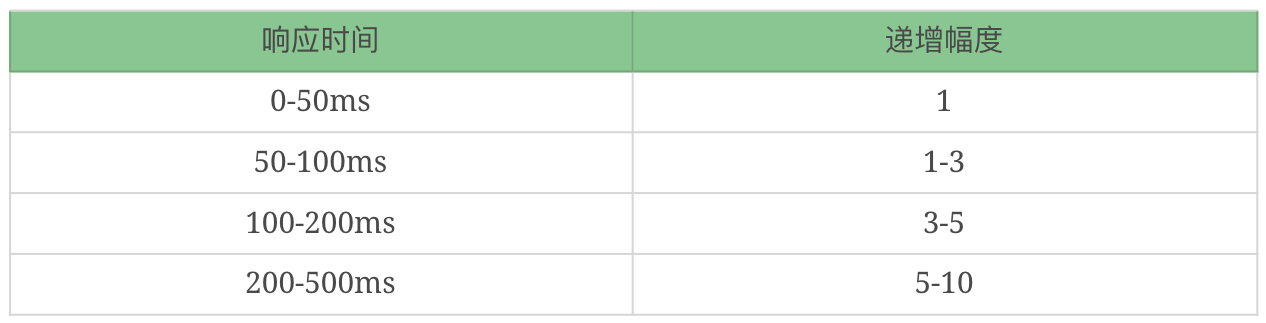
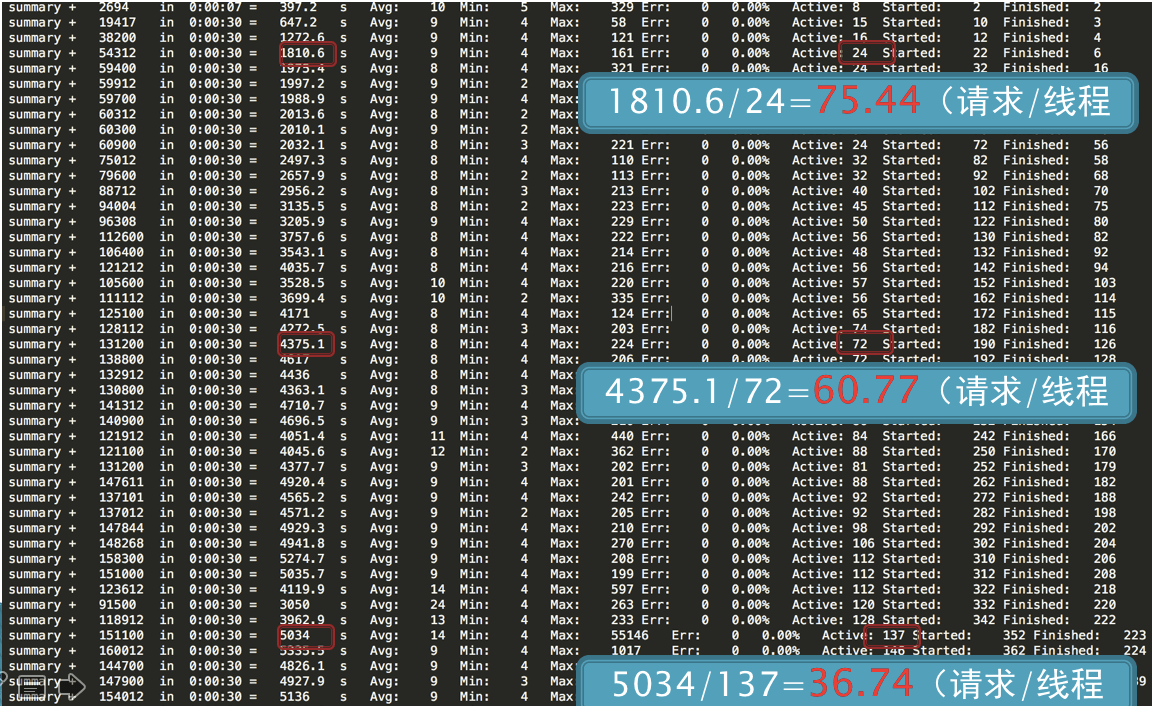
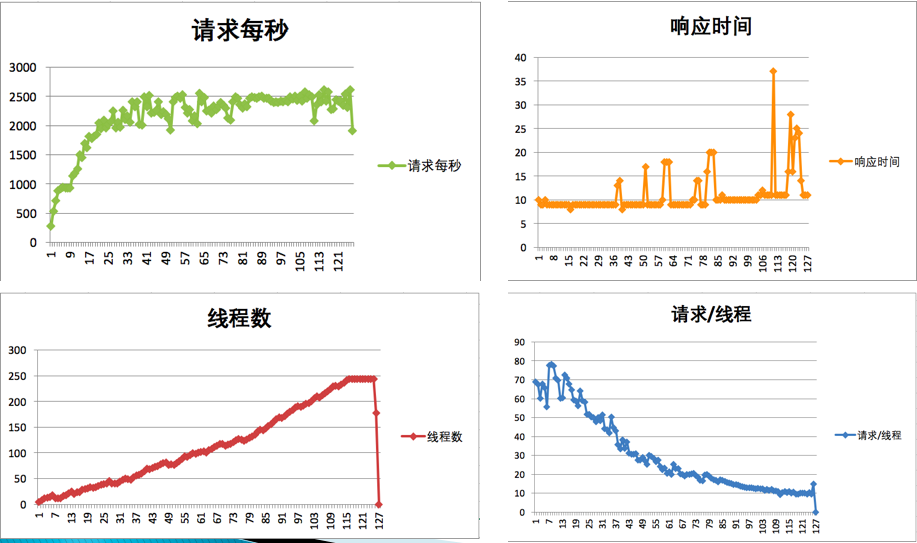
性能衰减的过程
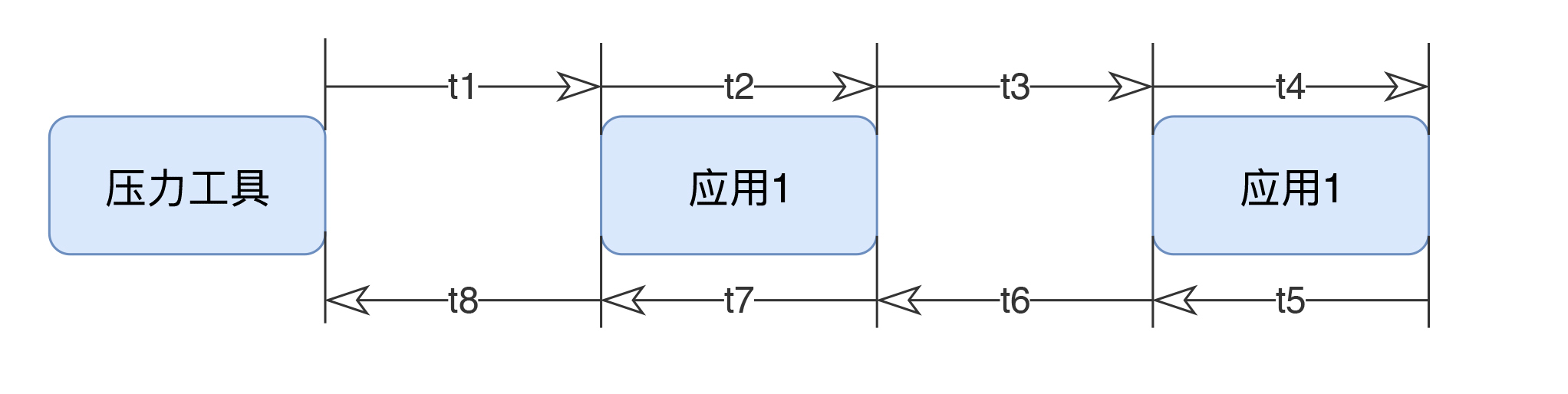
响应时间的拆分





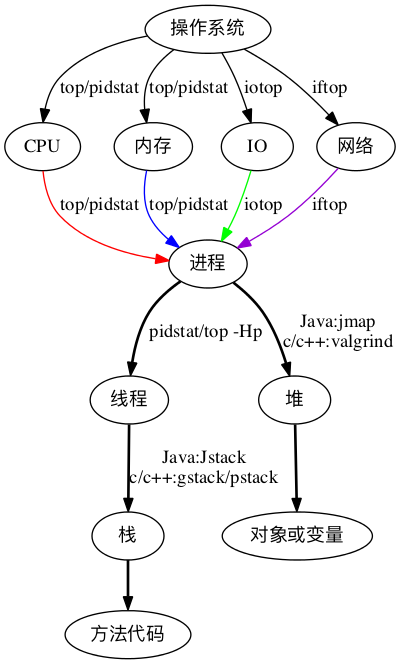
构建分析决策树



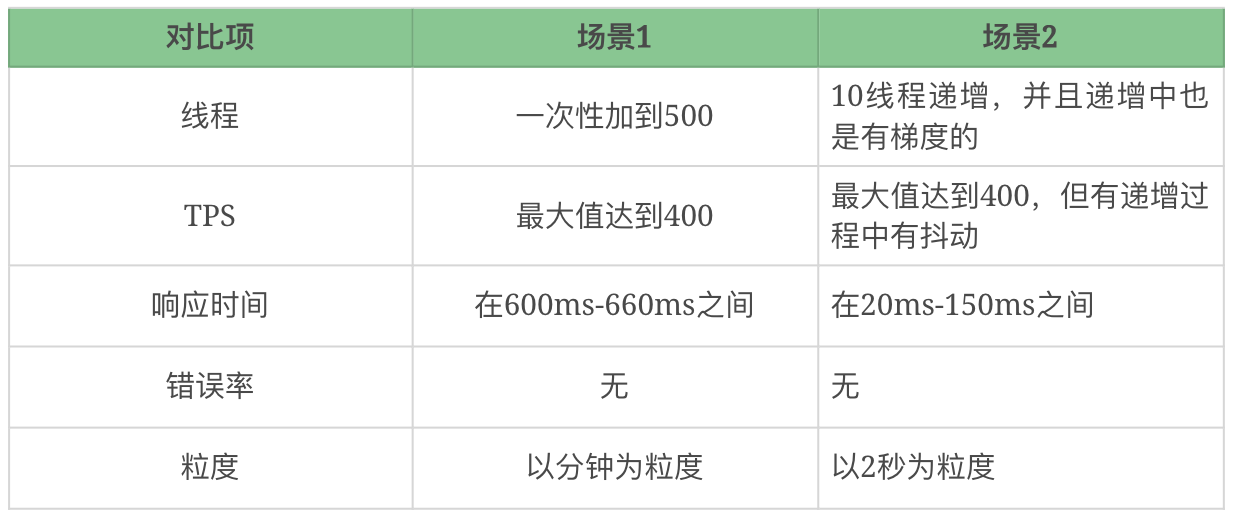
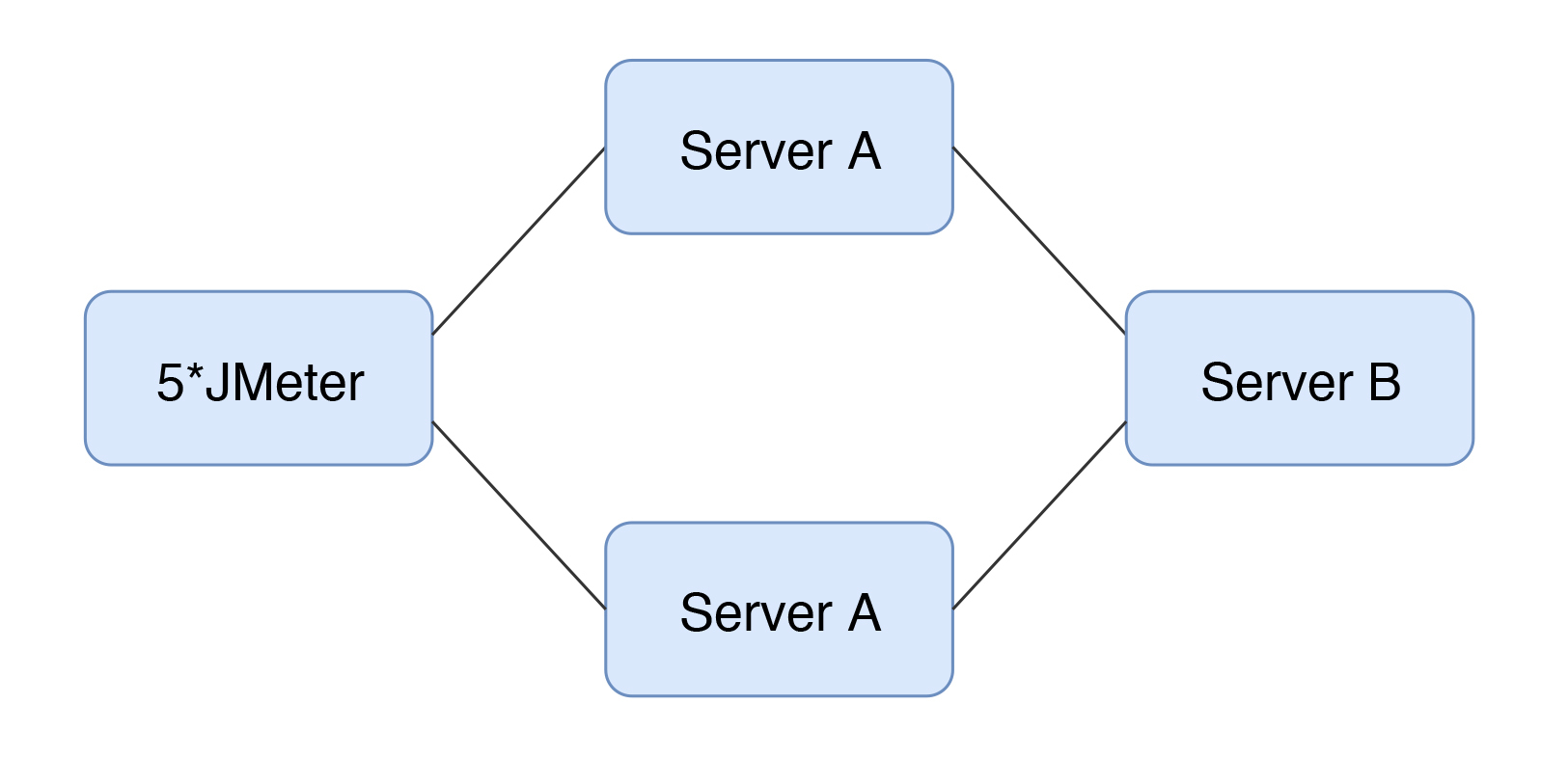
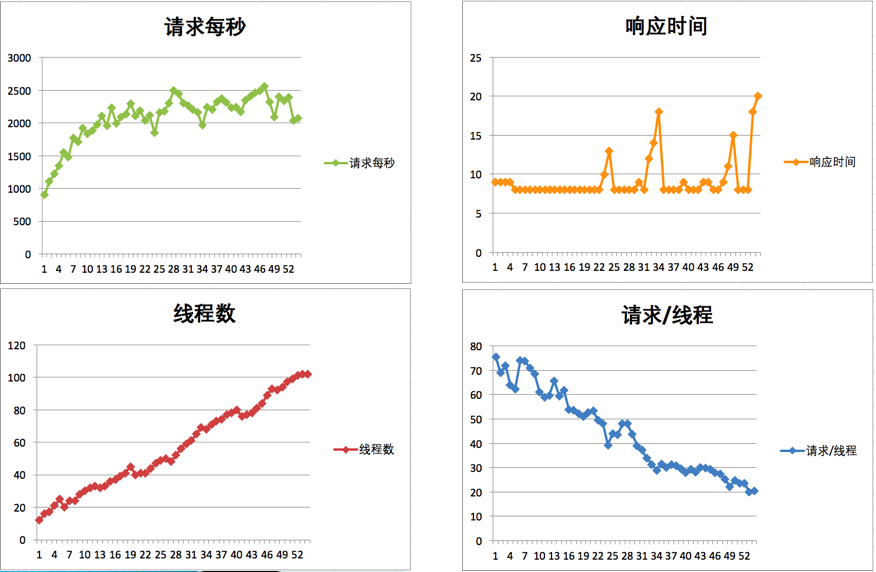
场景的比对
总结
思考题
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

本文深入探讨了性能分析的思路和方法,强调了性能测试分析的重要性。作者提出了性能测试分析的能力阶梯视图,包括工具操作、数值理解、趋势分析、相关性分析和证据链分析。重点讨论了瓶颈的精准判断和TPS曲线、响应时间的曲线对性能瓶颈的判断。文章还涉及了线程递增策略和性能衰减过程的分析,强调了合理的压力策略和性能瓶颈的出现。通过具体案例和图表分析,本文为性能测试人员提供了实用的指导意义,使读者能够快速了解性能分析的思路和方法。 文章还介绍了响应时间的拆分和构建分析决策树的重要性。在响应时间的拆分中,作者提到了从压力工具中拆分时间的逻辑以及在不同架构下的时间拆分方式。而构建分析决策树则被强调为性能测试分析人员不可或缺的一环,通过具体的数据库和操作系统分析决策树示例,阐述了分析决策树的重要性和实际应用。 总的来说,本文通过深入的性能分析案例和方法论,为读者提供了全面的性能测试分析指导,使其能够系统地了解性能分析的思路和方法,以及如何应用这些方法进行性能测试和分析。
2019-12-2745人觉得很赞给文章提建议
《性能测试实战 30 讲》,新⼈⾸单¥59

全部留言(136)
- 最新
- 精选
 小昭
小昭 今天的内容有点多,写了份总结,正好梳理一下思路 本节内容主要讲了性能分析思路。从6个方面来分析: 首先,要准确的判断瓶颈点。通过什么来判断呢?TPS曲线。TPS曲线能够告诉我们系统是否有瓶颈,以及瓶颈是否与压力有关。为什么不需要响应时间曲线来判断呢?因为响应时间主要是用来判断业务快慢的。 其次,我们要确定我们设置的性能场景是正确的,线程是逐渐递增的,而不应该一上来就上几百个线程。原因:1、直接上几百个线程不符合一般情况下的真实场景。2、即使是秒杀场景也有个“数据预热”的过程(我的理解,数据预热跟线程递增应该差不多,有一个由小到大逐渐增加的过程)3、对于TPS已经到达上限的系统来说,除了响应时间的增加,没有其他作用。 再次,我们要拥有能判断性能衰减的能力。如何判断?分段计算每线程每秒的TPS,如果这个数值开始变少,那么性能瓶颈就出现了。此时再随着线程的增加,性能逐渐衰减,TPS逐渐达到上限。 然后,我们知道性能开始衰减了,那么是什么原因导致的衰减?此时就需要对响应时间进行拆分,拆分的前提需要熟悉系统的架构,拆分的目的是要知道每个环节消耗的时间,拆分的方法可以通过日志,可以通过监控工具,也可以通过抓包(抓包应该需要和日志配合吧?以老师的例子来说,能抓到tomcat的请求和响应时间吗?我感觉不能……) 再然后,最重要的地方到了,我们要逐步构建自己的分析决策树。随着性能分析经验的累加,我们需要整理并总结每次遇到的性能问题以及相对应的解决方法,同时我们还要不断扩充自己的知识库:系统架构、操作系统、数据库、缓存、路由等等,并将这些知识与经验结合起来。重新梳理,由大到小,由宏观到细节,去画出自己的分析决策树。 最后一点感觉是对第一条的补充,而且应该也是对小白(比如我)的一个提点,当我们刚开始进行性能分析,没有思路的时候,那就可以通过这种替换法来帮助我们快速定位问题。当然,这种方法比较适合简单的系统,如果系统很复杂,这样替换不一定方便了。 这节课很重要,但是像我这种没有实际分析调优经验的小白来说,看懂跟理解好像还是缺少了实际操作在里头。这篇大概需要练习后再反复的回看。 今天的思考题答案基本写在上面的总结里了,如果有理解不正确的地方请老师指正。最后,感谢老师把宝贵的经验分享给我们,老师辛苦啦!
今天的内容有点多,写了份总结,正好梳理一下思路 本节内容主要讲了性能分析思路。从6个方面来分析: 首先,要准确的判断瓶颈点。通过什么来判断呢?TPS曲线。TPS曲线能够告诉我们系统是否有瓶颈,以及瓶颈是否与压力有关。为什么不需要响应时间曲线来判断呢?因为响应时间主要是用来判断业务快慢的。 其次,我们要确定我们设置的性能场景是正确的,线程是逐渐递增的,而不应该一上来就上几百个线程。原因:1、直接上几百个线程不符合一般情况下的真实场景。2、即使是秒杀场景也有个“数据预热”的过程(我的理解,数据预热跟线程递增应该差不多,有一个由小到大逐渐增加的过程)3、对于TPS已经到达上限的系统来说,除了响应时间的增加,没有其他作用。 再次,我们要拥有能判断性能衰减的能力。如何判断?分段计算每线程每秒的TPS,如果这个数值开始变少,那么性能瓶颈就出现了。此时再随着线程的增加,性能逐渐衰减,TPS逐渐达到上限。 然后,我们知道性能开始衰减了,那么是什么原因导致的衰减?此时就需要对响应时间进行拆分,拆分的前提需要熟悉系统的架构,拆分的目的是要知道每个环节消耗的时间,拆分的方法可以通过日志,可以通过监控工具,也可以通过抓包(抓包应该需要和日志配合吧?以老师的例子来说,能抓到tomcat的请求和响应时间吗?我感觉不能……) 再然后,最重要的地方到了,我们要逐步构建自己的分析决策树。随着性能分析经验的累加,我们需要整理并总结每次遇到的性能问题以及相对应的解决方法,同时我们还要不断扩充自己的知识库:系统架构、操作系统、数据库、缓存、路由等等,并将这些知识与经验结合起来。重新梳理,由大到小,由宏观到细节,去画出自己的分析决策树。 最后一点感觉是对第一条的补充,而且应该也是对小白(比如我)的一个提点,当我们刚开始进行性能分析,没有思路的时候,那就可以通过这种替换法来帮助我们快速定位问题。当然,这种方法比较适合简单的系统,如果系统很复杂,这样替换不一定方便了。 这节课很重要,但是像我这种没有实际分析调优经验的小白来说,看懂跟理解好像还是缺少了实际操作在里头。这篇大概需要练习后再反复的回看。 今天的思考题答案基本写在上面的总结里了,如果有理解不正确的地方请老师指正。最后,感谢老师把宝贵的经验分享给我们,老师辛苦啦!作者回复: 写的太好了。你是最认真的一个!
2020-03-16368 吴小喵看到构建分析决策树就吓死了,数据库的知识,操作系统的知识都不懂啊,o(╥﹏╥)o
吴小喵看到构建分析决策树就吓死了,数据库的知识,操作系统的知识都不懂啊,o(╥﹏╥)o作者回复: 慢慢来。反正不是吓死就是累死。
2019-12-2719- rainbowzhouj第一个问题:不能断的原因是保证在测试过程中资源分配的合理性,减少偏差,便于分析出当前环境中的性能瓶颈点。否则断开后系统动态资源会重新分配,造成分析偏差。 第二个问题:构建分析决策树的关键好比如何画一棵树。先确定主干(主要流程),然后添枝干(组成部分),最后画树叶(定位问题)。从上到下,从左到右,拆分...... 总的体会感觉给我这种测试野路子出身的工程师,又梳理了一遍如何定位问题的方法。让我对之前的工作实践中地操作有了进一步地理解。并且重新审视目前我所处的阶段:操作能力待加强。感谢老师,读完文章感到意犹未尽,希望在后续的课程能更加精彩。
作者回复: 多谢肯定。 一看评论就是练家子出身的。多做总结,就会有更多的收获。
2019-12-2714  hou请问老师,递增经验中, 为什么响应时间少,递增幅度小呢?
hou请问老师,递增经验中, 为什么响应时间少,递增幅度小呢?作者回复: 响应时间小的话,每个线程产生的TPS就高呀。 所以线程增加的幅度就要小一点。如果线程增加多了,因为单TPS高所以压力增加的就快,这样不得于产生明显的性能梯度用来分析。
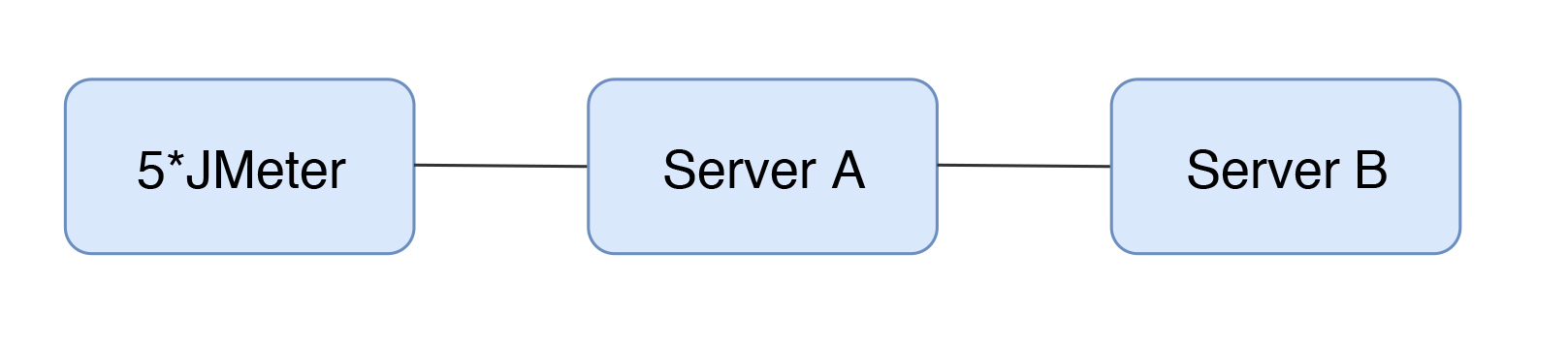
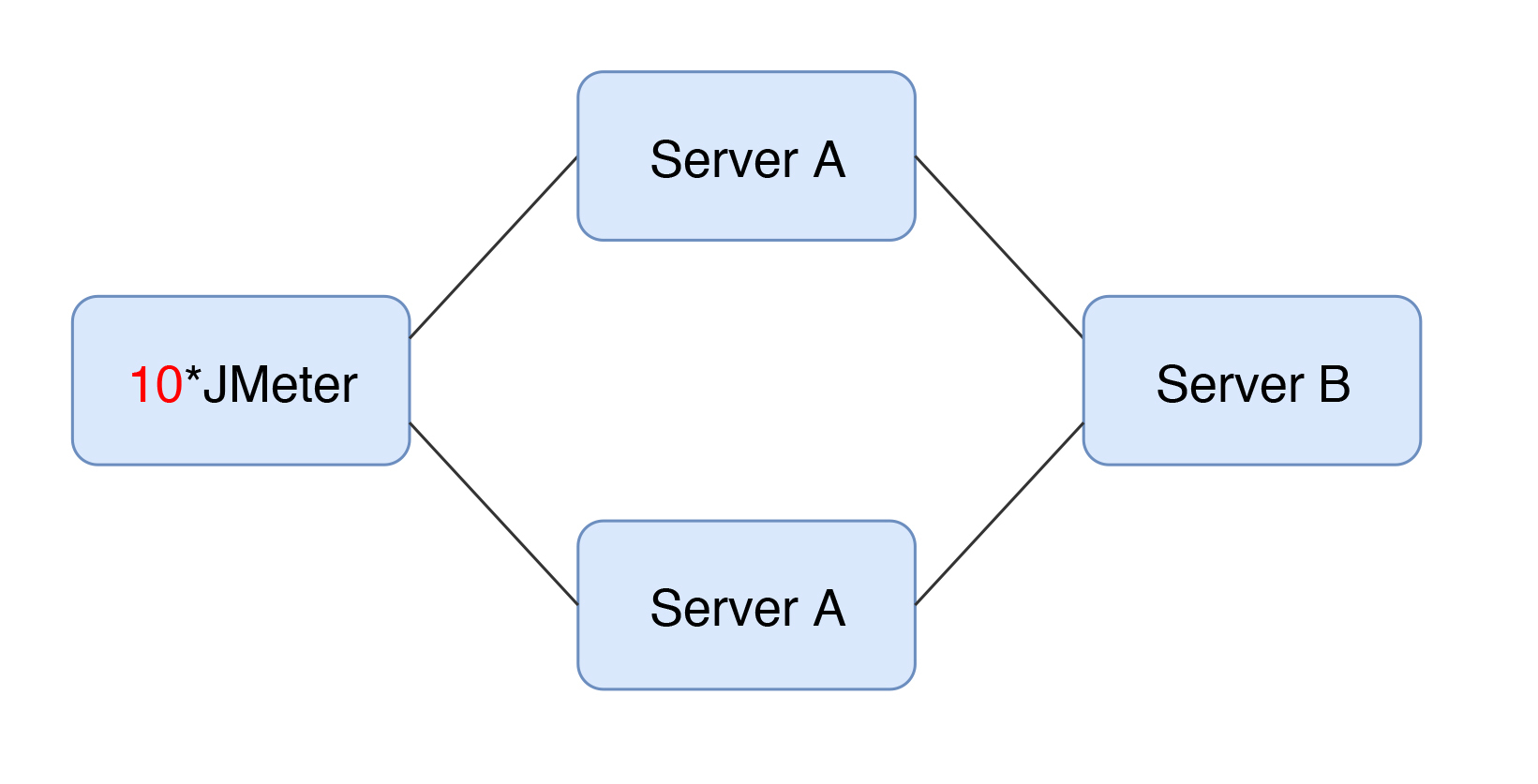
2020-03-04411 相看两不厌看了3遍,总结+疑问,希望高老师能回复 1. 判断是否存在瓶颈 通过tps曲线可得出的常见结论:压力越大,tps增幅越小,直至为零,存在瓶颈:tps规律性波动,压力只是将现象放大,存在瓶颈 通过响应时间曲线可得出的常见结论:随着压力增大,响应时间也增大,存在瓶颈 疑问:工作中经常是做高老师所谓的性能验证工作,通常测试环境操作系统相关配置就是和现网保持一致,尽量去测出应用和中间件配置的问题。经常会有疑问就是,接口达不到指标,不知道是不是在当前操作系统配置下,接口本身就是这样的能力了,不好判断是否接口存在问题。 2. 线程递增的策略 场景中的线程递增一定要连续,这样更符合真实场景,可能也给了系统预热的时间 工作中我一直都是按给定的并发数直接去压,看能否达到tps指标。以后我还是用梯度方式,可以看出趋势变化。 疑问:老师说随着响应时间,可以设置不同的梯度。我的理解是都可以按1平稳增加吧 3. 性能衰减的过程 老师通过例子展示的每个线程请求数降低,性能瓶颈就已经出现,其实还是响应时间增大了导致;但是瓶颈出现,并不意味着服务器的处理能力降低,相反,在并发数和响应时间达到某个点之前,处理能力就一直是增加的,事实就是在性能不断衰减的过程中,TPS达到上限。 4. 响应时间的拆分 可以通过日志打印请求响应时间、前端通过TTFB、复杂调用可以依靠调用链将点到点的时间拆分出来 工作中是绕过nginx,直接请求微服务接口进行压测,使用的工具就是调用链,真的非常方便 5. 构建分析决策树 这块感觉是重中之重,同时也是难上加难,我的理解是构建分析决策树是将可能影响性能的模块列出来后,再细分其下的属性、配置等,针对测试数据来判断是否为问题点。体现了性能工程师全面又专业的水准。 自己现在还差的很多,但是老师拿mysql举例还是给我实际工作有很大帮助。我工作中在msyql中就是加索引这一点,从来没像老师这样具体分析。后面详细学习下应用到工作中 6. 场景的比对 疑问:当5个jmeter,1台服务器时已经出现瓶颈,此时压力肯定够大了。但是添加2台服务器后,同样添加到10个jmeter,压力和服务器都在增加,TPS增加也是正常的啊。还是没能找出开始时的瓶颈所在。这节确实不理解。 总的来说,这篇文章在思路上确实让我学习到很多。希望后面能跟老师学习到具体的细节操作,才能在实战中游刃有余。
相看两不厌看了3遍,总结+疑问,希望高老师能回复 1. 判断是否存在瓶颈 通过tps曲线可得出的常见结论:压力越大,tps增幅越小,直至为零,存在瓶颈:tps规律性波动,压力只是将现象放大,存在瓶颈 通过响应时间曲线可得出的常见结论:随着压力增大,响应时间也增大,存在瓶颈 疑问:工作中经常是做高老师所谓的性能验证工作,通常测试环境操作系统相关配置就是和现网保持一致,尽量去测出应用和中间件配置的问题。经常会有疑问就是,接口达不到指标,不知道是不是在当前操作系统配置下,接口本身就是这样的能力了,不好判断是否接口存在问题。 2. 线程递增的策略 场景中的线程递增一定要连续,这样更符合真实场景,可能也给了系统预热的时间 工作中我一直都是按给定的并发数直接去压,看能否达到tps指标。以后我还是用梯度方式,可以看出趋势变化。 疑问:老师说随着响应时间,可以设置不同的梯度。我的理解是都可以按1平稳增加吧 3. 性能衰减的过程 老师通过例子展示的每个线程请求数降低,性能瓶颈就已经出现,其实还是响应时间增大了导致;但是瓶颈出现,并不意味着服务器的处理能力降低,相反,在并发数和响应时间达到某个点之前,处理能力就一直是增加的,事实就是在性能不断衰减的过程中,TPS达到上限。 4. 响应时间的拆分 可以通过日志打印请求响应时间、前端通过TTFB、复杂调用可以依靠调用链将点到点的时间拆分出来 工作中是绕过nginx,直接请求微服务接口进行压测,使用的工具就是调用链,真的非常方便 5. 构建分析决策树 这块感觉是重中之重,同时也是难上加难,我的理解是构建分析决策树是将可能影响性能的模块列出来后,再细分其下的属性、配置等,针对测试数据来判断是否为问题点。体现了性能工程师全面又专业的水准。 自己现在还差的很多,但是老师拿mysql举例还是给我实际工作有很大帮助。我工作中在msyql中就是加索引这一点,从来没像老师这样具体分析。后面详细学习下应用到工作中 6. 场景的比对 疑问:当5个jmeter,1台服务器时已经出现瓶颈,此时压力肯定够大了。但是添加2台服务器后,同样添加到10个jmeter,压力和服务器都在增加,TPS增加也是正常的啊。还是没能找出开始时的瓶颈所在。这节确实不理解。 总的来说,这篇文章在思路上确实让我学习到很多。希望后面能跟老师学习到具体的细节操作,才能在实战中游刃有余。作者回复: 看来这位同学是认真了。我也得认真回答下。 1,在固定的硬件配置下,要想知道接口有没有问题,就需要判断下接口响应时间的消耗,像apm、jvirsualvm,、arthas等工具都可以帮助你。这个判断是综合的判断,还要看硬件资源下是否已达到计算能力的最大值。再细节的就是要看方法级时间消耗是否合理。 2,按1平稳增加是可以的,只是在有些场景中,按1增加会需要比较长的时间,所以有时为了节省时间,我会增加的快一点。如果你有足够的时候,可以一直按1增加。这个没问题。 3. 理解正确! 4. 看来是真的实践了,这也是专栏的价值所在呀,能落地。哈哈。 5. 有思路就不怕落不了地。加油。不管是什么数据库,这思路都会有用。 6. 我写的应该在加了一台服务器之后,tps没有增加,所以才考虑增加多个jmeter的。这时压力有增加,就说明之前的压力不够。 我也觉得这篇是最有价值的,他的作用足以起到提纲挈领的作用。有疑问还可以接着问哈。
2020-11-1110- Geek_65c0a2这节课我也期待了好久。高老师写的字数多点,总感觉不够看👀
作者回复: 编辑小美女说我文章写太长了。😣😣
2019-12-27310  土耳其小土豆看高老师的文件,感觉都能看懂,但是高老师的问题,我却回答不了,特别是第一个问题。
土耳其小土豆看高老师的文件,感觉都能看懂,但是高老师的问题,我却回答不了,特别是第一个问题。作者回复: 练。你还年轻。
2019-12-307 那片海高老师有3个问题问下: 1、 你给了一个 性能场景递增的经验值,是 基于响应值 每秒增加的 线程数,最终达到目标线程数? 2、 线程不能断,如果是测试稳定性场景 也需要这样梯度加压吗 可以直接1s内加压到最大线程数? 3、 在jmeter工具中,梯度加压 是使用默认的线程组 ramp up设置呢, 还是安装插件后使用Stepping Thread Group 和 concurrency Thread Group 设置 ?
那片海高老师有3个问题问下: 1、 你给了一个 性能场景递增的经验值,是 基于响应值 每秒增加的 线程数,最终达到目标线程数? 2、 线程不能断,如果是测试稳定性场景 也需要这样梯度加压吗 可以直接1s内加压到最大线程数? 3、 在jmeter工具中,梯度加压 是使用默认的线程组 ramp up设置呢, 还是安装插件后使用Stepping Thread Group 和 concurrency Thread Group 设置 ?作者回复: 1. 是的。不过这个过程要多次调整。 2. 稳定性测试场景关注点不在递增那一阶段上,所以递增不递增都可以,就算递增用几分钟,也不影响稳定性测试整体场景的持续时间。 3. 这个都可以,取决于项目中要求的细致不细致了。装了插件我觉得会好一些,控制的细致。
2020-03-0626- suke关于线程递增的策略,基本几千的并发数就需要多台jmeter去分布式的压了,当压测事件持续几个小时的时候最后生成的压测报告都很大都有几个g,有很大概率生成报告失败,对于这个问题老师有什么好的实践经验么
作者回复: Jmeter+influxdb+grafana实时输出。
2020-03-0925 - qiaotaoli老师,再问一下,你文中发的递增经验值,后面的1-3指的是,比如第一个阶梯并发数是10,第二个阶梯并发数变为20-40,对么?另外,为什么响应时间越大后,并发幅度也变大呢?是因为响应时间变大后,并发幅度变化不大,可能看不出太大变化么?
作者回复: 响应时间越短,并发递增越小。
2020-01-065

