

02丨性能综述:TPS和响应时间之间是什么关系?

该思维导图由 AI 生成,仅供参考
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

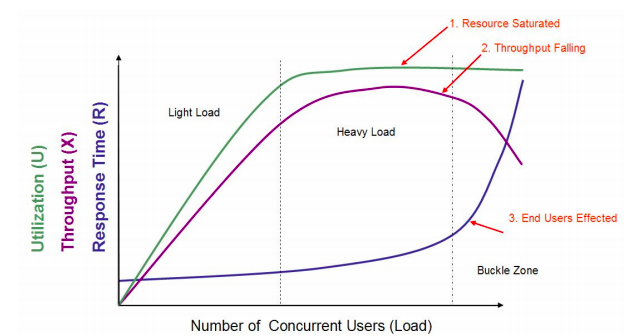
性能测试中的TPS和响应时间关系的探讨 本文深入探讨了性能测试中的TPS(每秒事务处理量)和响应时间之间的关系。作者首先对一个经典的性能场景示意图进行了详细解读和批判,指出了其中存在的误差和不合理之处,并提出了自己对于性能场景的理解。文章突出了对性能测试领域的理性思考和实践操作的重要性,强调了在实际项目中需要对性能场景进行具体的操作层面的配置。作者还对一些常见的性能测试概念进行了批驳,呼吁在性能测试领域更加注重实际操作和逻辑思路,而不是被过多的概念所冲乱。通过对性能场景示意图的解读和批判,以及对性能测试概念的批驳,读者可以了解到作者对于性能测试的深入思考和对于传统概念的质疑,以及对于性能测试领域发展方向的建议。文章强调了性能场景在性能项目中的核心地位,以及性能测试领域需要更加注重实际操作和逻辑思路的重要性。
《性能测试实战 30 讲》,新⼈⾸单¥59

全部留言(85)
- 最新
- 精选
 zuozewei第一个问题: 日常生活中价值可以通俗的理解为“合算不合算”,“值得不值得”,这里泛指对性能项目的有益程度。 在价值工程中,价值是个科学的概念,其定义为:V=F/C 式中: V——价值(Value) F——功能评价值(Function Worthy) C——总成本(Total Cost) 可见,包括三个基本要素,即价值、功能和成本。 功能可解释为用途、目的等等。对于一个性能项目来说,功能就是性能验证 or 性能分析 or 性能调优。 概念这里简单理解为“思维惯性”,其会决定做一个性能项目的行为模式,是指实现功能(性能验证 or 性能分析 or 性能调优)所支付费用(成本)。 SO,为了提升价值,在功能(目的)不变的情况下唯有适当的降低不合适的成本,那么这些杂七杂八,逻辑关系不符合真实的场景的概念势必需要淘汰。 第二个问题: 性能场景中的“场景”比较正宗的描述是:在既定的环境(包括动态扩展等策略)、既定的数据(包括场景执行中的数据变化)、既定的执行策略、既定的监控之下,执行性能脚本,同时观察系统各层级的性能状态参数变化,并实时判断分析场景是否符合预期。 那么如何看性能数据呢? 一般有两个核心即趋势和证据链。 分析数据趋势需要对一个时间序列数据的分析,一般采用线性回归分析。 对于证据链查找,需要对不同时间序列数据的分析,一般采用数据的相关性分析。
zuozewei第一个问题: 日常生活中价值可以通俗的理解为“合算不合算”,“值得不值得”,这里泛指对性能项目的有益程度。 在价值工程中,价值是个科学的概念,其定义为:V=F/C 式中: V——价值(Value) F——功能评价值(Function Worthy) C——总成本(Total Cost) 可见,包括三个基本要素,即价值、功能和成本。 功能可解释为用途、目的等等。对于一个性能项目来说,功能就是性能验证 or 性能分析 or 性能调优。 概念这里简单理解为“思维惯性”,其会决定做一个性能项目的行为模式,是指实现功能(性能验证 or 性能分析 or 性能调优)所支付费用(成本)。 SO,为了提升价值,在功能(目的)不变的情况下唯有适当的降低不合适的成本,那么这些杂七杂八,逻辑关系不符合真实的场景的概念势必需要淘汰。 第二个问题: 性能场景中的“场景”比较正宗的描述是:在既定的环境(包括动态扩展等策略)、既定的数据(包括场景执行中的数据变化)、既定的执行策略、既定的监控之下,执行性能脚本,同时观察系统各层级的性能状态参数变化,并实时判断分析场景是否符合预期。 那么如何看性能数据呢? 一般有两个核心即趋势和证据链。 分析数据趋势需要对一个时间序列数据的分析,一般采用线性回归分析。 对于证据链查找,需要对不同时间序列数据的分析,一般采用数据的相关性分析。作者回复: 你写的比我写的还要好。哈哈。下面的篇幅中就要有趋势和证据链的部分。这也是我觉得性能中最重要的部分。我混了混迹江湖十几年的依靠。
2019-12-176100 莫西 👫 小妞儿 👼 🎵老师,我有个疑问。“单交易容量测试”是对单独接口进行压测是吧?比如针对每一个接口都测了100、200、300并发。那么这个测试结果和“混合容量性能场景”测完的结果应该怎么对比分析呢?
莫西 👫 小妞儿 👼 🎵老师,我有个疑问。“单交易容量测试”是对单独接口进行压测是吧?比如针对每一个接口都测了100、200、300并发。那么这个测试结果和“混合容量性能场景”测完的结果应该怎么对比分析呢?作者回复: 不用对比分析。 做单交易容量测试是为了混合容量做基准数据的。举例来说。 业务1单交易容量能达到300TPS,且响应时间也非常好。而在混合中,可能业务1只需要100TPS,那就说明业务1不会成为混合容量的瓶颈点。 如果业务1单交易容量的时候只能达到50,而在混合场景中需要它能跑到100,怎么办?这就只能在单交易的时候做优化了。 所以单交易容量测试是为了确定是不是应该在单交易容量阶段做性能优化。 题外话:要注意的是混合容量中有相互的逻辑关系,这个必须到混合容量的时候才会出现。
2019-12-30747- suke但是由于用户数增加的幅度会超过队列长度,所以 TPS 仍然会增加 这句话没明白这个逻辑是为什么?能详细解释一下么
作者回复: tps之所以会增加是因为线程数的增加,而tps之所以增加的缓慢,是因为性能已经衰减。性能衰减必然产生请求队列。如果所有增加的请求都被放在了队列中,那处理的请求数就不会增加,响应也不会增加,tps就不变了。
2020-03-08839  丑得带感有个问题想请教一下老师: 关于TPS与并发线程数,正常应该是以TPS作为系统容量的衡量标准,这个在系统性能比较好的时候很好和客户沟通(即TPS>并发数)。 但是在系统性能较低的项目中,有时候就很难和客户沟通,比如一次项目中,系统在2000并发,系统TPS就到了最大1500多,RT、资源利用率那些也还好;但是接着增加并发到5000时,TPS基本比较平稳,没有什么下降,响应时间才刚刚超时。 对于这种情况,在估算系统可支撑最大在线人数时,客户就觉得应该依据最大并发数5000去算(RT可接受时),而不是依据最大系统TPS1500多去算,他们觉得你的每1个并发都是模拟的1个用户在实际使用,而响应时间没超时,就说明可以支撑这个并发数的用户同时使用(假设并发度100%时)。 我从响应时间分析,感觉他们的说法也没毛病,但是理智告诉我,从TPS看系统每秒最大也就能处理1500多,其余的请求应该会在队列超时,或被拒绝,但是5000并发持续压测10分钟,也没看到大量超时或报错(千分之一以下),拿不出证据来支撑,感觉真是性能三观都要被颠覆,一直耿耿于怀,还请老师解惑!
丑得带感有个问题想请教一下老师: 关于TPS与并发线程数,正常应该是以TPS作为系统容量的衡量标准,这个在系统性能比较好的时候很好和客户沟通(即TPS>并发数)。 但是在系统性能较低的项目中,有时候就很难和客户沟通,比如一次项目中,系统在2000并发,系统TPS就到了最大1500多,RT、资源利用率那些也还好;但是接着增加并发到5000时,TPS基本比较平稳,没有什么下降,响应时间才刚刚超时。 对于这种情况,在估算系统可支撑最大在线人数时,客户就觉得应该依据最大并发数5000去算(RT可接受时),而不是依据最大系统TPS1500多去算,他们觉得你的每1个并发都是模拟的1个用户在实际使用,而响应时间没超时,就说明可以支撑这个并发数的用户同时使用(假设并发度100%时)。 我从响应时间分析,感觉他们的说法也没毛病,但是理智告诉我,从TPS看系统每秒最大也就能处理1500多,其余的请求应该会在队列超时,或被拒绝,但是5000并发持续压测10分钟,也没看到大量超时或报错(千分之一以下),拿不出证据来支撑,感觉真是性能三观都要被颠覆,一直耿耿于怀,还请老师解惑!作者回复: 在你的描述中,响应时间也还好,是什么程度的还好?如果从2000到5000,TPS平移,那响应时间至少上升了2.5倍。 即使这时还没到响应时间超时,也只能说明超时时间比较长,请求都放在队列中去了。对终端用户来说,就是感觉上的系统卡死。 如果这时你再上线程,是不是超时就会增加了? 其实就是:压力机线程、TPS、RT之间的转换关系。 从系统用户的角度来看,系统性能是在不断下降的。而不是技术上来看,没有超时和报错就是性能还可以支撑。
2019-12-23330- jy递增策略:比如分钟增加10个线程,100个线程要10分钟才全部启动完成,再持续运行10分钟,但是聚合报告统计的是这20分钟的tps,tps值明显会被前面10分钟拉低,如果这样测试出来的tps不达标怎么办?如果每分钟启动50个,2分钟即可全部启动,持续运行10分钟,tps达标。如何解释这两种情况呢?
作者回复: 所以判断最大TPS的时候,不是用聚合报告中的那个平均TPS值。而是看整个TPS曲线的最大TPS值。。
2020-05-24319  微冷花谢请老师允许我一个新手留下自己的思考和疑问? 第一问,自己的思考是很多理论上的概念,不仅仅加深了我们对性能测试的理解的困难程度。同时,在实际发现性能瓶颈,实施性能优化,很多时候是没有太多帮助的。 第二问,之所以需要连续的一个符合实际的加压过程,是因为能够获取更加完整且准确的证据链。 个人疑问:关于如何去设计递增加压的过程,根据什么去设计,如何去设计出符合我们系统的加压过程? 对于老师的两问,个人理解不一定正确,希望老师指正。 对于个人疑问,麻烦老师留下思路。 最后,老师的讲的真实在,谢谢老师的分享。虽然有一些我还没办法懂,但是我会极力的去吸收。谢谢老师!
微冷花谢请老师允许我一个新手留下自己的思考和疑问? 第一问,自己的思考是很多理论上的概念,不仅仅加深了我们对性能测试的理解的困难程度。同时,在实际发现性能瓶颈,实施性能优化,很多时候是没有太多帮助的。 第二问,之所以需要连续的一个符合实际的加压过程,是因为能够获取更加完整且准确的证据链。 个人疑问:关于如何去设计递增加压的过程,根据什么去设计,如何去设计出符合我们系统的加压过程? 对于老师的两问,个人理解不一定正确,希望老师指正。 对于个人疑问,麻烦老师留下思路。 最后,老师的讲的真实在,谢谢老师的分享。虽然有一些我还没办法懂,但是我会极力的去吸收。谢谢老师!作者回复: 第一问:理解的很对。理论来自于实践,并且要再应用到实践中去。 才是真正的有价值。 第二问:前半句说的对,就是要一个符合实际的加压过程。后面句方向有点偏,连续不是为了获取证据链,而是为了判断瓶颈点的出现和性能衰减的过程,分析这个过程产生的压力数据、监控数据得到瓶颈点的过程才是获取证据链的。 针对个人疑问:后面的场景中,会更详细的提到。 在这里简单说一下,递增加压的过程是为了让一个系统的性能衰减过程可以清晰判断出来。而递增的量级就完全取决于业务系统的能力了。如果业务处理的响应时间长,在系统瓶颈还未明显出现时就递增的快一些;反之就慢一些。后续篇幅中再细看吧。
2019-12-1829 IT媚娘性能场景为什么要连续?而不是断开? 递增线程数,记录每次的性能指标,对比分析,画曲线,来观察指标变化的趋势,找出性能瓶颈,或者服务器最大处理能力
IT媚娘性能场景为什么要连续?而不是断开? 递增线程数,记录每次的性能指标,对比分析,画曲线,来观察指标变化的趋势,找出性能瓶颈,或者服务器最大处理能力作者回复: 理解的非常正确。
2019-12-1727 LensAclrtn1. 为什么说市场上的概念对性能项目实施没有太大价值? 看完第1、2讲,感觉老师真的是很真诚很负责,说出了很多我们想说不敢说的话 就拿老师举例的配置测试来说,我当时陆陆续续接触到这么些概念的时候就在想,这都谁造出来的词,连配置这么个基本操作也要上升到XX测试的程度...最搞笑的是还有一种叫“文档测试”的.感觉这些都太重理论轻实践了. 说个题外话,我以前虽然也对性能测试、压力测试、负载测试颇有微词,但自己也不能总结提炼出一个更好的分类框架或者体系, 今天看到老师用性能场景来作为划分依据,就是重实践的表现,很值得我们学习呢. 2. 为什么性能场景要连续不要断开? 说来惭愧,我第一个负责压测的时候就是用的离散的性能场景,也就是一次测试过程中线程数是固定的. 现实中的性能场景都不是一成不变的, 用固定的线程数去压测的意义很有限
LensAclrtn1. 为什么说市场上的概念对性能项目实施没有太大价值? 看完第1、2讲,感觉老师真的是很真诚很负责,说出了很多我们想说不敢说的话 就拿老师举例的配置测试来说,我当时陆陆续续接触到这么些概念的时候就在想,这都谁造出来的词,连配置这么个基本操作也要上升到XX测试的程度...最搞笑的是还有一种叫“文档测试”的.感觉这些都太重理论轻实践了. 说个题外话,我以前虽然也对性能测试、压力测试、负载测试颇有微词,但自己也不能总结提炼出一个更好的分类框架或者体系, 今天看到老师用性能场景来作为划分依据,就是重实践的表现,很值得我们学习呢. 2. 为什么性能场景要连续不要断开? 说来惭愧,我第一个负责压测的时候就是用的离散的性能场景,也就是一次测试过程中线程数是固定的. 现实中的性能场景都不是一成不变的, 用固定的线程数去压测的意义很有限作者回复: 能有这样的评论,我觉得很欣慰,有认同感。 我深受概念扰乱多年,总是得跟人解释一顿我认为对的概念和操作方式。
2019-12-1766 分清云淡QPS=并发数*常数/RT , 也就是到瓶颈后加并发后RT增加QPS不变,那么瓶颈基本在RT增加的节点上。
分清云淡QPS=并发数*常数/RT , 也就是到瓶颈后加并发后RT增加QPS不变,那么瓶颈基本在RT增加的节点上。作者回复: 你理解的很对。 对性能来说,性能瓶颈肯定是在RT增加的节点的。
2019-12-1666 Cyx老师,这段话没有懂,没有明白为什么TPS仍然会增加——很多时候,重负载区的资源饱和,和 TPS 达到最大值之间都不是在同样的并发用户数之下的。比如说,当 CPU 资源使用率达到 100% 之后,随着压力的增加,队列慢慢变长,但是由于用户数增加的幅度会超过队列长度,所以 TPS 仍然会增加,也就是说资源使用率达到饱和之后还有一段时间 TPS 才会达到上限。
Cyx老师,这段话没有懂,没有明白为什么TPS仍然会增加——很多时候,重负载区的资源饱和,和 TPS 达到最大值之间都不是在同样的并发用户数之下的。比如说,当 CPU 资源使用率达到 100% 之后,随着压力的增加,队列慢慢变长,但是由于用户数增加的幅度会超过队列长度,所以 TPS 仍然会增加,也就是说资源使用率达到饱和之后还有一段时间 TPS 才会达到上限。作者回复: 根据响应时间的增加幅度计算就可以知道。假设响应时间增加了50%,线程数增加了100%,那tps就还会增加。
2020-12-115

