

02 | 程序员也要关心整个系统和公司成本吗?

该思维导图由 AI 生成,仅供参考
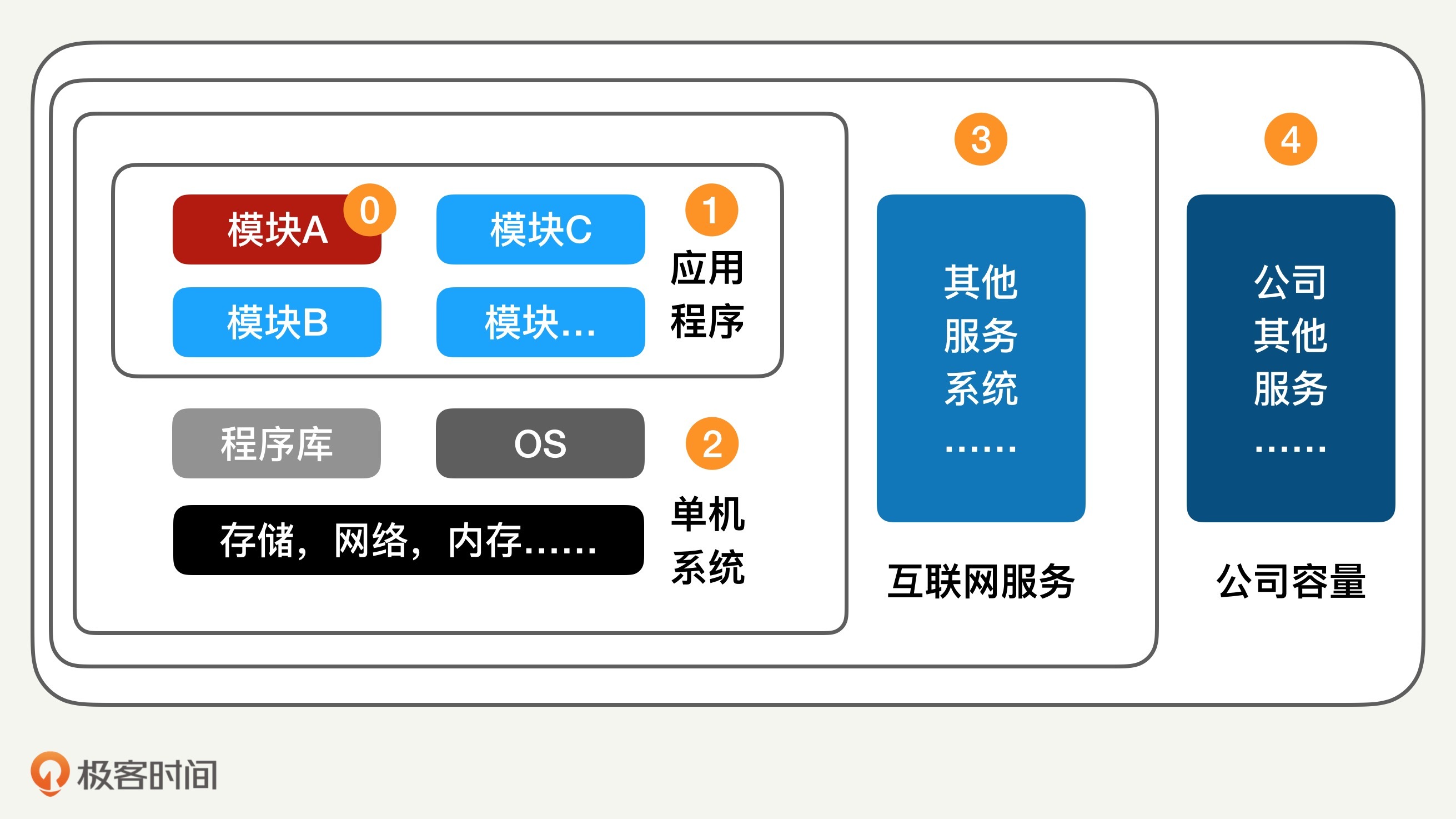
应用程序的性能(标示 1)
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

本文强调了程序员不仅需要关注代码性能,还需关心整个系统和公司成本。模块性能对应用程序、单机系统、互联网服务和公司成本都有重要影响。文章指出,了解单机系统的软硬件构件对设计高效率的软件至关重要。在互联网服务中,每个程序员需要从整个大局出发,设计模块和交互机制,以避免对上下游模块造成不良影响。同时,文章还强调了对系统容量的效率提升和对共同的地球的责任。通过案例强调了上游模块在处理下游模块性能问题时的重要性。总之,程序员需要关注整个系统和公司成本,以确保代码性能和系统性能的协调发展。
《性能工程高手课》,新⼈⾸单¥59

全部留言(19)
- 最新
- 精选

 西西弗与卡夫卡上游系统不做避让设计,异常情况下就是自己对自己发起了DDoS攻击。下游系统也要做熔断设计,以保护自己。
西西弗与卡夫卡上游系统不做避让设计,异常情况下就是自己对自己发起了DDoS攻击。下游系统也要做熔断设计,以保护自己。作者回复: 没错;双重保护最好。
2019-12-0416 Liang Xu想到了Bufferbloat 显现. 如果很多人同时应用下游服务, 一遇到堵塞就开始减少请求, 这样就是所有人都减少. 一段时间之后是不是就产生周期性的算力需求? 学网络的时候学的
Liang Xu想到了Bufferbloat 显现. 如果很多人同时应用下游服务, 一遇到堵塞就开始减少请求, 这样就是所有人都减少. 一段时间之后是不是就产生周期性的算力需求? 学网络的时候学的作者回复: 很好的思考。好的退避机制会引入随机数来决定行为,可以避免和极大地降低周期性的可能。
2019-12-059 Middleware
Middleware 为了国家,为了地球,优化优化代码吧
为了国家,为了地球,优化优化代码吧作者回复: 哈哈,说得没错哦. :)
2019-12-038 glutton老师好,刚刚看到上新的这个课,就出手啦,目前正在做这方面的工作,特别缺少这种系统的讲解 1,我负责的系统,是整个公司服务链路中重要一环,目前全链路延时在200ms左右,允许给我们系统的最大时延是50ms(极端情况跨异地数据中心) 2,刚刚看到机械硬盘、SSD等对比,希望后续的课程,能详细列出成本、性能数据,以供参考 3,希望能多讲一些实例,比如某系统架构演化过程,全面的展现设计思考方式、限制条件等 最后,这是我下定决心要学完的一门课,也是我第一次发了留言的课,盼更新!祝顺利!
glutton老师好,刚刚看到上新的这个课,就出手啦,目前正在做这方面的工作,特别缺少这种系统的讲解 1,我负责的系统,是整个公司服务链路中重要一环,目前全链路延时在200ms左右,允许给我们系统的最大时延是50ms(极端情况跨异地数据中心) 2,刚刚看到机械硬盘、SSD等对比,希望后续的课程,能详细列出成本、性能数据,以供参考 3,希望能多讲一些实例,比如某系统架构演化过程,全面的展现设计思考方式、限制条件等 最后,这是我下定决心要学完的一门课,也是我第一次发了留言的课,盼更新!祝顺利!作者回复: 谢谢留言和建议。我会尽量满足要求。学完后欢迎和我交流感想。SSD和硬盘的价格和性能其实一直在变(技术演化很快),所以只能给出大体对比,你可以Google搜索一下最新的价格以及每个厂商/型号的性能。如果有具体的问题(比如性能指标),我也可以看看帮你找找。
2019-12-0335- 大名府卢员外老师 文中四种存储介质一图ssd的应该比hdd的读写速度要快 而且我感觉图中两者应该调换一下
作者回复: 不太明白,你是说那张有5个指标的图吗?
2020-02-1833  Q作为运维工程师,请问老师该怎么在性能工程领域帮助开发同事? 实现自我的成长。希望老师能在接下来的一些课能具体谈谈这方面的东西。
Q作为运维工程师,请问老师该怎么在性能工程领域帮助开发同事? 实现自我的成长。希望老师能在接下来的一些课能具体谈谈这方面的东西。作者回复: 你是问开发和运维的有效配合吗?这方面有好几处: -程序设计阶段,他们最好征询你们的意见,因为你们知道硬件,系统和容量;一般来收开发人员不太关心这些。 -程序测试阶段。你们要和他们密切交互,将“问题”扼杀在摇篮里。 -部署阶段。你们主导,但是需要经常让他们改进发现的问题。 -运行阶段。比如修Bug就是。
2019-12-042 梅子黄时雨我看完就一句话深深地映入我脑海——多快好省。
梅子黄时雨我看完就一句话深深地映入我脑海——多快好省。作者回复: 你历史一定学得很好。哈哈
2019-12-032 Jxin1.我负责的系统模块是一个老项目的子系统。各服务间rpc调用超时均为6s。这会导致只要系统中任意一个子系统出现问题,由于这个6s等待的存在,就会导致所有关系方线程资源都被占用着。于是我调小了超时时间。然后快速失败却更加剧了故障系统的故障。最终我在入口处用mq销峰控制消费速率或则说任务并行度,借此保障系统稳定。然而,这依旧是有问题的,存在很大的浪费。因为如果瓶颈系统能支撑,单机能并行200的任务,而不能支撑就只能限流在50,这之间的资源浪费实属可惜。瓶颈系统优化又管不到,我倒是愿意研究,但职责有界,连代码都看不到。这种情况就比较无力了。 2.对老师提到的“指数退避机制”很感兴趣,有具体落地的技术方案吗?
Jxin1.我负责的系统模块是一个老项目的子系统。各服务间rpc调用超时均为6s。这会导致只要系统中任意一个子系统出现问题,由于这个6s等待的存在,就会导致所有关系方线程资源都被占用着。于是我调小了超时时间。然后快速失败却更加剧了故障系统的故障。最终我在入口处用mq销峰控制消费速率或则说任务并行度,借此保障系统稳定。然而,这依旧是有问题的,存在很大的浪费。因为如果瓶颈系统能支撑,单机能并行200的任务,而不能支撑就只能限流在50,这之间的资源浪费实属可惜。瓶颈系统优化又管不到,我倒是愿意研究,但职责有界,连代码都看不到。这种情况就比较无力了。 2.对老师提到的“指数退避机制”很感兴趣,有具体落地的技术方案吗?作者回复: 恩,具体的系统真的事很复杂,要考虑各种因素。指数退让其实道理很直白易懂;实践起来也容易。基本道理就是如果不能及时获得下游回答,就假设下游很忙,那就降低请求速度(用指数方式降低,比如每次降低一半)。比如超时等待可以持续增加。
2019-12-0322- 董飞老师,您好。我是做测试的,怎样往性能测试工程师发展?具体都要学什么?编程要学到什么程度?谢谢老师解答。
作者回复: 这个专栏里面应该会有些答案帮助。
2019-12-032  夜空中最亮的星作为运维工程师 终于找到了下一个方向 性能工程师
夜空中最亮的星作为运维工程师 终于找到了下一个方向 性能工程师作者回复: :) 终于找到组织了!
2019-12-022

