

16 | 脑洞大开:GUI测试还能这么玩(Page Code Gen + Data Gen + Headless)?

该思维导图由 AI 生成,仅供参考
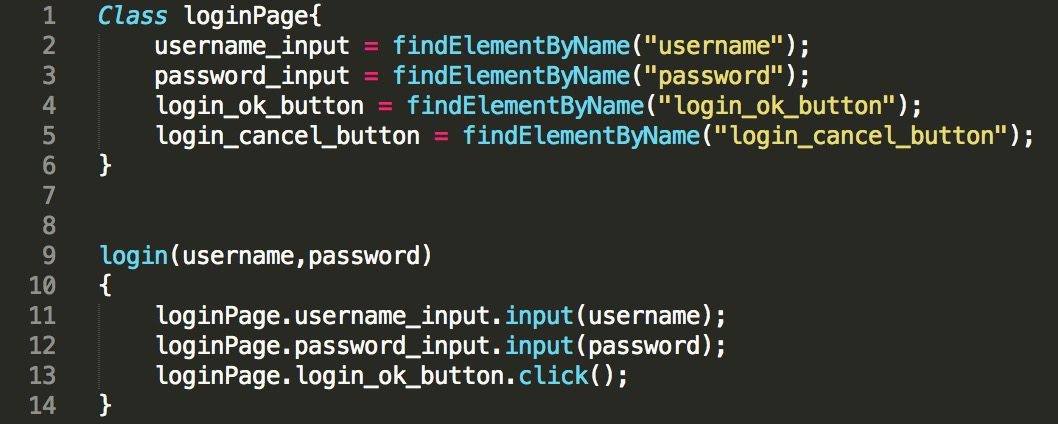
页面对象自动生成
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

无头浏览器、页面对象自动生成和GUI测试数据自动生成是GUI测试中的三个有趣的知识点。页面对象自动生成技术可以减少页面对象的维护成本,而GUI测试数据自动生成则能根据输入数据类型和自定义规则库自动生成测试输入数据。无头浏览器在GUI测试中有诸多优势,如测试执行速度更快、减少对测试执行的干扰等。文章还介绍了Headless Chrome及其配套的Puppeteer框架,为读者提供了实践应用的建议。 文章内容涵盖了无头浏览器、页面对象自动生成和GUI测试数据自动生成这三个有趣的GUI测试知识点。页面对象自动生成技术能降低维护成本,GUI测试数据自动生成能根据输入数据类型和自定义规则库生成测试输入数据。无头浏览器在GUI测试中具有诸多优势,如快速执行测试、减少执行干扰等。此外,文章还介绍了Headless Chrome及其配套的Puppeteer框架,为读者提供了实践应用的建议。
《软件测试 52 讲》,新⼈⾸单¥68

全部留言(28)
- 最新
- 精选
 Geek_84a77e老师,是每篇文章有时间限制吗?可否细致的讲解一下,如何自动化生成页面对象,如何自动化生成测试数据?我们现在的理解很大部分是停留在概念上,来这儿学习的理由也是老师能够给我们一个直观的认识关于这些技术,或者每篇文章能否提供个链接供我们看看源码,切身体验一下封装等其他文章中提到的技术,多谢
Geek_84a77e老师,是每篇文章有时间限制吗?可否细致的讲解一下,如何自动化生成页面对象,如何自动化生成测试数据?我们现在的理解很大部分是停留在概念上,来这儿学习的理由也是老师能够给我们一个直观的认识关于这些技术,或者每篇文章能否提供个链接供我们看看源码,切身体验一下封装等其他文章中提到的技术,多谢作者回复: 关于页面对象自动生成的具体实现细节还是比较复杂的,因为采用不同前端开发框架的页面的生成还都不太一样,我看看是否有可能搞个git给点示例代码。至于测试数据自动生成主要是思想方法,用excel➕vba就能轻易完成大部分的功能,当然用代码实现也是可以的,但是文章本身还是以讲方法为主,不会去讲具体怎么写代码来实现这个功能。
2018-08-0326 sylan2151.如果使用 selenium + xpath,应该可以解决大部分的控件识别,chrome 支持右键一键拷贝 xpath,贼方便; 2.关于测试数据的自动生成,个人感觉目前测试中,场景测试重要性是最高的,但是自动生成可能解决不了场景覆盖的问题,不过如果借鉴最新的机器学习算法,说不定有新发现; 3.对于无头浏览器,我的疑问是,既然是 GUI 测试,无头浏览器怎么保证测试效果的可靠性呢,测试结果是和常规浏览器一样可信么?毕竟自动化的目的还是为了测试,而不是为了自动。 欢迎沟通交流,公众号「sylan215」
sylan2151.如果使用 selenium + xpath,应该可以解决大部分的控件识别,chrome 支持右键一键拷贝 xpath,贼方便; 2.关于测试数据的自动生成,个人感觉目前测试中,场景测试重要性是最高的,但是自动生成可能解决不了场景覆盖的问题,不过如果借鉴最新的机器学习算法,说不定有新发现; 3.对于无头浏览器,我的疑问是,既然是 GUI 测试,无头浏览器怎么保证测试效果的可靠性呢,测试结果是和常规浏览器一样可信么?毕竟自动化的目的还是为了测试,而不是为了自动。 欢迎沟通交流,公众号「sylan215」作者回复: 高质量的留言。👍!自动测试数据生成的应用场景主要是覆盖边界值和典型易出错场景,应用价值还是比较大的。关于无头浏览器,目前的应用领域主要在爬虫和devops中的环境健康检查,就是去看一下网站基本的页面是否可以打开,最最基本的smoke用例是否可以通过,如果不行,那就会把环境健康状态标红,并从可用列表中移除
2018-08-03224 猪猪老师讲一下如何自动生成页面模型的原理,不要一带而过
猪猪老师讲一下如何自动生成页面模型的原理,不要一带而过作者回复: 这个具体的我实现细节还是有点复杂的,如果是静态页面,那就好解析和分类页面元素的源代码,如果页面是react页面,那就要要基于react来做解析,不同前端框架的页面解析还都不同,有很多细节要处理。
2018-08-037 杜艳建议可以不可以不要伪代码。写一个真实可用的java代码
杜艳建议可以不可以不要伪代码。写一个真实可用的java代码作者回复: 采用伪代码的目的是为了更简单直观的说明问题的本质以及代码的实现思路,而尽量避免过多的不相关细节,如果使用实际java代码,放在文档中你看到的就是大段的代码,说明问题本质的代码就会混在其中,不容易说明问题。另外,现在还有很多自动化测试是基于python和ruby的,所以说明原理的部分我还是倾向于使用伪代码。后续文章会有一些实际的例子,那时候我会采用真实可用的java代码。 ,
2018-08-035 kaiserinKatalon Studio现在的普及率怎么样?感觉大多数人还是用的robotframework
kaiserinKatalon Studio现在的普及率怎么样?感觉大多数人还是用的robotframework作者回复: 现在来看,对于互联网企业,你提的这两个框架的普及率都不算太高。
2018-10-092 胖虫子为什么大家用类似katalon这样的工具热情不高,但自己去写自动化框架的热情高
胖虫子为什么大家用类似katalon这样的工具热情不高,但自己去写自动化框架的热情高作者回复: 蛮同意你的观点的,很多也是处于测试人员自身技能发展的考虑
2018-08-311 Robert小七企业实战中,无头浏览器的应用程度如何?是否可以用多线程来替代grid集群
Robert小七企业实战中,无头浏览器的应用程度如何?是否可以用多线程来替代grid集群作者回复: 无头浏览器的应用并不是太多,很多是用来做爬虫,自动化测试的应用相对比较少,是的,完全可以用selenium grid来代替。但是最近由于google官方发布了headless chrome和对应的测试框架,所以估计后面会有更多的应用。
2018-08-031 johnny老师,希望能在git提供部分章节的代码实现。比如第14节的内容看完还是只停留在概念,如果有示例代码就比较方便理解
johnny老师,希望能在git提供部分章节的代码实现。比如第14节的内容看完还是只停留在概念,如果有示例代码就比较方便理解作者回复: 很好的建议,下次一定提供完整可运行的代码示例,但是讲解还是采用伪代码可以帮助更好的理解
2018-11-20 星如何生成页面对象?
星如何生成页面对象?作者回复: 这个问题不是一两句话可以说清楚的,回头我去搞个git的代码示例。
2018-08-05 橄榄没有实际应用过
橄榄没有实际应用过作者回复: 没关系,知道有这些概念和方法就好,uft等商业gui自动化工具都已经实现了部分功能,使用起来还是很简单
2018-08-03

