
16|缓存:节省使用大模型的成本
郑晔

你好,我是郑晔!
上一讲,我们讲了一种工程实践——长期记忆,它可以让我们的应用更加了解自己的用户。这一讲,我们继续,讨论另外一种工程实践——缓存。
缓存
计算机科学中只有两大难题:缓存失效和命名。
—— Phil Karlton
稍有经验的程序员对缓存都不陌生,在任何一个正式的工程项目上都少不了缓存的身影。硬件里面有缓存,软件里面也有缓存,缓存已经成了程序员的必修课。
我们为什么要使用缓存呢?主要就是为了减少访问低速服务的次数,提高访问速度。大模型显然就是一个低速服务,甚至比普通的服务还要慢。
为了改善大模型的使用体验,人们已经做出了一些努力,比如采用流式响应,提升第一个字出现在用户面前的速度。缓存,显然是另外一个可以解决大模型响应慢的办法。
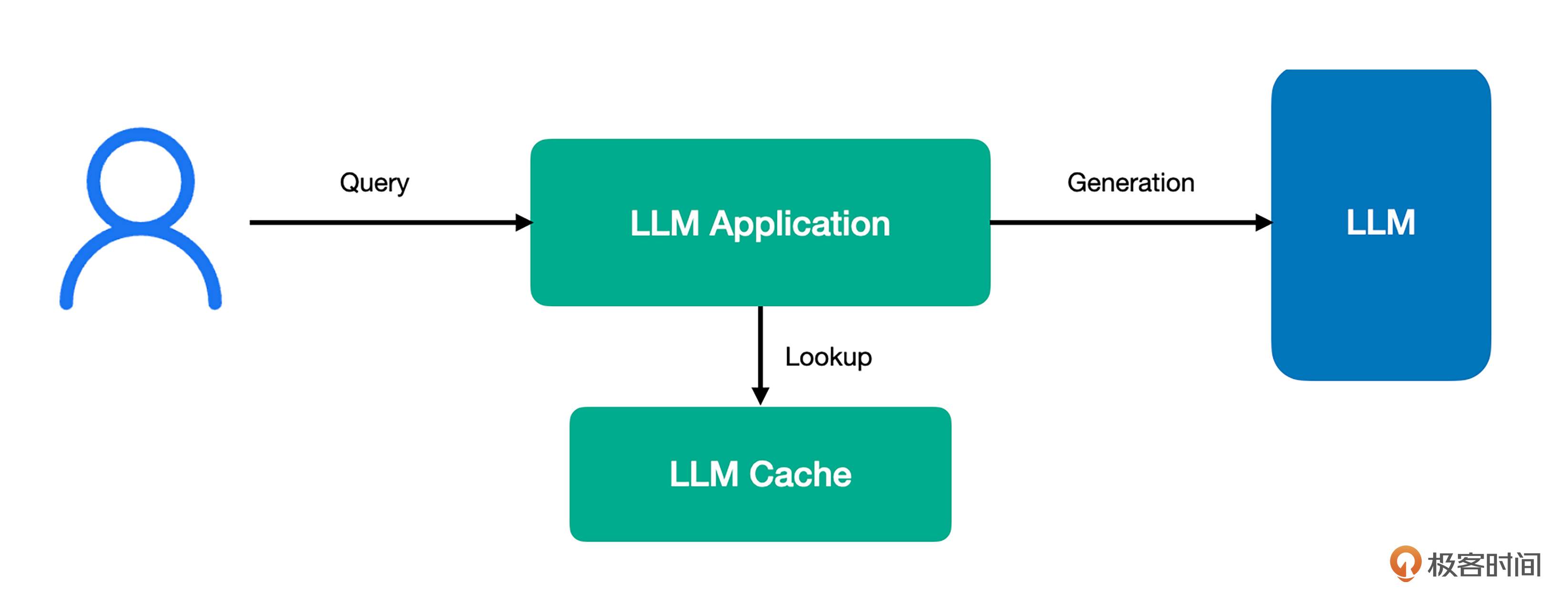
一个使用了缓存的大模型应用在接受到用户请求之后,会先到缓存中进行查询,如果命中缓存,则直接将内容返回给用户,如果没有命中,再去请求大模型生成相应的回答。
在这个架构中,关键点就是如果缓存命中,就直接将内容返回给用户,也就说明,在这种情况下无需访问大模型。我们使用大模型生成数据时,是根据请求和生成的内容计费的。
如果能够不请求大模型就给用户返回内容,我们就可以节省一次生成的费用,换言之,每次有效的缓存命中,就是在节省成本。所以,对大模型应用而言,缓存是至关重要的,一方面可以提升访问速度,另一方面,可以实实在在地节省成本。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

1. 缓存对大模型应用的重要性,可以提升访问速度,降低成本。 2. LangChain 中提供了全局和特定大模型的缓存设置,包括内存缓存和基于数据库的缓存。 3. LangChain 提供了精确缓存和语义缓存两类,对于大模型应用,语义缓存更为灵活。 4. Redis作为语义缓存的实现,通过RedisSemanticCache和Redis Vector Library支持语义匹配和向量存储。 5. 缓存可以显著提升大模型应用的性能,减少对大模型的请求次数,从而节省成本。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《程序员的 AI 开发第一课》,新⼈⾸单¥59
《程序员的 AI 开发第一课》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
精选留言
由作者筛选后的优质留言将会公开显示,欢迎踊跃留言。
收起评论