
11|自己动手实现一个RAG应用
郑晔

你好,我是郑晔!
上一讲,我们用了一讲的篇幅介绍了一下 RAG。你现在已经对 RAG 有了一个初步的了解,这一讲,我们就要动手实现一个 RAG 应用了。
我们知道 RAG 有两个核心的过程,一个是把信息存放起来的索引过程,一个是利用找到相关信息生成内容的检索生成过程。所以,我们这个 RAG 应用也要分成两个部分:索引和检索生成。
RAG 是为了让大模型知道更多的东西,所以,接下来要实现的 RAG 应用,用来增强的信息就是我们这门课程的内容,我会把开篇词做成一个文件,这样,我们就可以和大模型讨论我们的课程了。LangChain 已经提供了一些基础设施,我们可以利用这些基础设施构建我们的应用。
我们先从索引的过程开始!
索引
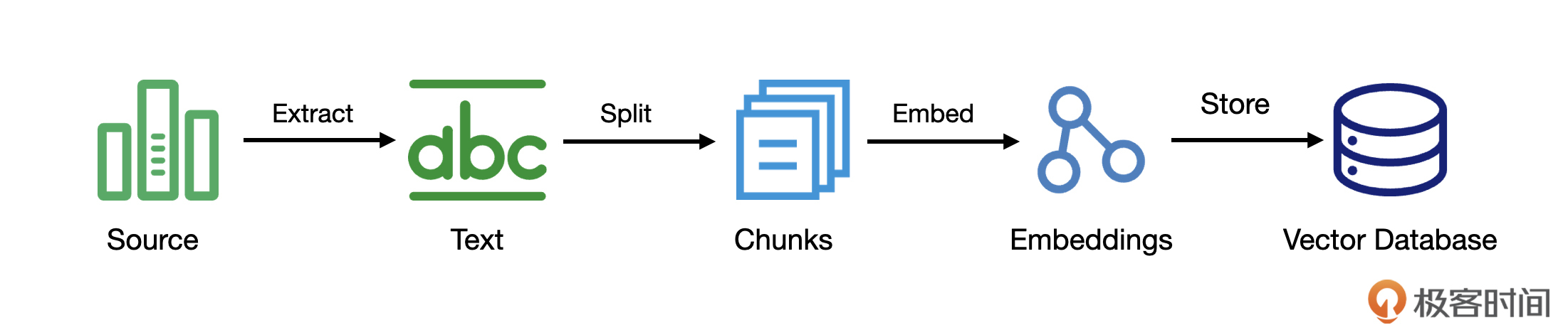
下面是实现这个索引过程的代码:
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

1. RAG应用的核心过程包括信息存放的索引过程和利用找到相关信息生成内容的检索生成过程。 2. LangChain中的文档加载器(DocumentLoader)负责加载文本信息,而文本拆分器(TextSplitter)则负责拆分加载进来的文档。 3. LangChain支持多种向量数据库,统一的接口VectorStore包含了向量数据库的统一操作,如添加、查询等。 4. 在Chroma初始化过程中,可以指定Embedding函数,负责将文本转换为向量,如OpenAI的Embeddings实现。 5. Retriever的核心能力是根据文本查询出对应的文档,它可以从不同数据源中进行搜索,如WikipediaRetriever可以从Wikipedia上进行搜索。 6. 提示词在RAG应用中起着重要作用,它指导大模型根据提供的上下文回答问题,同时保持回答简洁。 7. LangChain为RAG应用提供了基础的支持,包括文档、DocumentLoader、向量数据库、Embedding、TextSplitter和Retriever等概念。 8. 在实现RAG应用过程中,需要编写好提示词,以便更好地支持特定的业务需求。 9. 改造RAG应用可以将自己的业务资料索引到向量数据库中,从而实现个性化的信息检索和生成。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《程序员的 AI 开发第一课》,新⼈⾸单¥59
《程序员的 AI 开发第一课》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
精选留言
由作者筛选后的优质留言将会公开显示,欢迎踊跃留言。
收起评论