

浏览器:一个浏览器是如何工作的?(阶段二)
winter

该思维导图由 AI 生成,仅供参考
你好,我是 winter,今天我们继续来看浏览器的相关内容。
我在上一篇文章中,简要介绍了浏览器的工作大致可以分为 6 个阶段,我们昨天讲完了第一个阶段,也就是通讯的部分:浏览器使用 HTTP 协议或者 HTTPS 协议,向服务端请求页面的过程。
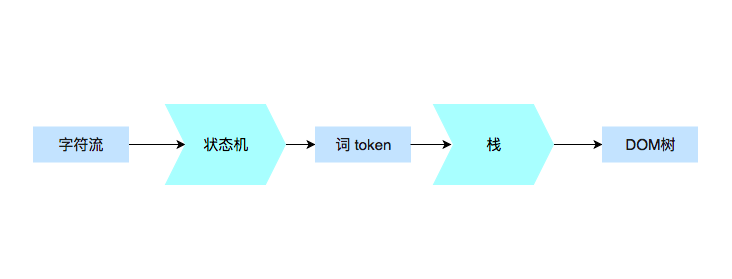
今天我们主要来看两个过程:如何解析请求回来的 HTML 代码,DOM 树又是如何构建的。
解析代码
我们在前面讲到了 HTTP 的构成,但是我们有一部分没有详细讲解,那就是 Response 的 body 部分,这正是因为 HTTP 的 Response 的 body,就要交给我们今天学习的内容去处理了。
HTML 的结构不算太复杂,我们日常开发需要的 90% 的“词”(指编译原理的术语 token,表示最小的有意义的单元),种类大约只有标签开始、属性、标签结束、注释、CDATA 节点几种。
实际上有点麻烦的是,由于 HTML 跟 SGML 的千丝万缕的联系,我们需要做不少容错处理。“<?”和“<%”什么的也是必须要支持好的,报了错也不能吭声。
1. 词(token)是如何被拆分的
首先我们来看看一个非常标准的标签,会被如何拆分:
如果我们从最小有意义单元的定义来拆分,第一个词(token)是什么呢?显然,作为一个词(token),整个 p 标签肯定是过大了(它甚至可以嵌套)。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

本文深入探讨了浏览器解析HTML代码的技术原理,重点介绍了词法分析和构建DOM树的过程。首先,通过状态机实现词法分析,将字符流解析成词(token),并给出了状态机的代码实现方式。接着,详细介绍了使用栈来构建DOM树的算法,以及通过JavaScript实现这一过程的示例代码。文章还提到了在解析HTML代码时需要处理的情况,如标签匹配和文本节点合并等。总的来说,本文以深入浅出的方式,为读者呈现了浏览器解析HTML代码的内部工作原理,对于想要深入了解浏览器工作原理的读者来说,是一篇值得阅读的文章。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《重学前端》,新⼈⾸单¥59
《重学前端》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(36)
- 最新
- 精选
 阿成参考了 github 上的一个 gist,才算写出来个能跑起来的... https://github.com/aimergenge/toy-html-parser
阿成参考了 github 上的一个 gist,才算写出来个能跑起来的... https://github.com/aimergenge/toy-html-parser作者回复: 嗯 这个超棒 推荐大家一起看看
2019-02-18102 Aaaaaaaaaaayoureturn tagOpen 是不是应该改为 return tagOpenState
Aaaaaaaaaaayoureturn tagOpen 是不是应该改为 return tagOpenState作者回复: 对,我改一下
2019-02-1313 是零壹呀这一节讲的应该是如何实现一个parser吧。 关于状态机这一块,我觉得是不是可以先讲一节正则的知识点呢。 理解了正则,那么大家对状态机的概念就有了更加直观的理解了。
是零壹呀这一节讲的应该是如何实现一个parser吧。 关于状态机这一块,我觉得是不是可以先讲一节正则的知识点呢。 理解了正则,那么大家对状态机的概念就有了更加直观的理解了。作者回复: 一般正则都是状态机实现的,讲正则对理解它底层的状态机毫无意义啊。 当然了,词法分析也可以用正则来实现,我这里没有这么做而已,我写过一个js的词法分析是用正则做的,你可以参考: https://github.com/wintercn/JSinJS/blob/master/source/LexicalParser.js
2019-02-19210 umaru老师cdata是啥?( ・◇・)
umaru老师cdata是啥?( ・◇・)作者回复: XML的相关知识,可以看一下,不怎么重要。
2019-02-2129 花儿与少年只简单讲了浏览器怎么解析html,并没有讲具体怎么构建dom树,请寒老师不要偷工减料
花儿与少年只简单讲了浏览器怎么解析html,并没有讲具体怎么构建dom树,请寒老师不要偷工减料作者回复: 怎么没讲,还有构造的算法和视频呢,不认真到这个地步了么?
2019-02-169 王飞老师,感觉在可以讲下virtual-dom
王飞老师,感觉在可以讲下virtual-dom作者回复: virtual-dom不是浏览器的东西,算是一种应用技巧吧,我觉得它寿命不会特别长。
2019-02-1924 Marphy Demon老师可否提供一些课外阅读的材料呢?单纯通过这一篇文章,没有接触相关知识的前提下,get到的东西比较少。
Marphy Demon老师可否提供一些课外阅读的材料呢?单纯通过这一篇文章,没有接触相关知识的前提下,get到的东西比较少。作者回复: 这一篇主要涉及的是编译原理,不过我讲的比书简单多了,有个感性认识就可以。
2019-02-144
 Frank老师 能回答下,或者给个资料补充一下。手机浏览器与电脑浏览器的区别吗?
Frank老师 能回答下,或者给个资料补充一下。手机浏览器与电脑浏览器的区别吗?作者回复: 工作原理上,当然没区别了,但是如果你指兼容性,那三天三夜也说不完……
2019-02-133 让时间说真话词法其实是词经过状态机解析的规则。语法是词法的实现。比如<p>hello world</p> 浏览器根据状态机中词法对词的解析的规则把html解析成词,然后用语法构建dom树。
让时间说真话词法其实是词经过状态机解析的规则。语法是词法的实现。比如<p>hello world</p> 浏览器根据状态机中词法对词的解析的规则把html解析成词,然后用语法构建dom树。作者回复: 语法不是词法的实现。 词法分析和语法分析是两个过程。
2019-02-231 云韵状态机的那幅图有点看不懂,可以详细说一下吗,或者有个推荐的资料
云韵状态机的那幅图有点看不懂,可以详细说一下吗,或者有个推荐的资料作者回复: 任何编译原理书的状态机部分。推荐龙书,就是封面有条大龙的《编译原理》
2019-02-201
收起评论