

27 | 巧妇难为无米之炊:数据采集关键要素
刑无刀

该思维导图由 AI 生成,仅供参考
推荐系统离不开数据,数据就是推荐系统的粮食,要有数据就得收集数据。在自己产品中收集数据,主要还是来自日志。
日志和数据
数据驱动这个概念也是最近几年才开始流行起来的,在古典互联网时代,设计和开发产品完全侧重于功能易用和设计精巧上,并且整体驱动力受限于产品负责人的个人眼光,这属于是一种感性的把握,也因此对积累数据这件事就不是很重视。
在我经手的产品中,就有产品上线很久,需要搭建推荐系统时,却发现并没有收集相应的数据,或者收集得非常杂乱无章。
关于数据采集,按照用途分类又有三种:
报表统计;
数据分析;
机器学习。
当然,这三种的用途并不冲突,而且反而有层层递进的关系。最基本的数据收集,是为了统计一些核心的产品指标,例如次日留存,七日留存等,一方面是为了监控产品的健康状况,另一方面是为了对外秀肌肉,这一类数据使用非常浅层,对数据的采集要求也不高。
第二种就是比较常见的数据采集需求所在了。在前面第一种用途基础上,不但需要知道产品是否健康,还需要知道为什么健康、为什么不健康,做对了什么事、做错了什么事,要从数据中去找到根本的原因。
这种数据采集的用途,驱动了很多多维分析软件应运而生,也驱动了多家大数据创业公司应运而生。
数据分析工作,最后要产出的是比较简明清晰直观的结论,这是数据分析师综合自己的智慧加工出来的,是有人产出的。
它主要用于指导产品设计、指导商业推广、指导开发方式。走到这一步的数据采集,已经是实打实的数据驱动产品了。
第三种,就是收集数据为了机器学习应用,或者更广泛地说人工智能应用。那么机器学习应用,主要在消化数据的角色是算法、是计算机,而不是人。
这个观点是我在专栏写作之初,讲解用户画像相关内容时就提到的,再强调一遍就是,所有的数据,不论原始数据还是加工后的数据都是给机器“看”的,而不是给人“看”的。
所以在数据采集上,可以说多多益善,样本是多多益善,数据采集的维度,也就是字段数多多益善,但另一方面,数据是否适合分析,数据是否易于可视化地操作并不是核心的内容。
当然,实际上在任何一款需要有推荐系统的产品中,数据采集的需求很可能要同时满足上述三种要求。
本文为了讨论方便,不会重点讨论多维数据分析的用途,而是专门看看为了满足推荐系统,你需要怎么收集日志、采集数据。
因为推荐系统就是一个典型的人工智能应用,数据是要喂给机器“吃”的。
下面我就开始给你详细剖析一下为推荐系统收集日志这件事。
数据采集
给推荐系统收集日志这件事,依次要讨论的是:日志的数据模型,收集哪些日志,用什么工具收集,收集的日志怎么存储。
1. 数据模型
数据模型是什么?所谓数据模型,其实就是把数据归类。产品越复杂,业务线越多,产生的日志就越复杂。
如果看山是山,一个数据来源一个数据来源地去对待的话,那将效率非常低下,因此需要首先把要收集的日志数据归入几个模型。不同的数据应用,数据模型略有不同。
就推荐系统而言,推荐系统要做的事情就是预测那些最终会建立的人和物之间的连接,依赖的是已有的连接,以及人和物的属性,而且,其中最主要的是已有的连接,人和物的属性只不过是更加详细描述这些连接而已。
数据模型帮助梳理日志、归类存储,以方便在使用时获取。你可以回顾一下在前面讲过的推荐算法,这些推荐算法形形色色,但是他们所需要的数据可以概括为两个字:矩阵。
再细分一下,这些矩阵就分成了四种。
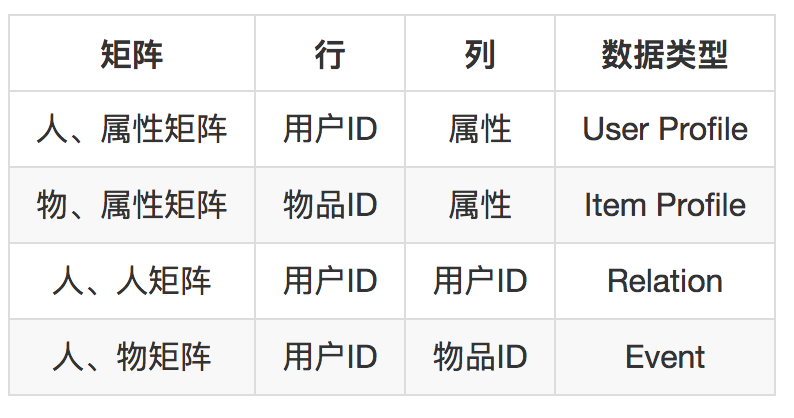
基于这个分析,可以给要收集的数据归纳成下面几种。
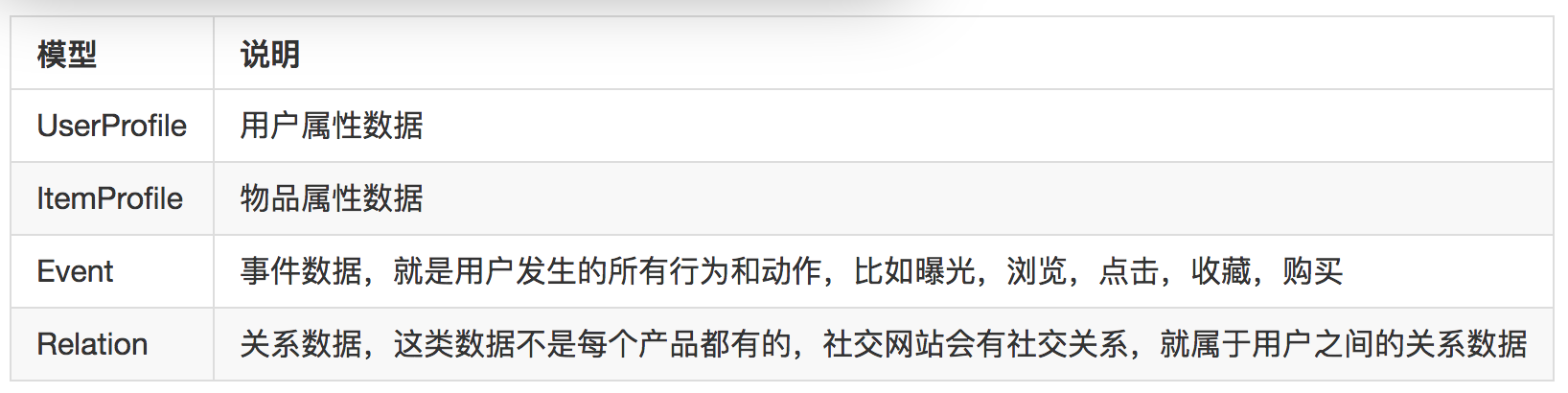
有了数据模型,就可以很好地去梳理现有的日志,看看每一种日志属于哪一种。并且,在一个新产品上线之初,该如何为将来的推荐系统记录日志也比较清楚了。这个数据模型当然不能概括全部数据,但是用来构建一个推荐系统就绰绰有余了。
接下来就是去收集数据了。收集数据,就是把散布在各个地方的数据聚拢,也包括那些还根本没有记录的数据的地方要开始记录。
2. 数据在哪?
按照前面的数据建模,我们一起来看一下要收集的数据会怎么产生。主要来自两种,一种是业务运转必须要存储的记录,例如用户注册资料,如果不在数据库中记录,产品就无法正常运转。
另一种就是在用户使用产品时顺便记录下来的,这叫做埋点。第一种数据源来自业务数据库,通常都是结构化存储,MySQL。第二种数据需要埋点,埋点又有几种不同方法。
第一种,SDK 埋点。这个是最经典古老的埋点方法,就是在开发自己的 App 或者网站时,嵌入第三方统计的 SDK,App 如友盟等,网站如 Google Analytics 等。
SDK 在要收集的数据发生点被调用,将数据发送到第三方统计,第三方统计得到数据后再进一步分析展示。
这种数据收集方式对推荐系统的意义不大,因为得不到原始的数据而只是得到统计结果,我们可以将其做一些改动,或者自己仿造做一些开发内部数据采集 SDK,从而能够收集到鲜活的数据。
第二种,可视化埋点。可视化埋点在 SDK 埋点基础上做了进一步工作,埋点工作通过可视化配置的方式完成,一般是在 App 端或者网站端嵌入可视化埋点套件的 SDK,然后再管理端接收前端传回的应用控件树,通过点选和配置,指令前端收集那些事件数据。业界有开源方案实现可参考,如 Mixpanel。
第三种,无埋点。所谓无埋点不是不埋点收集数据,而是尽可能多自动收集所有数据,但是使用方按照自己的需求去使用部分数据。
SDK 埋点就是复杂度高,一旦埋点有错,需要更新客户端版本,可视化埋点的不足就是:收集数据不能收集到非界面数据,例如收集了点击事件,也仅仅能收集一个点击事件,却不能把更详细的数据一并返回。
上面是按照技术手段分,如果按照收集数据的位置分,又分为前端埋点和后端埋点。
这两个区别是这样的,举个例子,要收集用户的点击事件,前端埋点就是在用户点击时,除了响应他的点击请求,还同时发送一条数据给数据采集方。
后端埋点就不一样了,由于用户的点击需要和后端交互,后端收到这个点击请求时就会在服务端打印一条业务日志,所以数据采集就采集这条业务日志即可。
埋点是一项非常复杂繁琐的事情,需要前端工程师或者客户端工程师细心处理,不在本文讨论范围内。但是幸好,国内如神策数据等公司,将这些工作已经做得很傻瓜化了,大大减轻了埋点数据采集的困扰。
对于推荐系统来说,所需要的数据基本上都可以从后端收集,采集成本较低,但是有两个要求:要求所有的事件都需要和后端交互,要求所有业务响应都要有日志记录。这样才能做到在后端收集日志。
后端收集业务日志好处很多,比如下面几种。
实时性。由于业务响应是实时的,所以日志打印也是实时的,因此可以做到实时收集。
可及时更新。由于日志记录都发生在后端,所以需要更新时可以及时更新,而不用重新发布客户端版本。
开发简单。不需要单独维护一套 SDK。
归纳一下,Event 类别的数据从后端各个业务服务器产生的日志来,Item 和 User 类型数据,从业务数据库来,还有一类特殊的数据就是 Relation 类别,也从业务数据库来。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

本文深入探讨了推荐系统中数据采集的关键要素,强调了数据驱动的重要性。首先,文章指出数据在推荐系统中的重要性,将数据比喻为推荐系统的“粮食”,强调了数据驱动的重要性。其次,文章详细介绍了数据采集的三种用途:报表统计、数据分析和机器学习,并强调了数据模型的重要性。在数据模型方面,文章提到了推荐系统所需的数据模型,以及数据的来源和收集方式。作者详细讨论了数据模型的分类和收集的数据来源,包括业务数据库和埋点。在埋点方面,文章介绍了SDK埋点、可视化埋点和无埋点的方式,并强调了后端收集业务日志的优势。此外,文章还介绍了数据采集的架构图和埋点技术的简要介绍,以及对数据质量的监控和检验。总的来说,本文通过讨论数据模型、数据来源和收集方式,为读者提供了推荐系统数据采集的关键要素,强调了数据驱动的重要性,为推荐系统的数据收集提供了指导和建议。文章内容丰富,涵盖了数据采集的方方面面,对于推荐系统的数据采集具有重要的参考价值。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《推荐系统三十六式》,新⼈⾸单¥59
《推荐系统三十六式》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(15)
- 最新
- 精选
 🐱您的好友William🐱真的是越到后面人越少了
🐱您的好友William🐱真的是越到后面人越少了作者回复: 是啊,我也很无奈。或许是害怕学会了要在公司承担更多的事情?
2018-10-1657- 聂文峰-峰哥可以说这门课买的非常值,非常全面
作者回复: 请多多传播。
2018-11-222 
 李不知道老师还关注问题不,我想知道为什么第一类日志用llogstash,第二类用flume,统一用一个不好吗
李不知道老师还关注问题不,我想知道为什么第一类日志用llogstash,第二类用flume,统一用一个不好吗作者回复: 其实统一用也可以。logstash一般都系统自带。
2019-05-171 nigel马上要开发一个连锁门店购物系统的数据埋点部分,感觉既简单又复杂。文章有点收获,可惜了,推荐算法不是我写。
nigel马上要开发一个连锁门店购物系统的数据埋点部分,感觉既简单又复杂。文章有点收获,可惜了,推荐算法不是我写。作者回复: 你可以的!
2018-05-041 J.T留个言表明自己还在看
J.T留个言表明自己还在看作者回复: 可以的。
2019-02-06 艾志敏如何建设用户属性和物品属性,这个数据库如何建模设计?
艾志敏如何建设用户属性和物品属性,这个数据库如何建模设计?作者回复: 属性是业务数据,在推荐系统中一般不考虑。而根据业务数据加工出来的特征数据可以用redis或者hbase。
2018-12-13- 天歌112没想到一年多之后还有人😃😃😃2019-08-2734
- Geek_84a4f921年来看2021-05-131
 嘉文信息流里需要采集 item 的曝光、点击、收藏、消费等关系行为,主要是文中描述的 Event 类型数据2018-05-041
嘉文信息流里需要采集 item 的曝光、点击、收藏、消费等关系行为,主要是文中描述的 Event 类型数据2018-05-041- 嘉文曝光数据怎么从后端收集呢?还有一些交互行为也不好在后端收集,比如:图片 zoom in2018-05-041
收起评论

