

15 | 深度和宽度兼具的融合模型 Wide and Deep
刑无刀

该思维导图由 AI 生成,仅供参考
我在前面已经提到过一个事实,就是推荐系统的框架大都是多种召回策略外挂一个融合排序。召回策略的姿势繁多,前面的专栏文章已经涉及了一部分内容。今天我们继续说融合排序。
要深还是要宽
融合排序,最常见的就是 CTR 预估,你一定不要把自己真的只局限在 C 上,这里说的 CTR 预估的 C,可以是产品中的任何行为,视频是不是会看完,看完后是不是会收藏,是不是会分享到第三方平台,查看的商品是不是会购买等等,都可以看成那个可以被预估发生概率的 CTR。
CTR 预估的常见做法就是广义线性模型,如 Logistic Regression,然后再采用特征海洋战术,就是把几乎所有的精力都放在搞特征上:挖掘新特征、挖掘特征组合、寻找新的特征离散方法等等。
这种简单模型加特征工程的做法好处多多:
线性模型简单,其训练和预测计算复杂度都相对低;
工程师的精力可以集中在发掘新的有效特征上,俗称特征工程;
工程师们可以并行化工作,各自挖掘特征;
线性模型的可解释性相对非线性模型要好。
特征海洋战术让线性模型表现为一个很宽广(Wide)的模型,可以想象逻辑回归中那个特征向量在特征工程的加持下,越来越宽的样子。
最近十年,是深度学习独步天下的十年,犹如异军突起,一路摧城拔寨,战火自然也烧到了推荐系统领域,用深度神经网络来革“线性模型 + 特征工程”的命,也再自然不过。
用这种“深模型”升级以前的“宽模型”,尤其是深度学习“端到端”的诱惑,可以让每天沉迷搞特征无法自拔的工程师们主动投怀送抱。
深度学习在推荐领域的应用,其最大好处就是“洞悉本质般的精深”,优秀的泛化性能,可以给推荐很多惊喜。
硬币总有正反面,深度模型的泛化强于线性模型,也会导致推荐有时候看上去像是“找不着北”,就是大家常常自问的那句话:“不知道这是怎么推出来的?”用行话说,就是可解释性不好。
以前全面搞特征时,你叫人家“宽模型”小甜甜,现在新模型换旧模型,“深模型”一出,就叫“宽模型”牛夫人,这样不好,还是要两者合作,才能最大限度地发挥效果。
因此,Google 在 2016 年就发表了他们在 Google Play 应用商店上实践检验过的 CTR 预估方法:Wide & Deep 模型,让两者一起为用户们服务,这样就取得了良好效果。
下面,我就为你详细介绍一下这个深宽模型。
Wide & Deep 模型
一个典型的推荐系统架构,其实很类似一个搜索引擎,搜索由检索和排序构成。推荐系统也有召回和排序两部构成,不过,推荐系统的检索过程并不一定有显式的检索语句,通常是拿着用户特征和场景特征去检索召回,其中用户特征也就是在前面的专栏中提到的用户画像。
示意图如下.
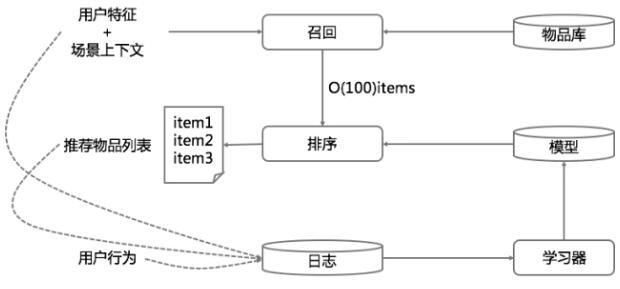
简单描述一下这个示意图。
首先使用用户特征和上下文场景特征从物品库中召回候选推荐结果,比如得到 100 个物品,然后用融合模型对这 100 个物品做最终排序,输出给用户展示。
同时开始记录展示日志和用户行为日志,再把收集到的日志和用户特征、上下文场景特征、物品特征拉平成为模型的训练数据,训练新的模型,再用于后面的推荐,如此周而复始。
今天要说的深宽模型就是专门用于融合排序的,分成两部分来看。一部分是线性模型,一部分是深度非线性模型。整个示意图如下:
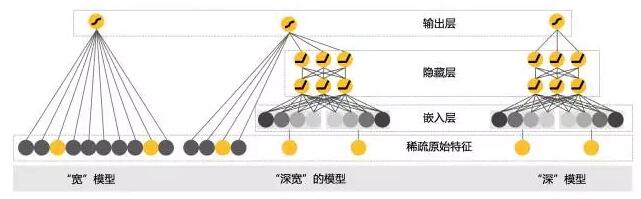
我来解释一下这个示意图,这个示意图有三部分。最左边是宽模型,中间是深宽模型,最右边是纯的深度模型。
首先,线性模型部分,也就是“宽模型”,形式如下:
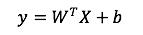
再次强调一下,这是线性模型的标准形式,逻辑回归只是在这基础上用 sigmoid 函数变换了一下。
模型中的 X 是特征,W 是权重,b 是模型的偏置,也是线性模型的截距。线性模型中常用的特征构造手段就是特征交叉。
例如:“性别 = 女 and 语言 = 英语。”就是由两个特征组合交叉而成,只有当“性别 = 女”取值为 1,并且“语言 = 英语”也取值为 1 时,这个交叉特征才会取值为 1。线性模型的输出这里采用的 Logistic Regression。
好,现在把头转到右边,看看深度模型。深度模型其实就是一个前馈神经网络。
深度模型对原始的高维稀疏类别型特征,先进行嵌入学习,转换为稠密、低维的实值型向量,转换后的向量维度通常在 10-100 这个范围。
这里的嵌入学习,就是先随机初始化嵌入向量,再直接扔到整个前馈网络中,用目标函数来优化学习。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

Wide & Deep模型是一种融合了传统CTR预估方法和深度学习技术的推荐系统模型。该模型结合了线性模型和深度神经网络,通过特征交叉和嵌入学习实现对高维稀疏类别型特征的处理,同时提供了非线性转换,使模型具有更强的泛化能力和推荐效果。这种工程创新适合高维稀疏特征的推荐场景,将传统的“宽模型”和新的“深模型”结合,展现出了较好的应用前景。该模型已经开源在TensorFlow中,大大减小了落地成本,为读者提供了深入了解和应用该模型的基础知识。在GooglePlay的App推荐服务中的应用情况表现良好,用户安装表现良好,线上效果相对于对照组有3.9%的提升。然而,线下的AUC值提高并不明显,这也引发了对AUC值是否是最佳的线下评估方式的讨论。整体而言,Wide & Deep模型是一个既博学又精深的模型,为推荐系统领域带来了新的思路和应用前景。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《推荐系统三十六式》,新⼈⾸单¥59
《推荐系统三十六式》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(12)
- 最新
- 精选
- 王王王越来越难了,很多技术概念需要慢慢消化
作者回复: 坚持住,我们能赢!
2018-04-061  曾阿牛AUC值衡量的是整体排序,但对前N1个物品排越前对用户影响越大,跟AUC值是有一定出入
曾阿牛AUC值衡量的是整体排序,但对前N1个物品排越前对用户影响越大,跟AUC值是有一定出入作者回复: 最终的商业目标受很多因素影响,排序好坏只是其中一方面,影响用户最终消费的因素都应该纳入考虑。
2018-04-061 江枫老师好,特征embedding也是和模型训练过程一起进行的吗?如果提前做好embedding,比如用word2vec,效果如何?另外,对于新物品,新特征,可能没有embedding结果,怎么处理?谢谢。2018-04-069
江枫老师好,特征embedding也是和模型训练过程一起进行的吗?如果提前做好embedding,比如用word2vec,效果如何?另外,对于新物品,新特征,可能没有embedding结果,怎么处理?谢谢。2018-04-069 林彦AUC 的不足之处有:(1)反映的是模型的整体性能,看不出在不同点击率区间上的误差情况。有可能线上实际用户点击多的那部分物品误差低,点击少的那部分物品误差高。与线下对所有物品的整体误差评估有差异;(2)只反映了排序能力,沒有提现精确度。比如,训练出的模型的点击率对所有物品同时乘以一个常数,AUC值不会改变,而模型对于点击率的预测值和真实值的差距肯定有变化。我的理解就是新的模型可能对于排名高,排名低,点击率高,点击率低等的某一类物品的点击率提升较大,但对排名本身的顺序影响不大。 不足之处是参考了网上一篇不错的综述文章得到的,非原创。2018-04-066
林彦AUC 的不足之处有:(1)反映的是模型的整体性能,看不出在不同点击率区间上的误差情况。有可能线上实际用户点击多的那部分物品误差低,点击少的那部分物品误差高。与线下对所有物品的整体误差评估有差异;(2)只反映了排序能力,沒有提现精确度。比如,训练出的模型的点击率对所有物品同时乘以一个常数,AUC值不会改变,而模型对于点击率的预测值和真实值的差距肯定有变化。我的理解就是新的模型可能对于排名高,排名低,点击率高,点击率低等的某一类物品的点击率提升较大,但对排名本身的顺序影响不大。 不足之处是参考了网上一篇不错的综述文章得到的,非原创。2018-04-066- @lala0124老师,您好,这个wide&deep模型我之前有了解过,tensorflow的实现版本也很简洁,我想问一下deep模型中的embedding向量是否只能来自分类特征2018-04-113
- shangqiu86我补充下@江枫的问题,老师,有时候embedding的参数需要随着整个模型一起调优,有时候又说要先进行embedding,即embedding的参数不随着整个模型一起调优,什么场景下要一起,什么场景下不一起呢?2019-04-301
- shangqiu86用过wide&deep模型,效果 并不太理想,是在资讯推荐中,把资讯内容先做了word2vec,再加上一些其他特征,准确率就比随机高一点点,老师,不知道这种还怎么调优2019-04-30
- Dan老師您好,想請教您,在paper表示,深模型的optimizer 用adagrad,寬模型用FTRL。在joint training的階段是使用前面兩個學習完的權重做為initial,使用mini batch 的sgd做joint train嗎?還是說是分開使用不同的optimizer ,只是使用相同的 logistic loss?2018-04-22
- Dan老師您好,請教您,在深模型的embedding 層的dense vector長度通常是如何setting 或者 tuning ?作者設32 - 1200 - 1024 - 512 - 256,有什麼涵意嗎?感謝您2018-04-22
 半瓶墨水昨天刚搞明白这篇论文,就是TensorFlow的函数名称太复杂了2018-04-13
半瓶墨水昨天刚搞明白这篇论文,就是TensorFlow的函数名称太复杂了2018-04-13
收起评论

