

02 | 个性化推荐系统有哪些绕不开的经典问题?

该思维导图由 AI 生成,仅供参考
推荐系统的问题模式
评分预测
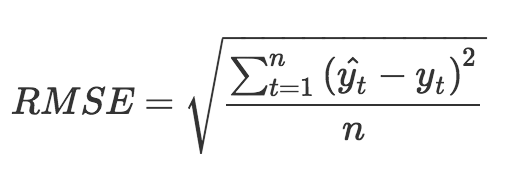
行为预测
几个常见顽疾
1 冷启动问题
2 探索与利用问题
3 安全问题
总结

 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

推荐系统是互联网产品中不可或缺的一部分,本文深入探讨了推荐系统中的两大问题模式:评分预测和行为预测。评分预测关注用户对物品的评分,而行为预测则关注用户的隐式反馈行为。这两种问题模式分别解决了推荐系统中的不同挑战,为用户和物品建立连接提供了重要参考。 此外,文章还探讨了推荐系统中的几个常见顽疾,包括冷启动问题、探索与利用问题以及安全问题。这些问题在推荐系统中尚未有通用解决方案,需要针对实际情况进行具体分析和解决。 总的来说,本文从模型角度和常见问题角度全面介绍了推荐系统的技术特点,为读者提供了对推荐系统发展现状的全面了解。对于从事推荐系统相关工作的技术人员和研究人员具有重要参考价值。
《推荐系统三十六式》,新⼈⾸单¥59

全部留言(47)
- 最新
- 精选
 上个纪元的赵天师置顶不做笔记都对不起文稿,赞
上个纪元的赵天师置顶不做笔记都对不起文稿,赞作者回复: 不回答都对不起这留言,棒
2018-03-0971- 愚公移山老师,还是有些不理解隐式反馈常常和模型的目标函数关联更密切,显示反馈,如评分,通常也与模型的目标函数关联十分密切。
作者回复: 隐式反馈往往是用户的行为,是用户正常的消费路径,最终通向商业目标,比如掏钱。但评分是个旁支,往往不必通向最终商业目标。
2018-03-1017  Antenna推荐系统里面是不是有一个“召回”阶段?这个阶段在做什么事,能否用例子说明?另外,这个召回跟评估指标的“召回率”有联系么?
Antenna推荐系统里面是不是有一个“召回”阶段?这个阶段在做什么事,能否用例子说明?另外,这个召回跟评估指标的“召回率”有联系么?作者回复: 一般一个推荐系统会同时使用多种推荐算法,每种算法都会得到一批推荐结果,然后再把这些结果统一重新排序输出。前面这个阶段就是召回阶段,后面这就是重排序阶段,或者叫融合阶段。这个召回和召回率没有联系,或者没有直接联系。召回率是分类器评价指标,样本中一共有100个正样本,你的分类器预测了90个正样本,其中分对的是80个,召回率就是80%。
2018-03-2612 海鸟“另外,你们人为给行为赋予权重这个做法不太合适,不如直接预测行为。” 人为给不同类别行为不同权重,感觉是根据现实业务场景来的,比如购买一个商品比浏览一个商品更重,为什么不合适,老师能细说下吗?
海鸟“另外,你们人为给行为赋予权重这个做法不太合适,不如直接预测行为。” 人为给不同类别行为不同权重,感觉是根据现实业务场景来的,比如购买一个商品比浏览一个商品更重,为什么不合适,老师能细说下吗?作者回复: 是的,有的行为处于漏斗转化的下层,的确更重要,但重要多少呢?假如你给点击权重为1,加入购物车是比点击更重要,那为什么就要是2呢,不能是3呢?因为人为量化极大可能不客观不准确,然后被当成了计算过程中重要的变量使用,甚至成为要去不断逼近的目标,这就是缘木求鱼。
2018-03-1210 叶晓锋老师你好,非常感谢您对评分预测和行为预测的划分,而且因为用户爸爸很忙,对很多场景来说不可能采集到足够的评分反馈,我们应该更多的关注行为预测,隐式反馈,解决80%的问题。老师讲到行为预测分为概率预测和相对排序预测,我特别关注相对排序预测,老师能否解答下概率预测和相对排序预测的区别?
叶晓锋老师你好,非常感谢您对评分预测和行为预测的划分,而且因为用户爸爸很忙,对很多场景来说不可能采集到足够的评分反馈,我们应该更多的关注行为预测,隐式反馈,解决80%的问题。老师讲到行为预测分为概率预测和相对排序预测,我特别关注相对排序预测,老师能否解答下概率预测和相对排序预测的区别?作者回复: 不要急,后面会专门讲到。
2018-03-077 吴文敏对于存在多种隐反馈行为的推荐系统,比如电商这一场景(同时有点击、浏览、收藏、加入购物车),该如何设计推荐策略。我们过去的做法是将这些行为作为不同维度的量化特征对来预测将来某一种行为会不会发生。老师有没有好的建议?
吴文敏对于存在多种隐反馈行为的推荐系统,比如电商这一场景(同时有点击、浏览、收藏、加入购物车),该如何设计推荐策略。我们过去的做法是将这些行为作为不同维度的量化特征对来预测将来某一种行为会不会发生。老师有没有好的建议?作者回复: 可以这样做,但是可能有过拟合的危险,因为多种行为可能不见得是时序先后发生的。还有一种做法是分别对每种行为建模预测,在不同场景使用不同侧重的模型。
2018-03-265 禾子先生刑老师,之前用mahout,采用皮尔逊算法,进行基于用户和物品的推荐,推荐效果不好,碰到一个非常严重的问题,希望老师能够指点下。我们是电商系统,给用户的行为进行评分并采集,如给点击商品行为评1分,添加购物车评2分,购买评3分,用户数据在20w左右,评分数据在150w左右,结果每次推荐巨慢,经常要1分钟才有推荐结果,而且还经常导致内存溢出,希望老师能指点下。
禾子先生刑老师,之前用mahout,采用皮尔逊算法,进行基于用户和物品的推荐,推荐效果不好,碰到一个非常严重的问题,希望老师能够指点下。我们是电商系统,给用户的行为进行评分并采集,如给点击商品行为评1分,添加购物车评2分,购买评3分,用户数据在20w左右,评分数据在150w左右,结果每次推荐巨慢,经常要1分钟才有推荐结果,而且还经常导致内存溢出,希望老师能指点下。作者回复: 内存溢出这个我恐怕不能直接知道原因。另外,你们人为给行为赋予权重这个做法不太合适,不如直接预测行为。
2018-03-075 Edward数据稀疏度1.2%是什么意思
Edward数据稀疏度1.2%是什么意思作者回复: 矩阵中只有1.2%的位置有数据。
2018-03-164 听风是不是还有个滞后性问题,怎么解决
听风是不是还有个滞后性问题,怎么解决作者回复: 推荐系统滞后是局限性,因为总是要在历史数据中有记录了才能反应出来。艾莎门就是这样的局限性导致的。
2018-03-134 山羊wayne均方根讲的确实形象,赞一个
山羊wayne均方根讲的确实形象,赞一个作者回复: 收下了。
2018-03-124

