

25 | Netflix个性化推荐架构
刑无刀

该思维导图由 AI 生成,仅供参考
你是否常常被乱花渐欲迷人眼的推荐算法绕得如坠云中,觉得好像算法就是推荐系统的全部,哪怕就算不是全部,也肯定至少是个嫡生的长子。
然而,实际上工程实现才是推荐系统的骨架,如果没有很好的软件实现,算法不能落地产生效果,产品不能顺畅地服务用户,不能顺利地收集到用户的反馈,更不能让推荐系统往更好的方向进化。
一个好的推荐系统不仅仅是在线下模型评测指标多么好,也不仅仅是在某个时刻像是灵光乍现一样击中了用户某个口味,而是随着用户的不断使用,产品和用户一起变好,产品背后的人得到进步,用户也越来越喜欢产品。
虽然影响是否用户产品的因素有很多很多,但是能否流畅地给用户提供服务是一个最基本的标准。
架构的重要性
推荐系统向来是一个锦上添花的东西,因此传统的观点是推荐系统更加注重线下的模型效果,而非线上的服务质量。但是你也知道,时至今日,推荐系统不再只是锦上添花,而是承担了产品的核心功能。因此,对推荐系统架构的要求也高了很多。
一个好的推荐系统架构应该具有这些特质:
实时响应请求;
及时、准确、全面记录用户反馈;
可以优雅降级;
快速实验多种策略。
上一篇专栏文章介绍的是当下最热门的推荐系统产品形式——信息流的架构,信息流并不是传统意义上的推荐系统,今天我要介绍一种更符合经典推荐系统的架构,这就是著名的流媒体 Netflix 的推荐系统架构。
通过这篇文章,我会为你介绍,实现一个简化版的推荐系统架构应该至少包含哪些元素,同时,我会带你一起总结出,一个经典推荐系统架构应该有的样子。
经典架构
好了,废话少说,我先上图。下面这张图就是 Netflix 的推荐系统架构图。
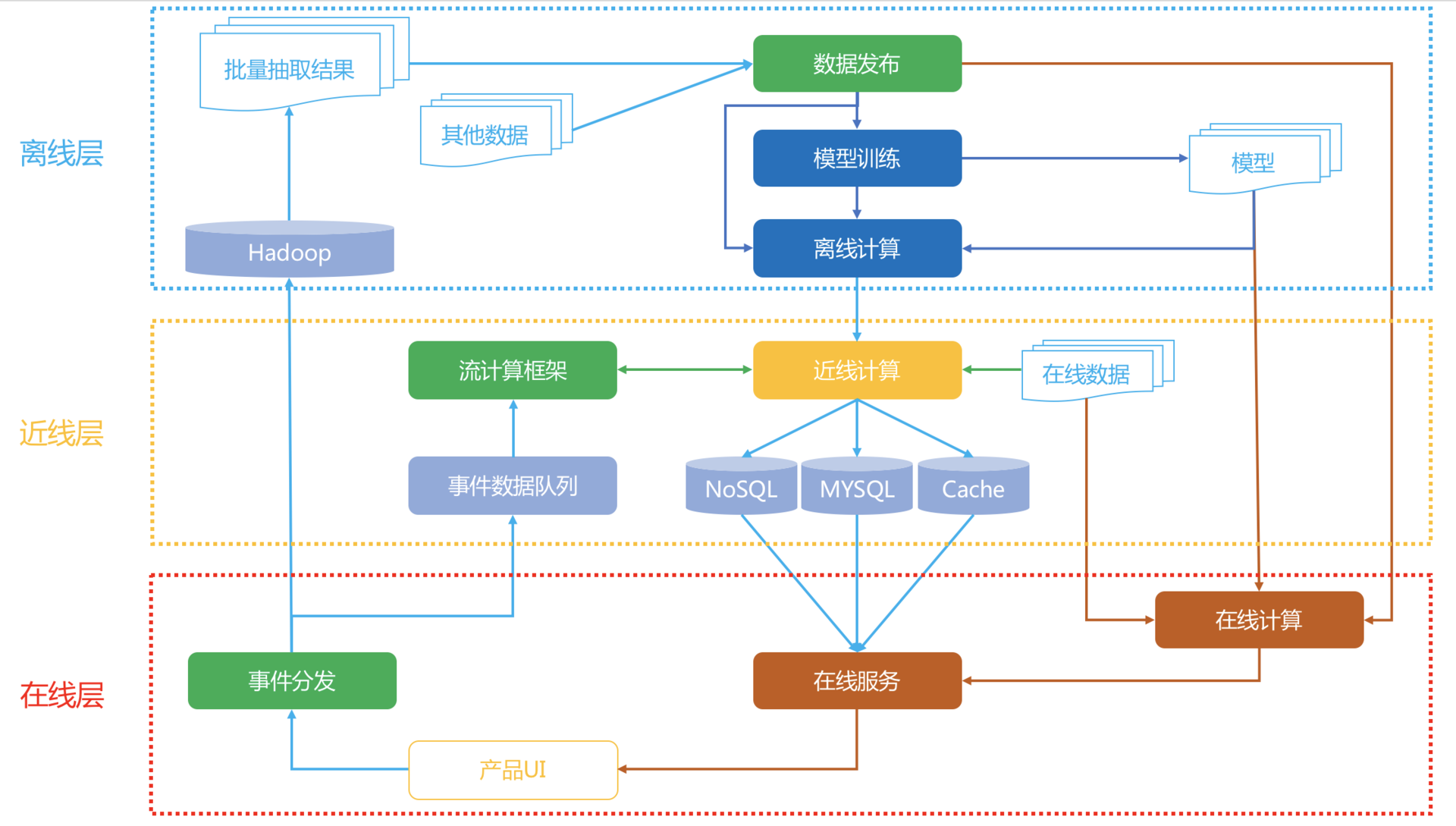
我先整体看一下这个架构,一共分成三层:在线、近线、离线。
你是不是也发现似乎有一个不太熟识的词出现:近线。对,这个近线是通常不太提的一个概念,或者通常就把它归入了在线的范畴。
实际上,可以这样定义这三个层级:
离线:不用实时数据,不提供实时服务;
近线:使用实时数据,不保证实时服务;
在线:使用实时数据,要保证实时服务。
在具体介绍这些内容之前,我先来说说数据流的情况。
1. 数据流
用户在产品 UI 上使用产品,消费展示的内容,产生行为事件数据,实时地被收集走,一边进入分布式的文件系统中存储,供离线阶段使用,另一边流向近线层的消息队列,供近线阶段的流计算使用。
离线存储的全量数据被抽取出来,组成离线计算所需的训练数据,这些训练数据被一个管理数据生成和发布的组件统一管理,要使用数据的下游,比如模型训练会在离线数据生成时得到这个组件的通知,从而开始训练,训练得到的模型用于进一步为用户计算推荐结果。
离线阶段的推荐结果或者模型在近线阶段被更新,进一步在在线阶段被直接使用,产生最终的推荐结果,呈现给用户。
这是整个数据流情况。下面我一一详细介绍每个部分。
2. 在线层
在线层的触发时机是当用户发出请求,也就是用户进入一个推荐场景,推荐位等着展示推荐结果时,这个时候需要承担责任就是在线层。在线层就是实时响应用户请求。简单说,在线层的特点就是“使用实时数据,要保证实时服务”。
在线层的优势有:
直接首次接触到大多数最新数据;
对用户请求时的上下文了如指掌;
只需计算必须的信息,不需要考虑所有的信息。
在线层也有严格的制约:
严格的服务响应时间,不能超时,或者让用户等太久;
服务要保证可用性,稳定性;
传输的数据有限。
在线层常常展现出的形式就是 Rest API 形式,后端则通常是 RPC 服务内部互相调用,以用户 ID、场景信息去请求,通常就在 ms 响应时间内返回 Json 形式的推荐结果。那么哪些计算逻辑适合放在在线层呢?
简单的算法逻辑;
模型的预测阶段;
商业目标相关的过滤或者调权逻辑;
场景有关的一些逻辑;
互动性强的一些算法。
在线阶段要处理的对象一般是已经预处理后的推荐结果,是少量物品集合。
比如说当用户访问一个物品详情页,需要做相关推荐,那么在线阶段给在线服务的 Rest API 传入用户身份以及当前的物品 ID,实时地取出物品 ID 对应的相关物品 ID,再根据用户信息对这些物品 ID 做一些重排和过滤,就可以输出了,整个过程都是在 ms 级别完成。
这个实时响应的过程中,如果发生意外,比如说这个物品 ID 就没有相关的物品,那么这时候服务就需要降级,所谓的降级就是不能达到最好的效果了,但是不能低于最低要求,这里的最低要求就是必须要返回东西,不能开天窗。
于是,这就降级为取出热门排行榜返回。虽然不是个性化的相关结果,但是总比开天窗要好。这就是服务的可用性。
在线阶段还要实时地分发用户事件数据,就是当用户不断使用产品过程产生的行为数据,需要实时地上报给有关模块。这一部分也是需要实时的,比如用于防重复推荐的过滤。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

Netflix个性化推荐架构的关键特点在于其三层架构,包括离线、近线和在线层。离线层主要面向Hadoop,通过Pig或Hive等工具从全量日志中抽取数据,进行模型训练和推荐结果计算;近线层则结合了离线层和在线层的优势,使用实时数据但不保证实时服务,处理实时数据流并将结果存入在线数据库,以便在用户发起请求时提供服务;在线层则实时响应用户请求,处理简单算法逻辑和模型的预测阶段。这一架构兼顾实时服务和大数据量处理,适用于推荐系统的高效运行。对于新产品搭建推荐系统时,可以简化Netflix架构,舍弃近线层并避免使用分布式系统。总体而言,Netflix个性化推荐架构为推荐系统架构提供了有益的参考和借鉴,尤其是在处理实时数据流和提供实时服务方面具有重要意义。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《推荐系统三十六式》,新⼈⾸单¥59
《推荐系统三十六式》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(13)
- 最新
- 精选
- kee2“如果性能不足,请升级单机配置。根据经验,一个几千万用户,几十...” 请问你说的几千万用户这种场景单机配置大概是怎样的,谢谢
作者回复: 请看最后一篇。关于团队。那里有回答。
2018-09-012  Better Life老师,实时I2I有干货可以分享一下吗?git上面有demo可以学习的吗
Better Life老师,实时I2I有干货可以分享一下吗?git上面有demo可以学习的吗作者回复: Itembased的代码见我的github。
2018-12-23- shangqiu86bandit算法主要解决EE问题和冷启动问题,我觉得应该放到在线层,作为融合排序的一部分2019-05-062
 林彦Bandit算法需要根据场景反馈调试模型的参数值,适合还没有任何模型效果数据的冷启动。当候选臂的数量不大时,可以直接应用到在线计算中。也可以作为其他离线模型推荐结果的在线优化模型使用。2018-05-012
林彦Bandit算法需要根据场景反馈调试模型的参数值,适合还没有任何模型效果数据的冷启动。当候选臂的数量不大时,可以直接应用到在线计算中。也可以作为其他离线模型推荐结果的在线优化模型使用。2018-05-012- 明华老师您好,想问如果我在离线训练阶段使用了逻辑回归训练出了模型,在在线预测时对单个用户调用api预测,但如果是单个用户怎么做例如归一化之类的数据预处理操作呢?2018-07-241
 梦露结合上下文和协同过滤能降低臂个数的Bandit可以用于在线部分,纯Bandit适合在离线部分,保证长尾物品的曝光2018-06-061
梦露结合上下文和协同过滤能降低臂个数的Bandit可以用于在线部分,纯Bandit适合在离线部分,保证长尾物品的曝光2018-06-061 尹士果性能不足,请升级单机配置。根据经验,一个几千万用户,几十万到百万的物品的协同过滤或者矩阵分解,如果充分发挥单机的性能,综合效率会远远优于在 Spark 上运行。 你好,刀哥,如何充分发挥单机性能,我能想到的只有算法优化和多进程,按照千万用户和五十万物品算,采用物品的协同过滤,每个物品有十个纬度的特征,每个用户有十个纬度特征,我觉得这个量太大,单机实时推荐物品无法做到,想听一下你的高见2018-05-021
尹士果性能不足,请升级单机配置。根据经验,一个几千万用户,几十万到百万的物品的协同过滤或者矩阵分解,如果充分发挥单机的性能,综合效率会远远优于在 Spark 上运行。 你好,刀哥,如何充分发挥单机性能,我能想到的只有算法优化和多进程,按照千万用户和五十万物品算,采用物品的协同过滤,每个物品有十个纬度的特征,每个用户有十个纬度特征,我觉得这个量太大,单机实时推荐物品无法做到,想听一下你的高见2018-05-021 hqzhao每期都听,自己的研究方向就是RS,听完发现同样的问题站在不同的角度去理解会发现一片新天地。很感谢刑前辈!2018-05-011
hqzhao每期都听,自己的研究方向就是RS,听完发现同样的问题站在不同的角度去理解会发现一片新天地。很感谢刑前辈!2018-05-011- Geek_00437c两个问题: 1、如果一个用户足够活跃,把离线召回的item都用完了,这时候近线层的召回补充就发挥很大作用了? 2、您的github是啥,网上没找到~2019-11-18
 Warner老师,近线层中的"在线数据"是怎么产生的?在线层输出的吗?2019-07-23
Warner老师,近线层中的"在线数据"是怎么产生的?在线层输出的吗?2019-07-23
收起评论

