

19 | 深度学习在推荐系统中的应用有哪些?
刑无刀

该思维导图由 AI 生成,仅供参考
时至今日,深度学习已经不是一个新名词了,由于它的出现,计算机视觉、自然语言理解等领域的从业者都过上了好日子,错误率大幅度降低。
尤其是那些不断号称端到端的建模方式,让还在埋头于特征工程的推荐系统从业者们跃跃欲试,想赶紧引入深度学习大显身手。
经过这些年学界和业界的不断尝试,深度学习在推荐系统中已经有了很多成功的应用。
所以我在这个专栏里面理应本着实用落地的原则给你介绍一下,到底深度学习在推荐系统中有些什么应用,以及到底是怎么回事?
深度学习与推荐系统
深度学习也就是深度神经网络,并不是一个全新的概念,而是枯木逢春;所以它才能在计算力成本下降、效率提升、数据量陡增的今天得以焕发光彩,原来的浅层模型可以逐渐深入,挖掘出事物背后的更多规律和特征。
因此,深度学习的原理在这里并不做过多涉及,如果需要了解,你可以去专攻一下深度学习。
我在这里仅仅用简单的语言力图消除一些概念上的陌生感,在有了一些直观的认识后,直接进入到应用阶段,看看它可以帮助你做什么事。
你还记得矩阵分解吗?矩阵分解是把原来用户和物品之间的大矩阵,分解成了两个小矩阵相乘。这两个小矩阵小在哪?
原始的矩阵中,表示每个用户的向量是物品,表示每个物品的向量是用户,两者向量的维度都特别高不说,还特别稀疏,分解后用户向量和物品向量不但维度变得特别小,而且变稠密了。
业界还把这个稠密的向量叫做隐因子,意图直观说明它的物理意义:用户背后的偏好因子,物品背后的主题因子。
实际上,你完全可以把矩阵分解看成是一种浅层神经网络,只有一层,它的示意图如下。
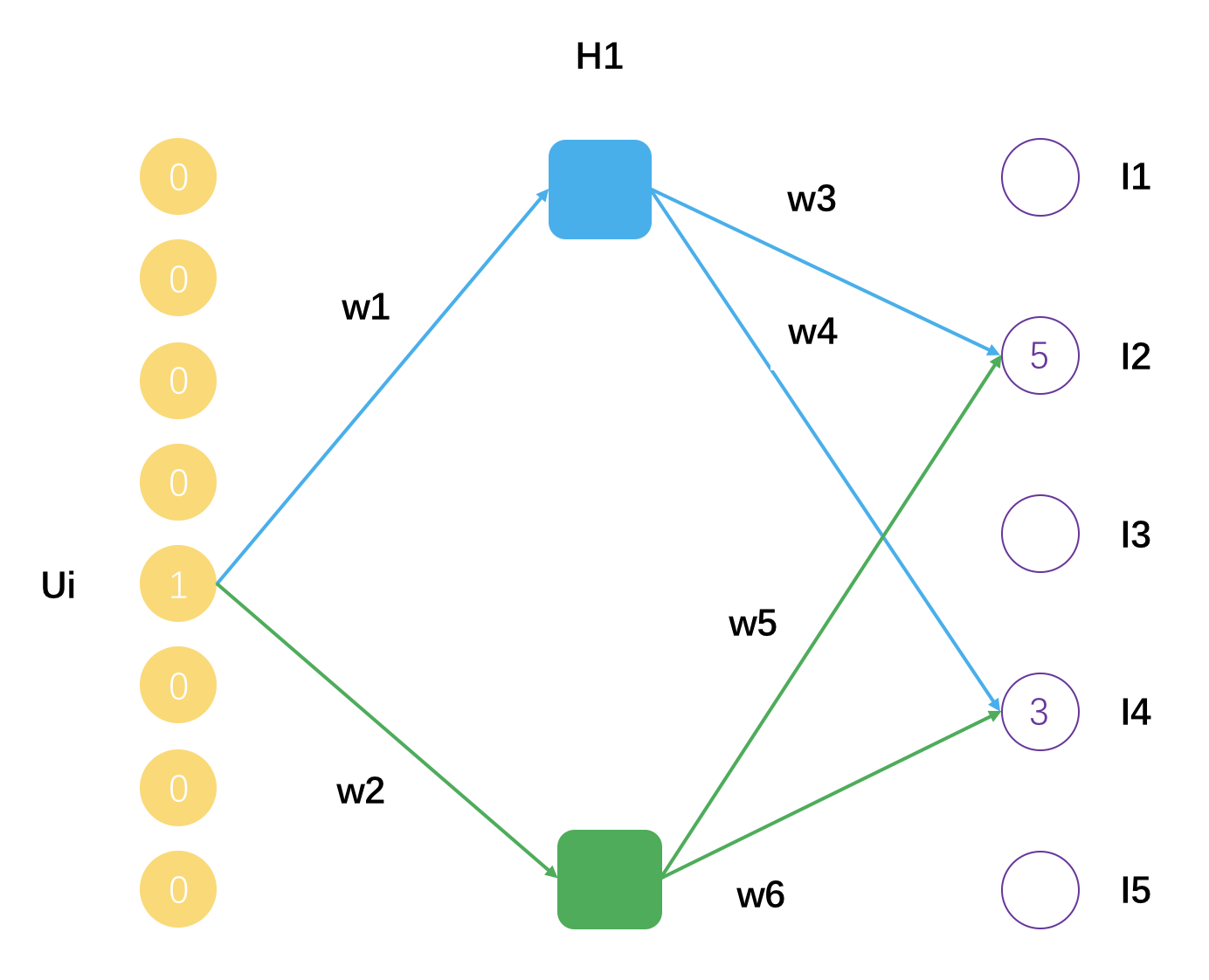
这个示意图表示了一个用户 Ui,评分过的物品有 I2 和 I4,分解后的矩阵隐因子数量是 2,用户 Ui 的隐因子向量就是[w1, w2],物品 I2 的隐因子向量是[w3, w5],物品 I4 的隐因子向量是[w4, w6]。
可以把矩阵分解看成是一个拥有一个隐藏层的神经网络,得到的隐因子向量就是神经网络的连接权重参数。
在前面的专栏中,我第一次提到深度学习时,还建议你把逻辑回归看成一个没有隐藏层的神经网络。因此,深度学习,也就是深度神经网络并不是那么神秘,只是深。这个“深”代表了事物的某些本质属性。
这种对本质属性的挖掘,有两个好处。
可以更加高效且真实地反映出事物本身的样子。对比一下,一张图片用原始的像素点表示,不但占用空间大,而且还不能反应图片更高级的特征,如线条、明暗、色彩,而后者则可以通过一系列的卷积网络学习而得。
可以更加高效真实地反映出用户和物品之间的连接。对比一下,以用户历史点击过的物品作为向量表示用户兴趣;用这些物品背后隐藏的因子表示用户兴趣,显然后者更高效更真实,因为它还考虑了物品本身的相似性,这些信息都压缩到隐因子向量中了,同时再得到物品的隐因子向量,就可以更加直接平滑地算出用户对物品的偏好程度。
这两个好处,正是深度学习可以帮助推荐系统的地方。第一个叫做 Embedding,就是嵌入,第二个叫做 Predicting,就是预测。
其实两者我在前面的内容都已经有涉及了,矩阵分解得到的隐因子向量就是一种 Embedding,Word2vec 也是一种 Embedding,Wide&Deep 则是用来预测的。关于第二种,具体来说有几个方向:深度神经网络的 CTR 预估,深度协同过滤,对时间序列的深度模型。
下面逐一带你认识。首先就是深度学习的第一种应用。
各种 2vec
你还记得在内容推荐那一章里,我跟你提到过,对内容的挖掘怎么深入都不为过,越深入越好,很多时候甚至优于对排序模型的优化。
那里提到了 Word2vec,用于学习词嵌入向量。当把一个词表示成一个稠密的向量后,就可以计算词的相似度,进而可以计算句子的相似度,也可以直接把这个稠密向量作为特征输入给高级的预测模型。
于是,这个 2vec 的思想,就被发扬光大了。首先还是在文本领域,从 Word2vec 到 Sentence2vec,再到 Doc2vec。其实思想都类似甚至会让你觉得有上当受骗的错觉。
简单介绍一下 Word2vec。你知道,Word2Vec 最终是每个词都得到一个稠密向量,十分类似矩阵分解得到的隐因子向量,得到这个向量有两个训练方法。
先说第一个方法,想象你拿着一个滑动窗口,在一篇文档中从左往右滑动,每一次都有 N 个词在这个窗口内,每移动一下,产生 N-1 条样本。
每条样本都是用窗口内一个词去预测窗口正中央那个词,明明窗口内是 N 个词,为什么只有 N-1 条样本呢?因为正中央那个词不用预测它本身啊。这 N-1 条样本的输入特征是词的嵌入向量,预测标签是窗口那个词。示意图如下所示。
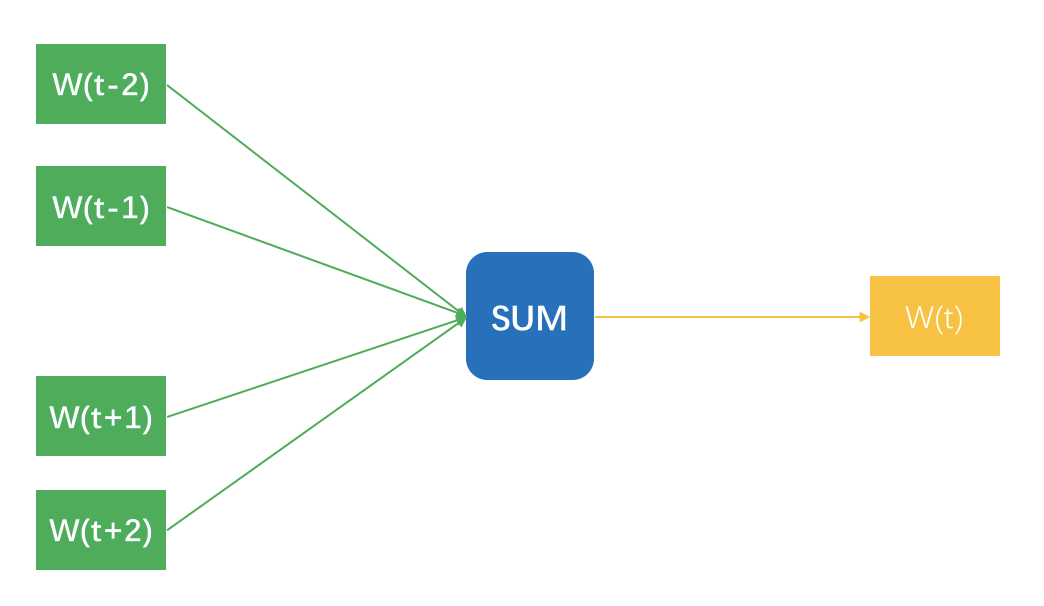
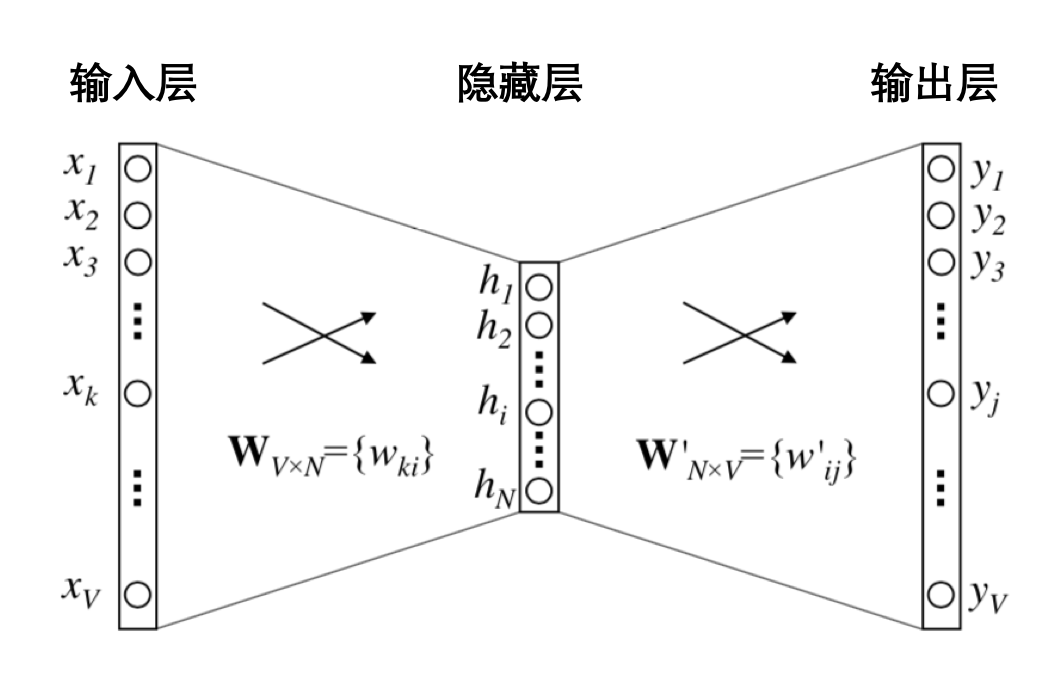
图中把 N-1 个样本放在一起示意的,无法看出隐藏层,实际上,输入时每个词可以用 One-hot 方式表示成一个向量,这个向量长度是整个词表的长度,并且只有当前词位置是 1,其他都是 0。
隐藏层的神经元个数就是最终得到嵌入向量的维度数,最终得到的嵌入向量元素值,实际上就是输入层和隐藏层的连接权重。示意图如下。
至于 Word2vec 的第二种训练方法,则是把上述的 N-1 条样本颠倒顺序,用窗口中央的词预测周围的词,只是把输入和输出换个位置,一样可以训练得到嵌入向量。
这里注意,看上去 Word2vec 是构造了一个监督学习任务,但实际上并不是为了得到一个预测模型,在实际中用词预测词,是为了得到词的嵌入向量,Embedding 本身就是目的。
我们沿着 Word2vec 这种学习嵌入向量的思路想,既然词可以表示成一个稠密向量干这干那,那不如来个 Sentence2vec,把一个句子表示成一个嵌入向量,通常是把其包含的词嵌入向量加起来就完事了。
而 Doc2vec 则略微一点点不同,说明一点,多个句子构成一个段落,所以这里的 Doc 其实就是段落。Doc2vec 在窗口滑动过程中构建 N-1 条样本时,还增加一条样本,就是段落 ID 预测中央那个词,相当于窗口滑动一次得到 N 条样本。
一个段落中有多少个滑动窗口,就得到多少条关于段落 ID 的样本,相当于这个段落中,段落 ID 在共享嵌入向量。段落 ID 像个特殊的词一样,也得到属于自己的嵌入向量,也就是 Doc2vec。
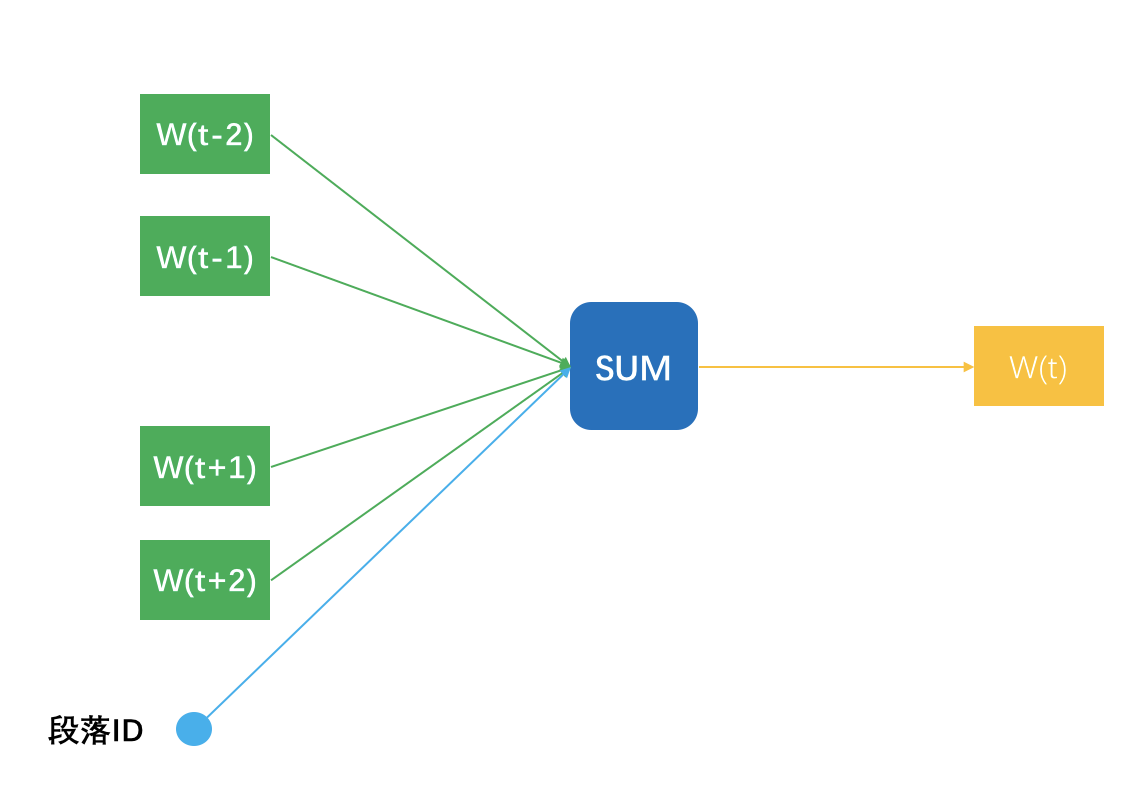
理解了 Word2vec 之后,它在推荐系统中的应用就有举一反三的应用。第一个就是 Product2vec,你看这名字就知道我要干嘛了,对,就是给商品学习一个嵌入向量。
这简直就是照着词嵌入的做法来,把用户按照时间先后顺序加入到购物车的商品,看成一个一个的词,一个购物车中所有的商品就是一个文档;于是照猫画虎学出每个商品的嵌入向量,用于去做相关物品的推荐,或者作为基础特征加入到其他推荐排序模型中使用。
类似的,如果是应用商场的 App 推荐,也可以依计行事,把用户的下载序列看成文档,学习每个 App 的嵌入向量。
虽然,这个嵌入学习得到的结果,样子和矩阵分解得到隐因子向量一样,但是机制不同,可以两者都有,拼接成一个更大的稠密向量去做你喜欢做的事,比如 CTR 预估。
且慢,各种 2vec 的做法其实还不算深度学习,毕竟隐藏层才一层而已。如果要用更深的模型学习嵌入向量,就是深度学习中的 AutoEncoder。
它是一种输入和输出一模一样的神经网络,这个神经网络就一个目的,更加清楚地认识自己,在这个优化目标指导下,学到的网络连接权重都是不同的嵌入向量,所以也叫做 AutoEncoder,自动编码器。
从输入数据逐层降维,相当于是一个对原始数据的编码过程,到最低维度那一层后开始逐层增加神经元,相当于是一个解码过程,解码输出要和原始数据越接近越好,相当于在大幅度压缩原始特征空间的前提下,压缩损失越小越好。
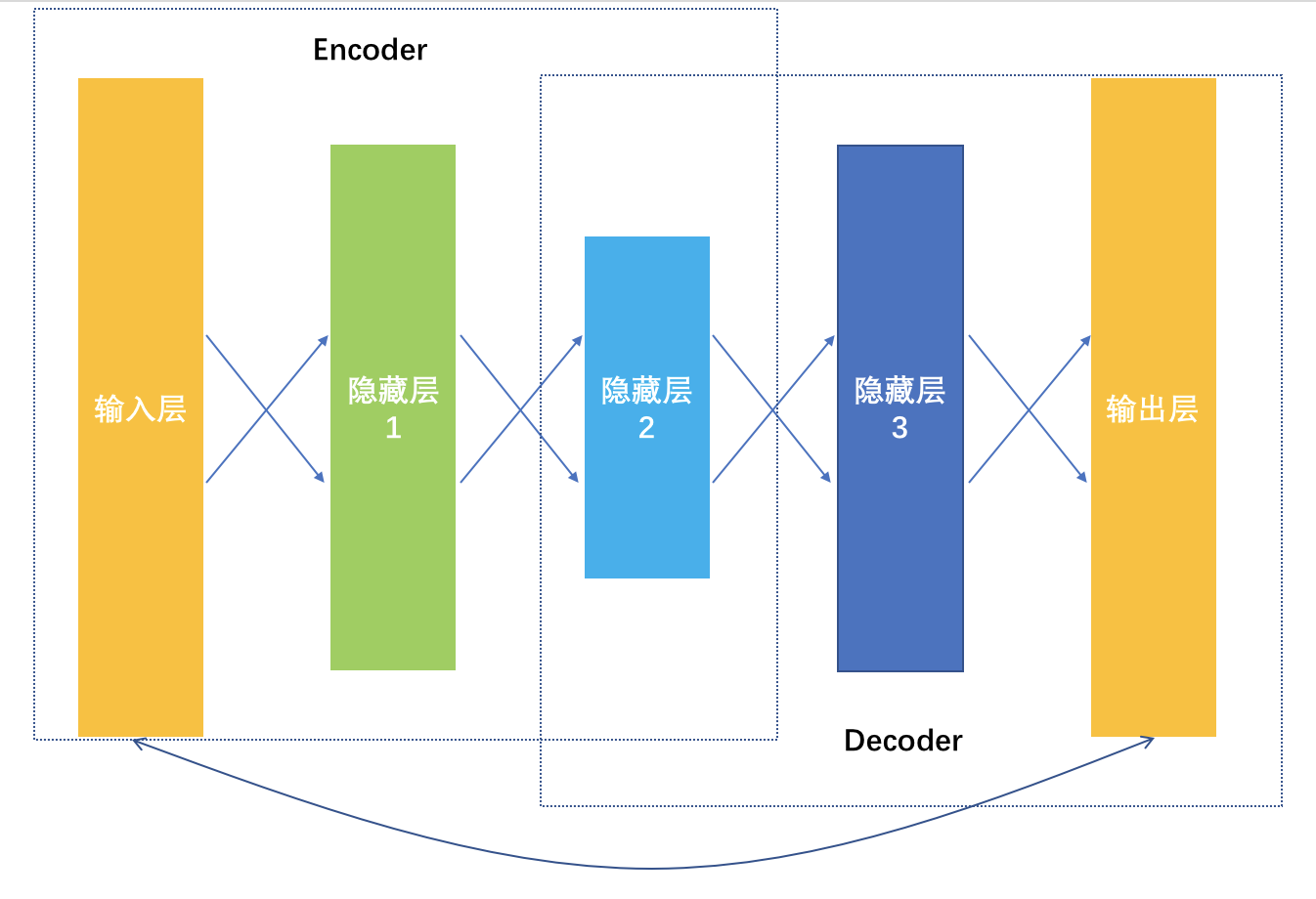
以上是深度学习如何通过学习更好地表达事物特征,帮助推荐系统取得更好效果的做法。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

深度学习在推荐系统中的应用成为热门话题。本文介绍了深度学习的原理和在推荐系统中的具体应用。通过Embedding和Predicting两种方式,深度学习实现了对用户和物品之间连接的高效反映。Embedding通过矩阵分解和Word2vec等方法,将用户和物品的隐因子向量表示为一种嵌入,更真实地反映事物本身的样子。Predicting则通过深度神经网络的CTR预估、深度协同过滤和对时间序列的深度模型等方向,实现了对用户对物品偏好程度的预测。这些应用使得推荐系统在实际应用中取得了很多成功的案例,为读者提供了深度学习在推荐系统中的应用概览。 此外,文章还以YouTube为例,详细描述了深度学习在视频推荐系统中的应用。YouTube将推荐的预测任务看成多分类,使用深度神经网络从用户历史反馈行为和场景信息中学习物品和用户的嵌入向量,以此预测用户下一个会观看的视频。整个推荐排序模型涉及了视频和用户的嵌入向量、搜索Query的嵌入向量、人口统计学信息等的嵌入,最终通过深度神经网络输出预测结果。在模型训练时使用Softmax作为输出层,但在实际线上预测服务时,通过近邻搜索近似计算推荐结果。这些实例展示了深度学习在推荐系统中的特征表达学习和排序模型上的应用。 总的来说,本文通过深入介绍深度学习在推荐系统中的应用,以及以YouTube为例的具体应用情况,展现了深度学习在推荐系统中的重要作用。文章内容丰富,涵盖了深度学习原理和在推荐系统中的多种具体应用,为读者提供了全面的了解和思考。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《推荐系统三十六式》,新⼈⾸单¥59
《推荐系统三十六式》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(11)
- 最新
- 精选
 jt120公式解析有问题,youtube的那个实现哪里还能找到资料?
jt120公式解析有问题,youtube的那个实现哪里还能找到资料?作者回复: chenkaijiang001@lianjia.com,你给我联系,我发给你。
2018-04-161- 异尘这里的模型是用作召回的,用softmax的思路同word2vec的预测部分类似,最终目的是得出embeded向量,用过embeded向量可以用很多模糊近邻算法快速召回,后续再应用wide&deep排序2018-05-1411
 林彦我的理解softmax已经线下预测出用户最有可能看的视频,线上预测如另一个评论所述为了从数百万个视频中计算最可能的N个类(视频),用softmax进行评分或校验计算成本比较高,无法满足线上的延时要求。我们假定物以类聚,找出和最可能的视频相近的N个邻居的效果和用softmax验证每个结果并筛选出最可能的N个是比较相近的。这里看原文的是选出的N个(数百个)视频的排序过程中引入了新的特征,然后用一个和候选集训练模型类似架构的深度神经网络,最后一层换成了逻辑回归来对推荐视频进行评分并排序。开始我还以为能利用近邻搜索的距离。2018-04-174
林彦我的理解softmax已经线下预测出用户最有可能看的视频,线上预测如另一个评论所述为了从数百万个视频中计算最可能的N个类(视频),用softmax进行评分或校验计算成本比较高,无法满足线上的延时要求。我们假定物以类聚,找出和最可能的视频相近的N个邻居的效果和用softmax验证每个结果并筛选出最可能的N个是比较相近的。这里看原文的是选出的N个(数百个)视频的排序过程中引入了新的特征,然后用一个和候选集训练模型类似架构的深度神经网络,最后一层换成了逻辑回归来对推荐视频进行评分并排序。开始我还以为能利用近邻搜索的距离。2018-04-174 橡皮泥boy老师,看前面介绍BPR排序模型的时候,我觉得矩阵因子分解的方法,可以预测出同个用户对不同商品的评分,这是同个用户的评分标准,根据评分直接就可以拍个顺序了。这种方法跟BPR比较的话,孰好孰坏那?2018-04-182
橡皮泥boy老师,看前面介绍BPR排序模型的时候,我觉得矩阵因子分解的方法,可以预测出同个用户对不同商品的评分,这是同个用户的评分标准,根据评分直接就可以拍个顺序了。这种方法跟BPR比较的话,孰好孰坏那?2018-04-182- 刘大猫老师介绍的这部分是matching部分,不是很关注具体的排序,计算softmax成本太大,所以召回的时候用近邻检索,提高效率。2018-04-162

 benyingyoutude做了个user2vec2018-11-041
benyingyoutude做了个user2vec2018-11-041- haolison各位大神好,我是新来的haolison,我收听点播的时候怎么听不到讲课的呢?2019-11-10
- 罗马工匠回答下后面思考题,跟大家探讨。embedding暗藏距离的表达,就是生长方式是受某种假设而约束的,同时用户和物品的embedding生长在同一空间,这样就能用embedding来计算相似性。比如word2vec,是基于相似上下文的单词具有相同含义的假设,用词来预测词,softmax表达了这种假设,学出来的embedding天然有相似性表达。而YouTube的则是另一个思路,是协同过滤的深度学习表达,从特征层面可以看做近邻推荐(看过的视频)+side info,从网络结构也可以看做svd++的dl表达。都暗含距离的含义。你甚至都能把这个网络看做side info+word2vec。softmax+损失函数强调的是要预测的物品要有最大概率,这个从技术层面保证你看过的视频跟后来看过的视频间的相似性。 embedding暗含相似性后,自然可以用距离来求,快捷较准确。2019-10-061
- shangqiu86YouTube那篇论文我也看过,也看过一些对该论文解读的部分,感觉论文的大部分介绍的还是特征的选择,希望老师以后可以单独开一些讲解最新最热paper的课,我会继续支持的。2019-05-05
 科技狗请问老师,YouTube 的ranking 部分,如何对观看时长预测exp(wx+b)和点击概率加权LR同时输出的?2018-04-16
科技狗请问老师,YouTube 的ranking 部分,如何对观看时长预测exp(wx+b)和点击概率加权LR同时输出的?2018-04-16
收起评论

