

32|CQRS(下):CQRS还有哪些变化?

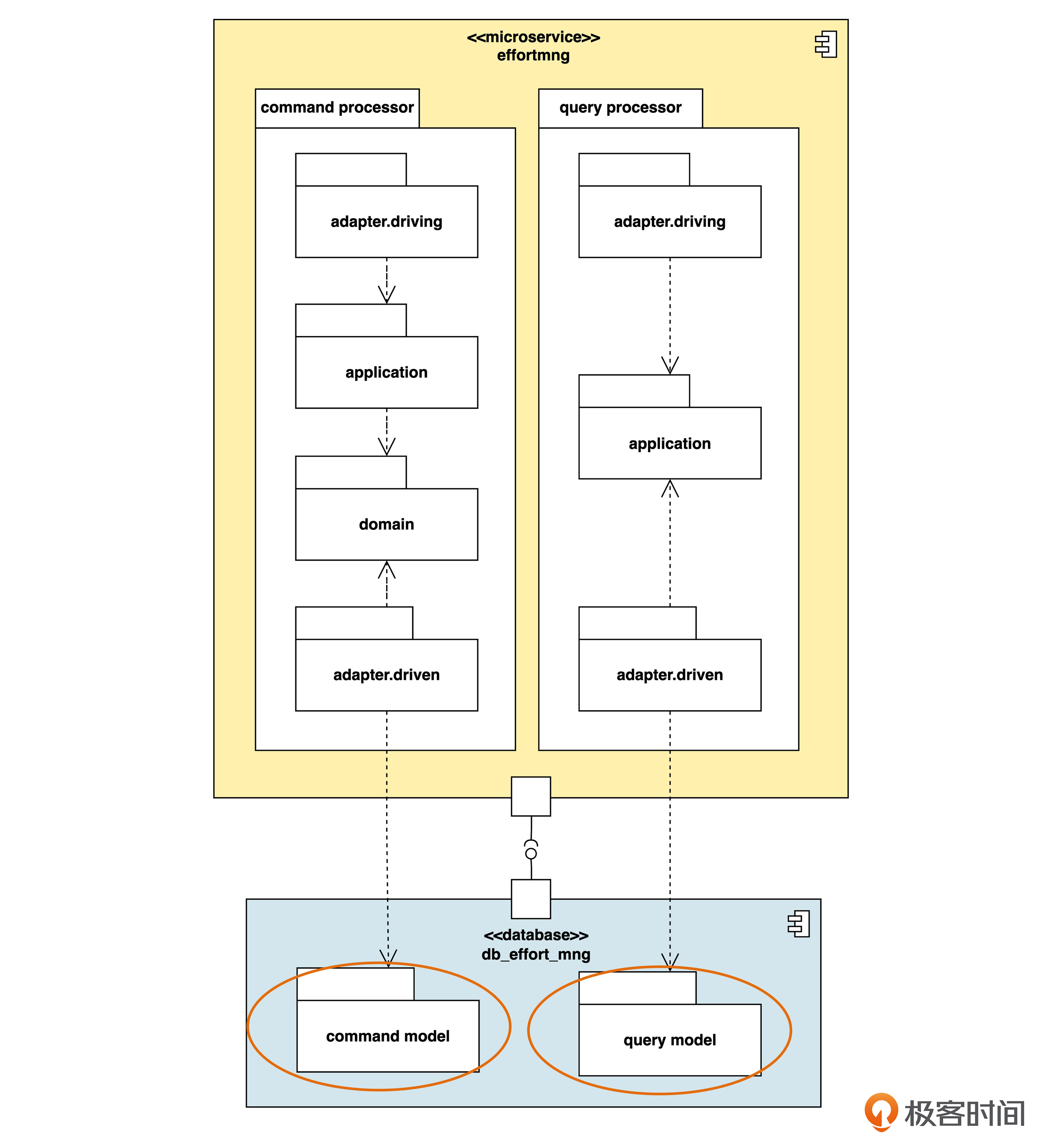
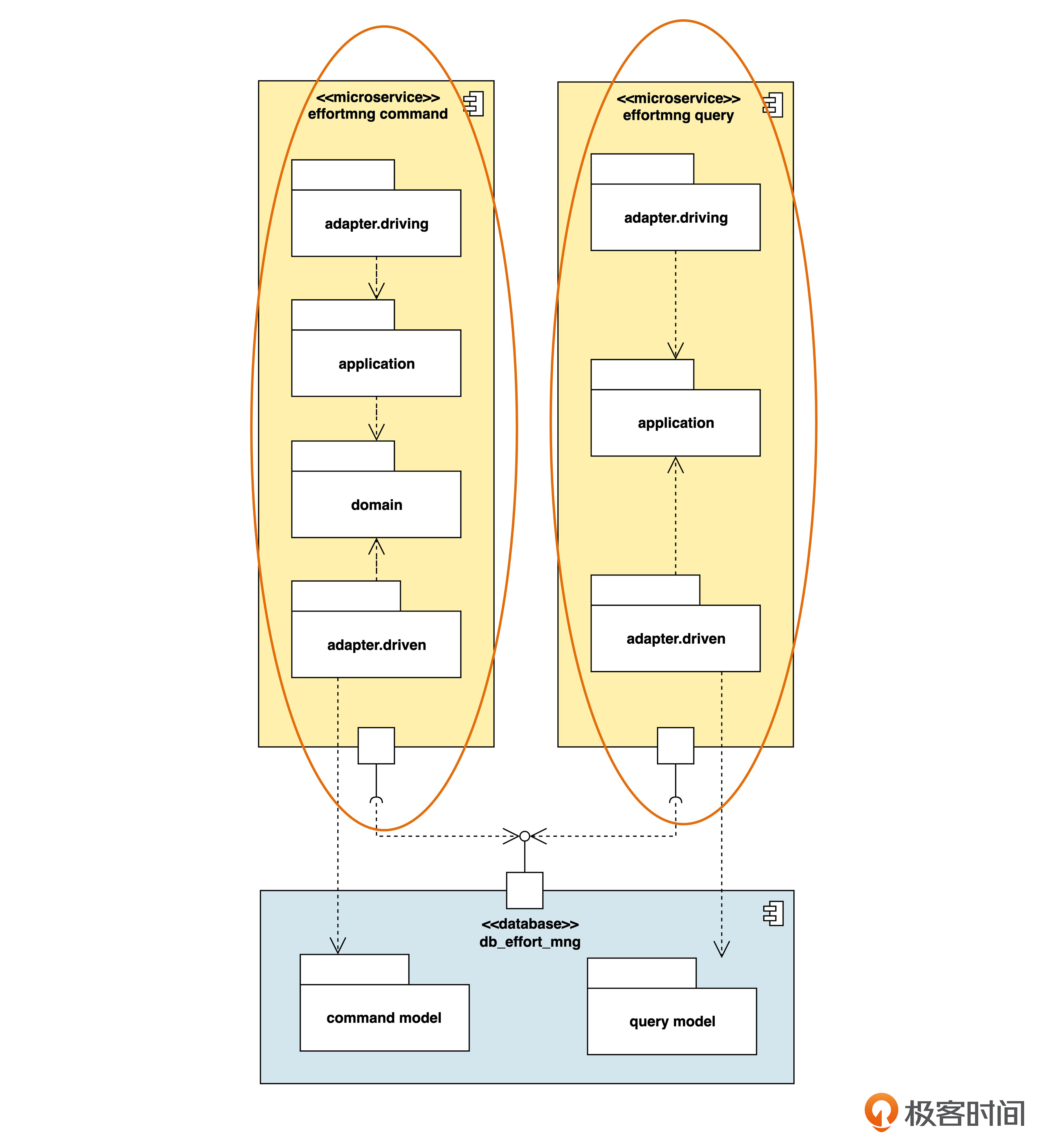
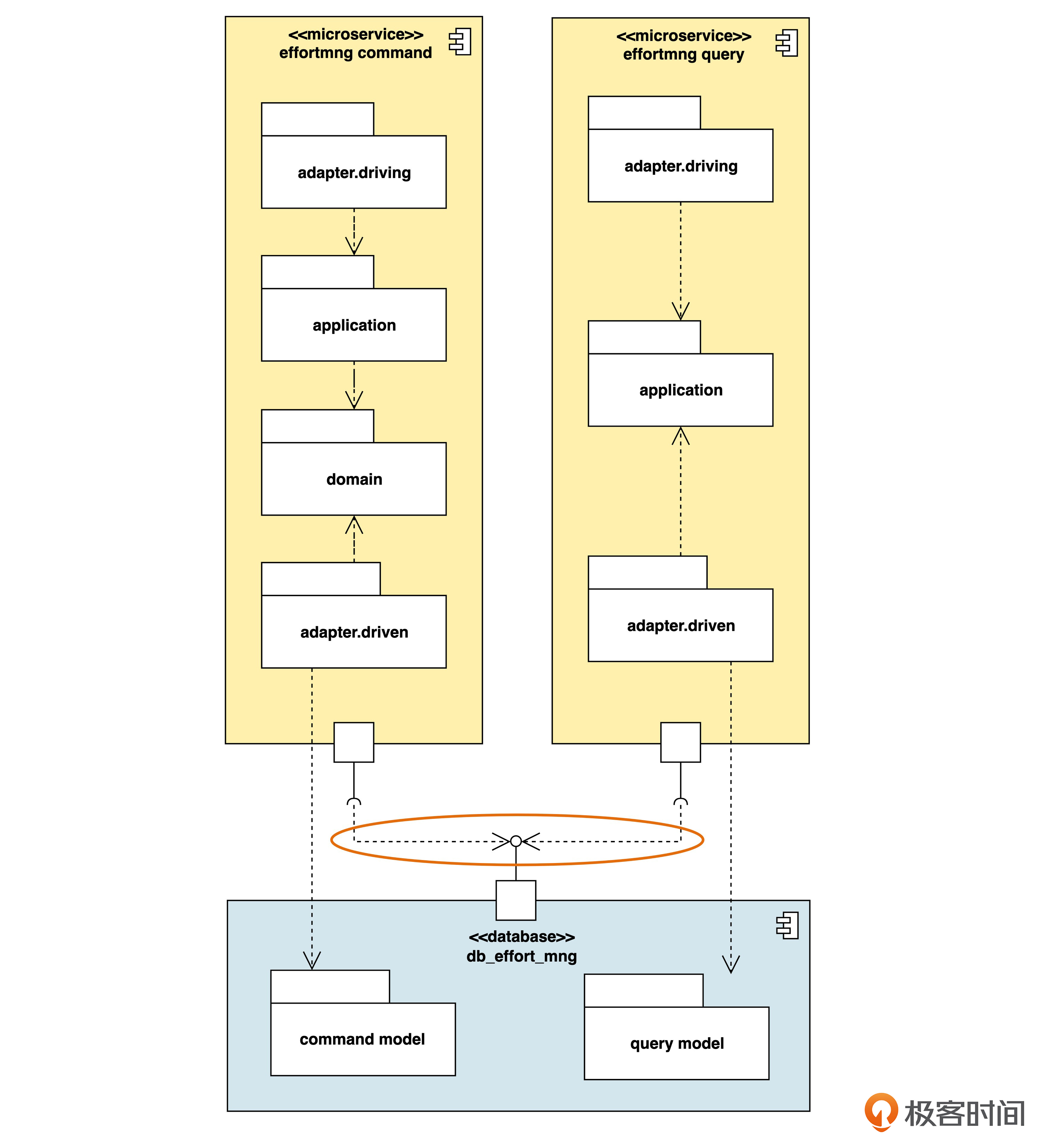
应用服务分离
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

CQRS(下):CQRS还有哪些变化?本文深入探讨了CQRS的变化,主要包括应用服务分离和数据库实例分离两种策略。应用服务分离通过拆分微服务来满足高并发性能需求,而数据库实例分离则通过拆分数据库实例来解决性能瓶颈。文章还总结了各种策略的组合,强调了为了实现命令进行的查询的微妙问题。此外,还提出了两道思考题,引发读者思考。整体而言,本文深入浅出地介绍了CQRS的变化及其实际应用,对于想要深入了解CQRS的读者具有一定的参考价值。
《手把手教你落地 DDD》,新⼈⾸单¥59

全部留言(12)
- 最新
- 精选
 aoe“为了实现命令而进行的查询”其实不算 CQRS 里的 Q,而是应该在命令处理器中处理,这点提醒的太及时了,不然不知道什么时候才能从迷惑中走出来
aoe“为了实现命令而进行的查询”其实不算 CQRS 里的 Q,而是应该在命令处理器中处理,这点提醒的太及时了,不然不知道什么时候才能从迷惑中走出来作者回复: 你能注意到这一点非常好! 有些同学读这一段,可能就略过去了。
2023-03-03归属地:浙江36 Fredo1. 如果查询比较简单,是不是可以直接走领域模型,而不用 Q 2. 搜索场景,canal 增量同步 ES;flink CDC 同步到数仓
Fredo1. 如果查询比较简单,是不是可以直接走领域模型,而不用 Q 2. 搜索场景,canal 增量同步 ES;flink CDC 同步到数仓作者回复: 是的,CQRS不是必须要用的
2023-03-02归属地:广东23 你来吧手把手教你落地DDD的源代码在哪里呢
你来吧手把手教你落地DDD的源代码在哪里呢编辑回复: https://github.com/zhongjinggz/geekdemo 目前放出了迭代1的,后面的正在逐渐补充
2023-03-22归属地:浙江31 黑夜看星星老师,请教数据库结构分离和数据库实例分离的区别
黑夜看星星老师,请教数据库结构分离和数据库实例分离的区别作者回复: 一般用 create database 语句可以创建一个 database 也就是数据库实例。数据库结构分离,指的是有两套表,但还在同一个 database; 数据库实例分离,指的是在两个不同的 database.
2023-08-28归属地:广东2 NoSuchMethodError比如领域服务中需要查询list,list中的item是聚合根,且只需要item中的部分属性,那么还需要挨个重新生成聚合根嘛
NoSuchMethodError比如领域服务中需要查询list,list中的item是聚合根,且只需要item中的部分属性,那么还需要挨个重新生成聚合根嘛作者回复: 如果仅仅是查询功能,那么不用
2023-04-24归属地:江苏 胡昌龙钟老师,如果一个聚合如营销补贴计算。需要用到同一限界上下文里的另一个聚合 如营销补贴规则。考虑到性能,此时希望从数据库只查询出补贴规则的局部属性,是建一个新的值对象类来接收并参与运算,还是使用原来的补贴规则聚合对象类,只是对局部属性赋值呢(感觉模型重建就不完整啦)?假设新建值对象类,那如果有多种计算场景,需要用到不同的补贴规则局部属性,这样会导致建出很多的类来,这些个类放在哪里又比较合适?
胡昌龙钟老师,如果一个聚合如营销补贴计算。需要用到同一限界上下文里的另一个聚合 如营销补贴规则。考虑到性能,此时希望从数据库只查询出补贴规则的局部属性,是建一个新的值对象类来接收并参与运算,还是使用原来的补贴规则聚合对象类,只是对局部属性赋值呢(感觉模型重建就不完整啦)?假设新建值对象类,那如果有多种计算场景,需要用到不同的补贴规则局部属性,这样会导致建出很多的类来,这些个类放在哪里又比较合适?作者回复: 需要了解更多背景,才能准确回答。营销补贴规则这个聚合有哪几个领域对象组成、作为一个聚合的理由是什么?这些对象各有多少属性?计算时希望用到属性有多少?来自于哪个对象?等等。 现在只能按常理回答一下,如果要用到的对象总共字段不多,比如5个,用到其中3个,那么整体拿出来也不会影响太大性能。如果对象字段很多,比如几十个,那么就应该进一步拆成值对象或实体。拆分的时候,不完全是按照使用的需求,而是按照业务概念。由于是按照业务概念,所以即使有不同的计算场景,拆出的实体或值对象也应该基本上保持稳定。
2023-04-15归属地:浙江- 胡昌龙钟老师,如果一个聚合如营销补贴计算。需要用到同一限界上下文里的另一个聚合 如营销补贴规则。考虑到性能,此时希望从数据库只查询出补贴规则的局部属性,是建一个新的值对象类来接收并参与运算,还是使用原来的补贴规则聚合对象类,只是对局部属性赋值呢(感觉模型重建就不完整啦)?假设新建值对象类,那如果有多种计算场景,需要用到不同的补贴规则局部属性,这样会导致建出很多的类来,这些个类放在哪里又比较合适?
作者回复: 已经在另一个问题里统一回复了
2023-04-14归属地:上海 - 胡昌龙钟老师,如果一个聚合如营销补贴计算。需要用到同一限界上下文里的另一个聚合 如营销补贴规则。考虑到性能,此时希望从数据库只查询出补贴规则的局部属性,是建一个新的值对象类来接收并参与运算,还是使用原来的补贴规则聚合对象类,只是对局部属性赋值呢(感觉模型重建就不完整啦)?假设新建值对象类,那如果有多种计算场景,需要用到不同的补贴规则局部属性,这样会导致建出很多的类来,这些个类放在哪里又比较合适?
作者回复: 在另一个题里统一回复了
2023-04-14归属地:上海  杰老师,如果是应用和数据库都不分离的情况,用cqrs是不是可以理解为我直接跟以前一样,使用表关联查询就行?
杰老师,如果是应用和数据库都不分离的情况,用cqrs是不是可以理解为我直接跟以前一样,使用表关联查询就行?作者回复: 在“Q”的部分是这样的
2023-04-12归属地:广东2 6点无痛早起学习的和尚
6点无痛早起学习的和尚 思考题: 1. 需求一:没有说清楚累计工时信息是不是 累计工时时间? 直接 select effort_item_id,xxx effort_record where emp_id = xxx and 时间区间 group by effort_item_id 需求二:把项目表、工时项、工时记录表 join 越到后面,留言越少
思考题: 1. 需求一:没有说清楚累计工时信息是不是 累计工时时间? 直接 select effort_item_id,xxx effort_record where emp_id = xxx and 时间区间 group by effort_item_id 需求二:把项目表、工时项、工时记录表 join 越到后面,留言越少作者回复: 是累计工时实践。sql 语句里少了 sum(),应该group by emp_id
2023-02-28归属地:北京2

