

15|聚合的实现(上):怎样对聚合进行封装?

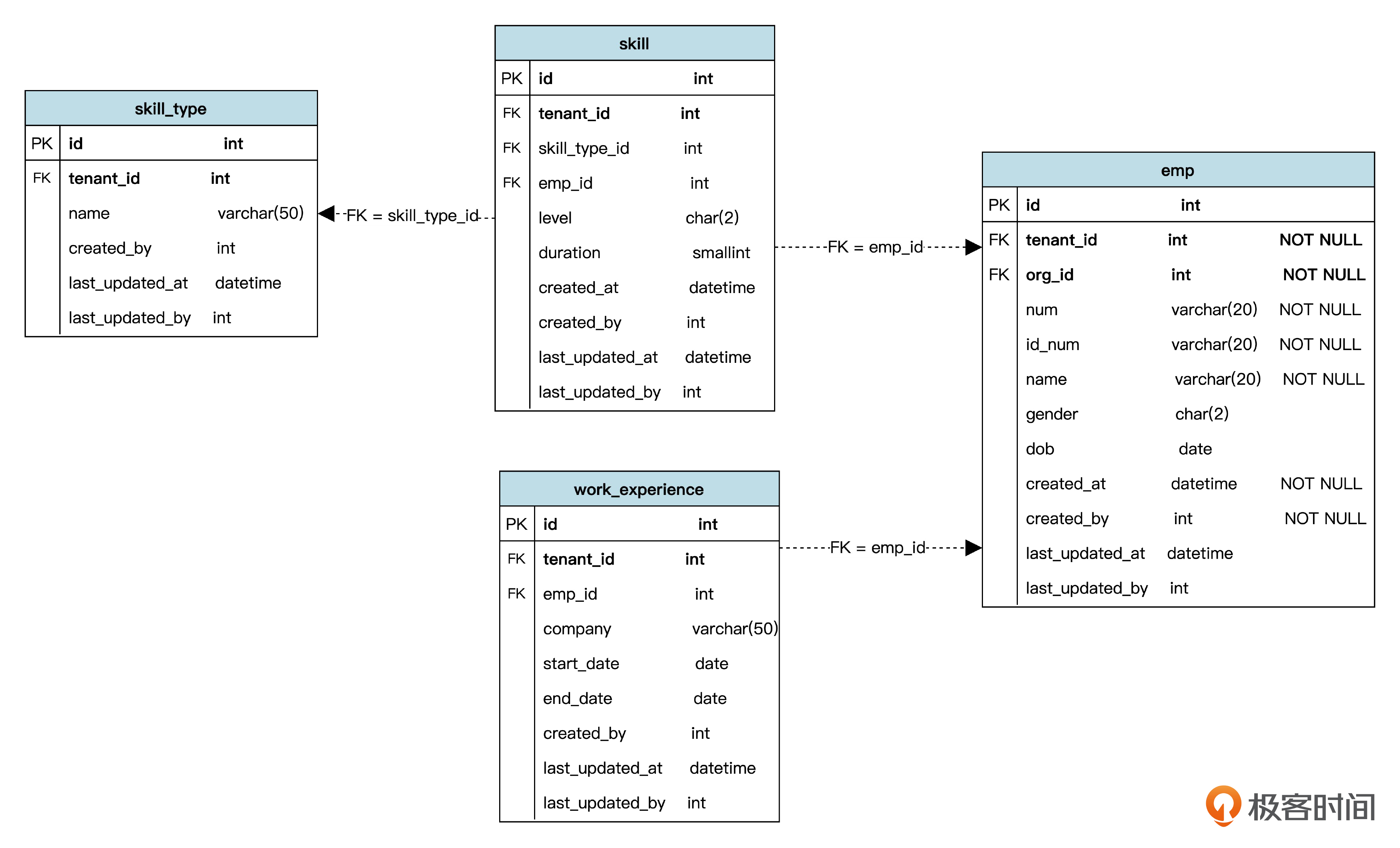
数据库设计
实现关联的两种方法
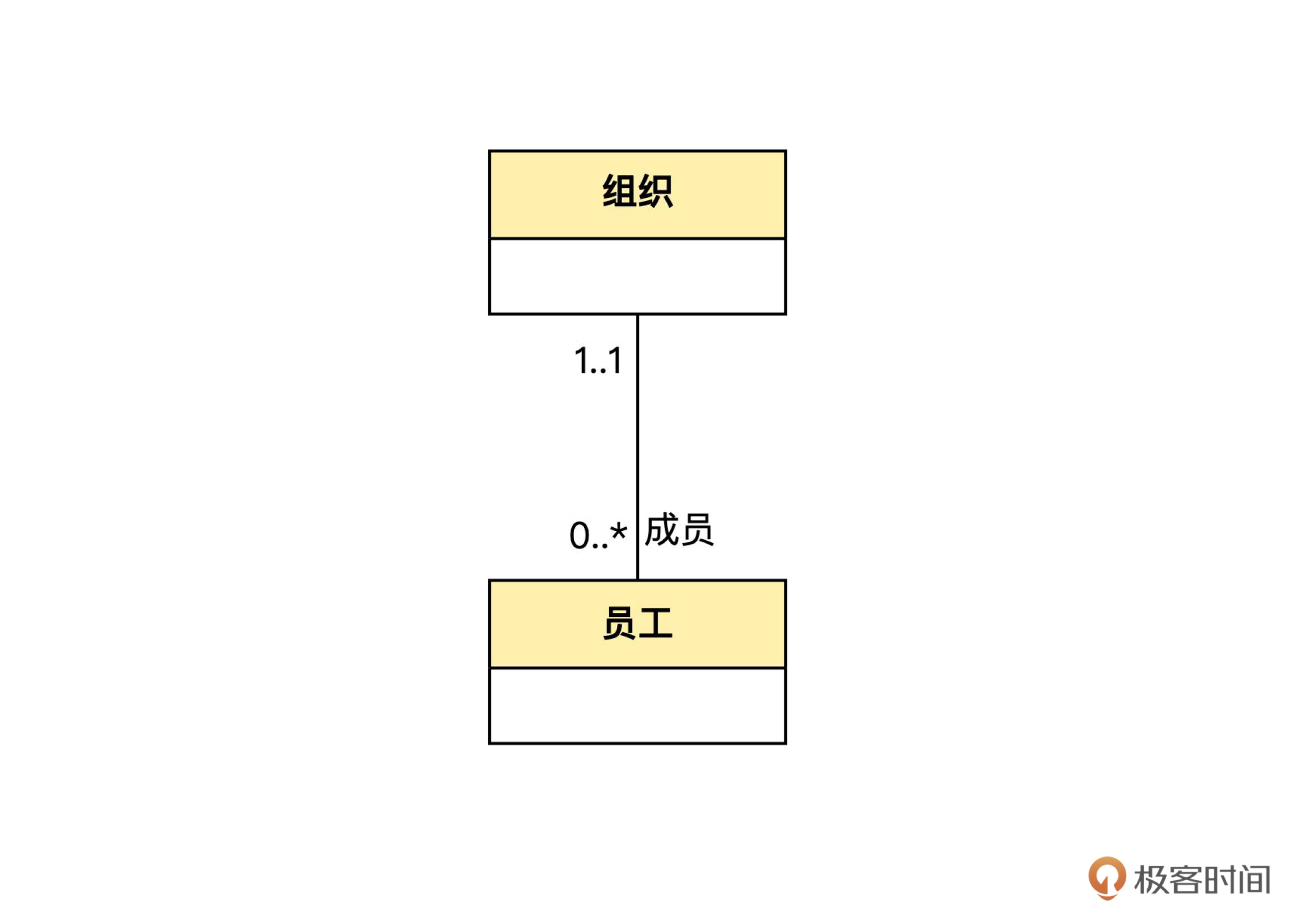
对象关联
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

本文深入探讨了聚合封装的实现方法,包括数据库设计中新增实体的表设计、对象关联和ID关联两种实现关联的方法。对于对象关联,文章介绍了双向对象关联和单向对象关联的实现方式,并对比了它们的优缺点。对于ID关联,文章说明了其简单直白的特点,但也指出了对象内部领域逻辑实现的限制。文章指出了在实践中有时会结合使用这两种方式,并根据国内现状采用偏向过程式风格的编程。此外,文章还介绍了聚合的封装方法,包括对非聚合根和聚合根对象的封装,强调了聚合外部对象对非聚合根对象只能读,不能写,必须通过聚合根才能对非根对象进行访问。通过具体技术手段如包级私权限封装构造器和方法、返回不可变列表、用聚合根创建和访问非根对象等,实现了对聚合的有效封装。文章还提出了两道思考题,引发读者对面向对象编程中聚合关系的思考。
《手把手教你落地 DDD》,新⼈⾸单¥59

全部留言(21)
- 最新
- 精选
- 邓西1. 对象间的关系。前文已经给到:聚合是一组对象的封装。 2. 个人理解,是对运行效率(考虑io开销)和有限内存的balance,聚合内部各对象互访频繁(也算是一种局部性原理)直接加载至内存中提升运算效率;而聚合间使用id则可以利用DB的索引提升查询效率。
作者回复: 回答得很好。
2023-01-30归属地:四川8  燃1对象之间的关系 2都可以封装成对象关系当然好,但是会遇到对象膨胀的问题,用id关联可以控制对象膨胀。我这里提个问题,业务中多个流程都修改同一个大对象,如果大对象数据有问题排查异常困难,这种问题如何解决
燃1对象之间的关系 2都可以封装成对象关系当然好,但是会遇到对象膨胀的问题,用id关联可以控制对象膨胀。我这里提个问题,业务中多个流程都修改同一个大对象,如果大对象数据有问题排查异常困难,这种问题如何解决作者回复: 大对象本身就是问题,最好尽量把大对象拆成若干小对象。
2023-01-11归属地:浙江5- Geek_8ac303针对思考题2有个疑问: 课程里的程序在聚合内部使用对象导航,会存在一个性能问题,就是技能和工作经验,在员工详情页是必须显示的,但是在列表页一般都不显示,即使用了jpa的懒加载还存在无法批量查询,性能下降的问题。在国内的数据量级OneToOne、ManyToMany这种自动化获取关联数据用法并不常用
作者回复: 确实有这个问题。会在第三迭代的CQRS解决。
2023-01-08归属地:广东3  张强1. 聚合是对象之间的关系。 2.能够想到的是性能。 如果聚合间也是用对象导航,就要把所有关联说一句查出来,会涉及很多表。有可能一次操作根本没有另一个聚合什么事,而需要把它查出来,就好多余的操作。
张强1. 聚合是对象之间的关系。 2.能够想到的是性能。 如果聚合间也是用对象导航,就要把所有关联说一句查出来,会涉及很多表。有可能一次操作根本没有另一个聚合什么事,而需要把它查出来,就好多余的操作。作者回复: 差不多。第二点主要是性能和方便性的权衡。
2023-01-07归属地:广东3 Jxin
Jxin 由于领域对象之间难以通过导航来协作,所以对象内部能实现的领域逻辑就很有限了,大量的逻辑就要在领域服务中实现。所以这种方式下,多数聚合都至少要搭配一个自己的领域服务。 这块理解差异很大。 虽然我们判断一段逻辑放领域服务还是应用层确实会参考是单聚合根实例的操作还是多聚合根实例。 但是本质上领域服务还是来自业务专家的认知,比如拼车功能,合包逻辑等等。它与聚合根是平级对等的。在领域建模时,我们会省掉那些复杂关系和注释 规则。但领域服务和关键领域事件是记录的。 因为这个图是与业务沟通的桥梁,你必然会有些功能不属于任何聚合根,无法仅用聚合根就承接住它们。那么你就需要这些模型来和业务方达成一致。
由于领域对象之间难以通过导航来协作,所以对象内部能实现的领域逻辑就很有限了,大量的逻辑就要在领域服务中实现。所以这种方式下,多数聚合都至少要搭配一个自己的领域服务。 这块理解差异很大。 虽然我们判断一段逻辑放领域服务还是应用层确实会参考是单聚合根实例的操作还是多聚合根实例。 但是本质上领域服务还是来自业务专家的认知,比如拼车功能,合包逻辑等等。它与聚合根是平级对等的。在领域建模时,我们会省掉那些复杂关系和注释 规则。但领域服务和关键领域事件是记录的。 因为这个图是与业务沟通的桥梁,你必然会有些功能不属于任何聚合根,无法仅用聚合根就承接住它们。那么你就需要这些模型来和业务方达成一致。作者回复: 第一段讲到不是判断逻辑放在领域服务还是应用层,而是放在领域服务还是领域对象。
2023-01-13归属地:山东2 6点无痛早起学习的和尚这里有 2 个代码问题请教 1. 为什么方法参数用包装类型,不担心传 null 的问题吗?是否用基本类型更好一点,这里有什么权衡吗? 2. 方法参数用包装类型,代码里判断相等用 == 隐患可能较高,比如在 Emp 类里
6点无痛早起学习的和尚这里有 2 个代码问题请教 1. 为什么方法参数用包装类型,不担心传 null 的问题吗?是否用基本类型更好一点,这里有什么权衡吗? 2. 方法参数用包装类型,代码里判断相等用 == 隐患可能较高,比如在 Emp 类里作者回复: 1 主要权衡的是另一个层面的空值问题。数据库里有整型空字段的话,正好可以和程序里包装类型的null对应。如果用基本类型,就要用一个特殊值代表空值。这么做的代价是略微影响性能。这只是我的习惯,你也可以不这么做。 2 我的程序里有用==吗?麻烦指出是哪一处,可能我疏忽了。
2023-02-07归属地:北京21 aoe两个疑问: 1. skill 表中 Level 首字母是大写,是有特殊原因吗(没有见到其他的大写字母)? 2. 聚合根对非聚合根的封装示例代码中操作 skills 相关的 3 个方法(getSkill、getSkills、addSkill)都是操作内存数据, 不会持久化到数据库,服务一重启,所有员工的技能都没了,这里只是展示一下“对象关联”的写法吗? ```java public class Emp extends AuditableEntity { // other fields ... private List<Skill> skills; // 读写 // constructors and other getters and setters ... public Optional<Skill> getSkill(Long skillTypeId) { return skills.stream() .filter(s -> s.getSkillTypeId() == skillTypeId) .findAny(); } public List<Skill> getSkills() { return Collections.unmodifiableList(skills); } void addSkill(Long skillTypeId, SkillLevel level , int duration, Long userId) { Skill newSkill = new Skill(tenantId, skillTypeId , LocalDateTime.now(), userId); newSkill.setLevel(level); newSkill.setDuration(duration); skills.add(newSkill); } // 对 experiences、postCodes 进行类似的处理 ... } ```
aoe两个疑问: 1. skill 表中 Level 首字母是大写,是有特殊原因吗(没有见到其他的大写字母)? 2. 聚合根对非聚合根的封装示例代码中操作 skills 相关的 3 个方法(getSkill、getSkills、addSkill)都是操作内存数据, 不会持久化到数据库,服务一重启,所有员工的技能都没了,这里只是展示一下“对象关联”的写法吗? ```java public class Emp extends AuditableEntity { // other fields ... private List<Skill> skills; // 读写 // constructors and other getters and setters ... public Optional<Skill> getSkill(Long skillTypeId) { return skills.stream() .filter(s -> s.getSkillTypeId() == skillTypeId) .findAny(); } public List<Skill> getSkills() { return Collections.unmodifiableList(skills); } void addSkill(Long skillTypeId, SkillLevel level , int duration, Long userId) { Skill newSkill = new Skill(tenantId, skillTypeId , LocalDateTime.now(), userId); newSkill.setLevel(level); newSkill.setDuration(duration); skills.add(newSkill); } // 对 experiences、postCodes 进行类似的处理 ... } ```作者回复: 1. 没有特殊原因,是个笔误,谢谢捉虫,我回头改过来 :) 2. 这一步先在内存操作,后面课程会进一步把内存中的数据保存到数据库。
2023-01-09归属地:浙江41 bin对于Emp这个聚合根来说,skills和experiences是实体还是值对象?看着像值对象,但是它们又有各自的业务规则。
bin对于Emp这个聚合根来说,skills和experiences是实体还是值对象?看着像值对象,但是它们又有各自的业务规则。作者回复: 这里没有把skill和experience建模为值对象,因为允许修改。另一方面,值对象也是可以而且应该有业务规则,等下一部分详细讲值对象的时候,再细聊。
2023-01-09归属地:广东1 小鱼儿吐泡泡1. 我理解是类对象之间的关系; =》 之前文中提到UML图, 表示就是类之间关系 2. 性能 对于思考题2,我有个疑问? 1. 假设现在有个界面,需要查询所有的员工列表,那么需要加载出整个页相关的员工聚合吗? 这会涉及很多表的读写,是否真的有必要?一定要符合DDD的模式?或者有什么更好的方式吗? 2. 对于聚合来讲,这个是事务操作的基本单位; 比如说我要添加技能,持久化时 - 全部持久化; 性能较差 - 仅持久化差异【技能】; ==》 性能较好,但是需要增加很多工作量 希望老师帮忙解答下? 实际落地中怎么取舍? 感觉实际DDD落地时,对于非JAVA项目,落地需要很多额外的工具支持,或者特定化开发
小鱼儿吐泡泡1. 我理解是类对象之间的关系; =》 之前文中提到UML图, 表示就是类之间关系 2. 性能 对于思考题2,我有个疑问? 1. 假设现在有个界面,需要查询所有的员工列表,那么需要加载出整个页相关的员工聚合吗? 这会涉及很多表的读写,是否真的有必要?一定要符合DDD的模式?或者有什么更好的方式吗? 2. 对于聚合来讲,这个是事务操作的基本单位; 比如说我要添加技能,持久化时 - 全部持久化; 性能较差 - 仅持久化差异【技能】; ==》 性能较好,但是需要增加很多工作量 希望老师帮忙解答下? 实际落地中怎么取舍? 感觉实际DDD落地时,对于非JAVA项目,落地需要很多额外的工具支持,或者特定化开发作者回复: 关于您的第一个问题,答案是CQRS,将在第三个迭代讨论。 关于您的第二个问题,在后面的课程里有一个方法对差异进行持久化,确实会增加些工作量。在性能不太敏感的场景,全部持久化也可以考虑。
2023-01-07归属地:广东31 打码的土豆这里的skill的构造方法和setter方法都是包级别私有,那如果需要批量输入skill列表,emp里需要怎么处理
打码的土豆这里的skill的构造方法和setter方法都是包级别私有,那如果需要批量输入skill列表,emp里需要怎么处理作者回复: 您说的pill输入skill列表具体指什么?
2023-11-21归属地:浙江

