

25|泛化的实现(上):怎样为泛化设计数据库?
钟敬

你好,我是钟敬。
前面几节课,我们学习了泛化的建模,今天开始我们继续学习泛化的实现。这节课我们先探讨怎样为泛化进行数据库设计,下节课再讨论怎样为泛化编写代码。
这里又包含两个维度的变化,一个是怎样设计表,一个是怎样确定主键。
设计表的策略
我们先来讨论设计表的方法。为了说明问题,我们结合一个商家向不同客户售卖商品的例子来讲。
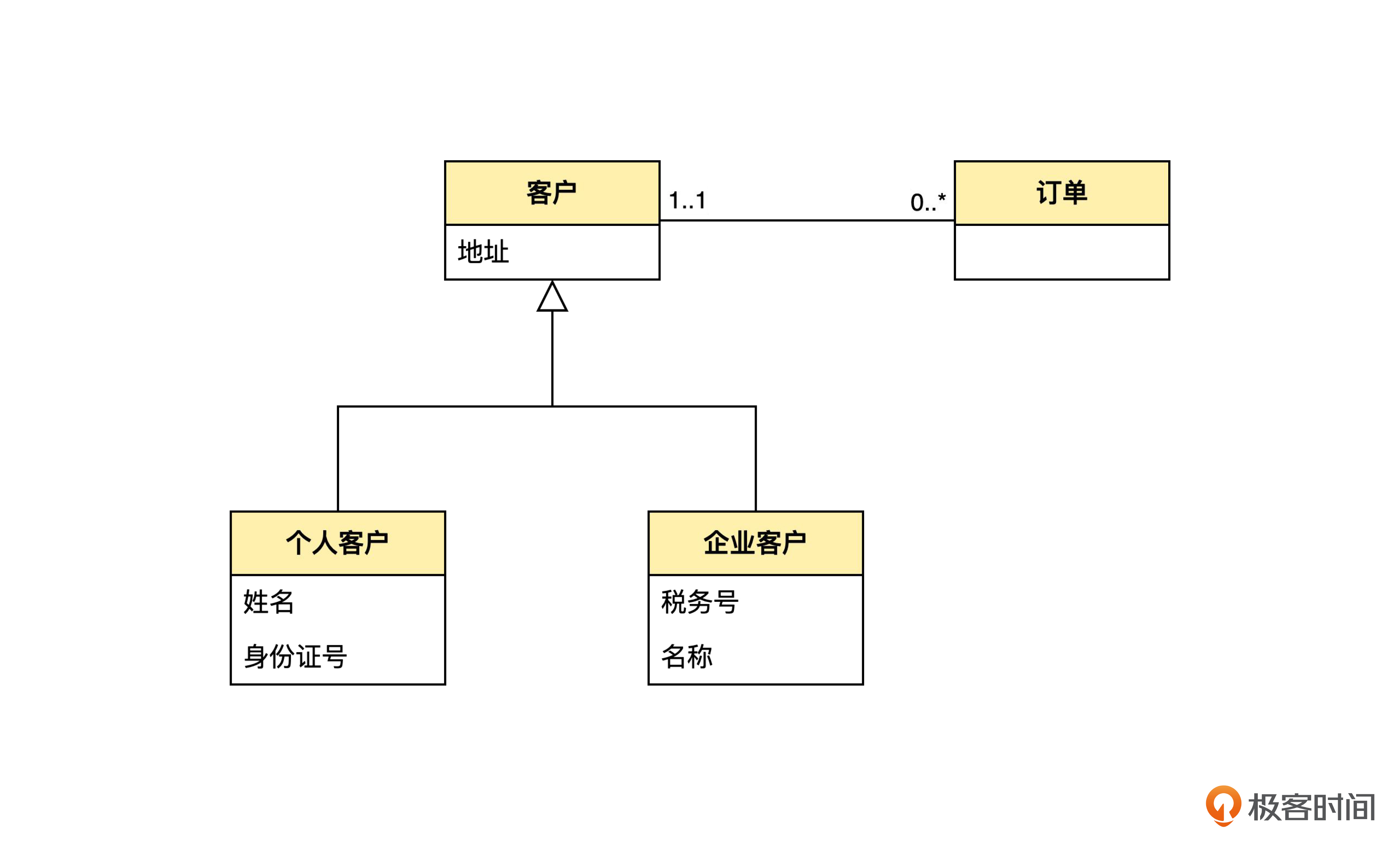
这个领域模型,说的是一个商家可以把商品卖给个人或者企业。也就是说,个人客户和企业客户都是客户。所以可以抽取出泛化关系。客户实体里的送货地址属性,以及客户和订单之间的一对多关联,都体现了个人客户和企业客户的共性。而个人客户里的姓名、企业客户里的税务号等属性,体现了个人客户和企业客户的区别。
为泛化体系设计表,有 3 种基本策略。
每个类一个表。
每个子类一个表。
整个泛化体系一个表。
这三条策略读起来可能有些拗口,没关系,我们一个一个解释。
每个类一个表
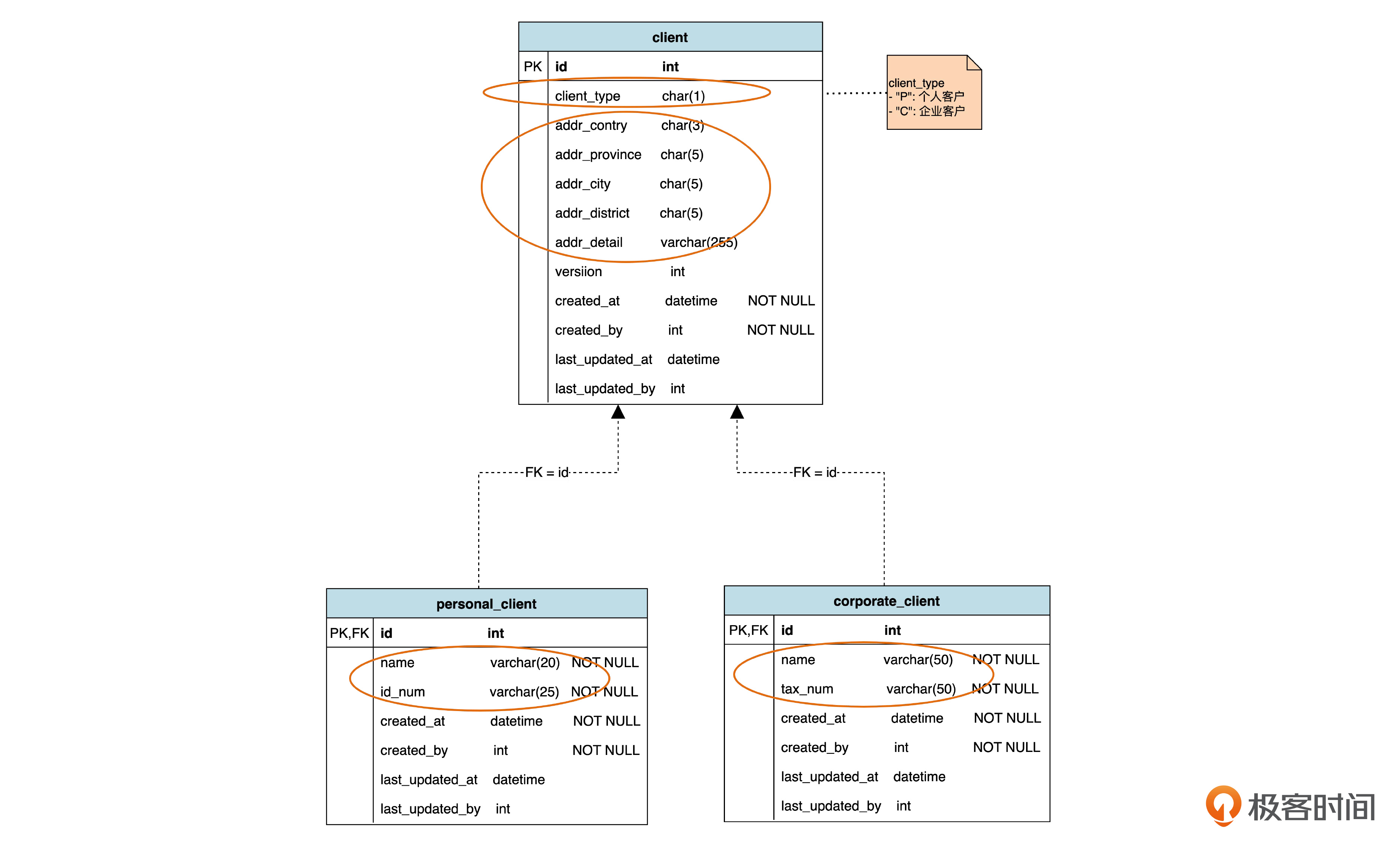
第一种策略是“每个类一个表”,也就是说不管父类还是子类,都各建一个表。对于上面这个关于客户的例子,实际上就要建 3 个表。就是下面这个图的样子。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

本文深入探讨了泛化实现的数据库设计方法,主要从设计表的策略和设计主键的策略两个方面展开讨论。在设计表的策略上,作者提出了三种基本策略:每个类一个表、每个子类一个表、整个泛化体系一个表,并分析了它们的优缺点。针对不同情况,提出了综合考虑空间效率、时间效率和系统可维护性等因素的建表策略选择方法。在设计主键的策略上,介绍了共享主键和不共享主键两种选择,并结合具体案例进行了说明。通过本文的阐述,读者可以深入了解泛化实现的数据库设计方法,以及在实践中如何选择合适的策略。文章还提出了两道思考题,引发读者对数据库设计的深入思考。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《手把手教你落地 DDD》,新⼈⾸单¥59
《手把手教你落地 DDD》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(4)
- 最新
- 精选
 Michael
Michael 我明白泛化建表的三种策略的考量,但是不太明白“共享主键”在设计里起到的作用,或者说为什么还要考虑共享主键这件事情?老师能不能再展开说说?
我明白泛化建表的三种策略的考量,但是不太明白“共享主键”在设计里起到的作用,或者说为什么还要考虑共享主键这件事情?老师能不能再展开说说?作者回复: 假如我们认为个人客户和团队客户都是客户,是同一类东西,那么同一类东西用同一套ID,在逻辑上是合理的。另一方面,其他实体引用客户的时候,可以用统一的ID来引用。
2023-02-10归属地:陕西3 子衿1. 可以考虑新增一个表表示所有员工都可以填报的工事项有哪些,当新增不需要分配员工的项目,或普通工时项时,都冗余插入该表一份,这样原来查询3次就优化为查询两次,本质还是CQRS,从查询角度考虑如何设计,但导致写加重,读减轻 2. 感觉本质考虑的还是一样的,多个表更灵活更贴合领域模型,但需要关联的场景就会性能下降
子衿1. 可以考虑新增一个表表示所有员工都可以填报的工事项有哪些,当新增不需要分配员工的项目,或普通工时项时,都冗余插入该表一份,这样原来查询3次就优化为查询两次,本质还是CQRS,从查询角度考虑如何设计,但导致写加重,读减轻 2. 感觉本质考虑的还是一样的,多个表更灵活更贴合领域模型,但需要关联的场景就会性能下降作者回复: 嗯,不错
2023-02-07归属地:浙江1 KelperOvO我感觉建出来出来的模型是有问题,项目和子项目不应该有工时项id,工时项id不是项目的信息
KelperOvO我感觉建出来出来的模型是有问题,项目和子项目不应该有工时项id,工时项id不是项目的信息作者回复: 这取决于我们是否将项目看作一种工时项
2023-05-28归属地:北京 6点无痛早起学习的和尚学着学着,逐渐吃力起来,前面的好多业务知识都忘了
6点无痛早起学习的和尚学着学着,逐渐吃力起来,前面的好多业务知识都忘了编辑回复: 可以随时review前文~
2023-02-21归属地:北京
收起评论

