

08|数据库设计:怎样按领域模型设计数据库?

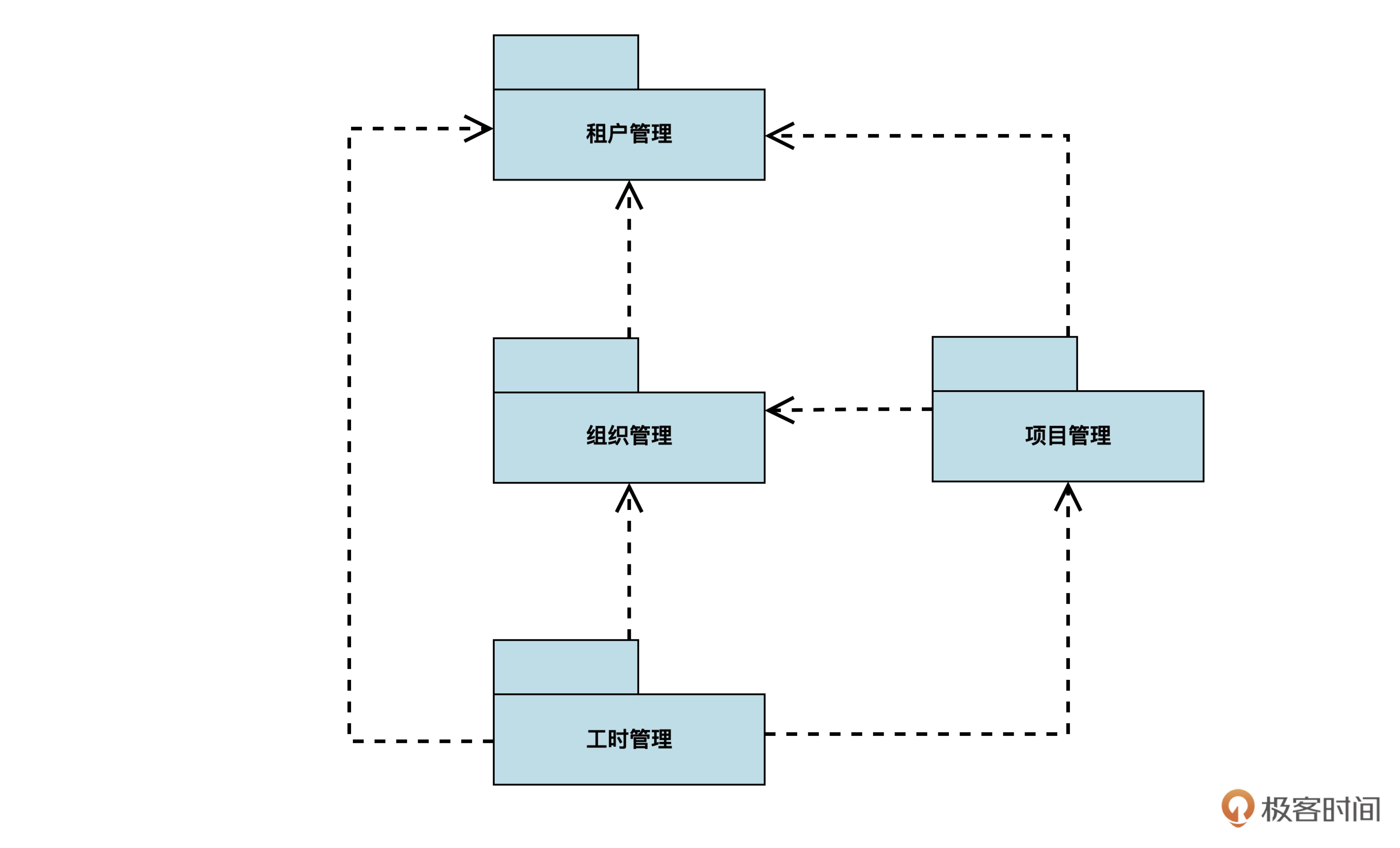
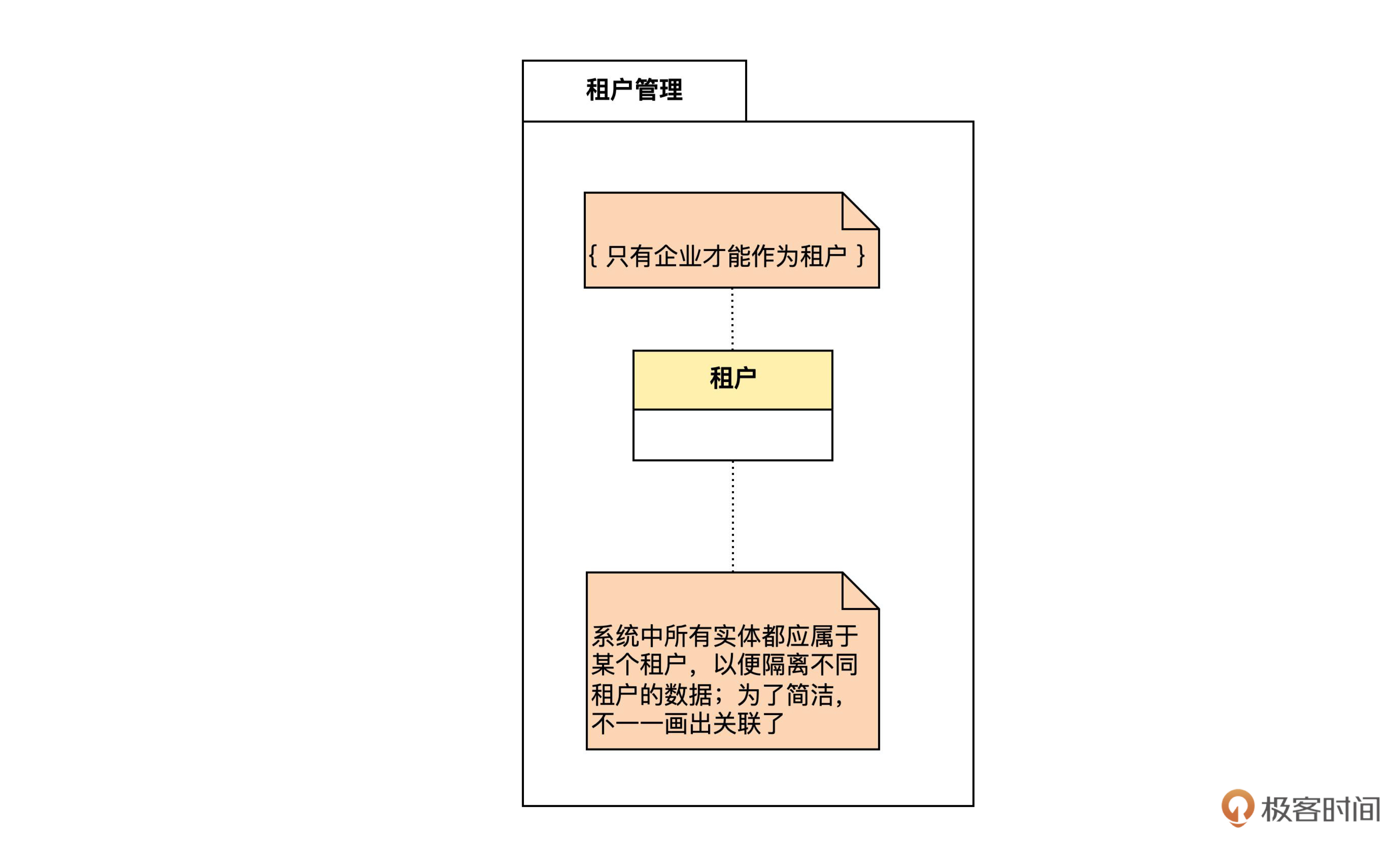
“租户管理”的数据库设计
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

本文介绍了如何按照领域模型设计数据库,重点讨论了数据库设计的实现过程。作者首先介绍了建立物理数据模型的主要目的和内容,包括建立数据表、字段、主键、外键以及数据类型和约束。然后,作者通过具体的领域模块,如租户管理、组织管理、项目管理和工时管理,逐步展示了数据库设计的过程。在每个模块的设计中,作者详细解释了如何将领域模型转化为数据库设计,包括表的设计、外键的处理以及字段的补充。此外,作者还介绍了在数据库设计中使用词汇表来保持中英文一致的方法,并提出了一些设计技巧,如虚拟外键的使用和绘图技巧。整体而言,本文强调了基于领域模型的数据库设计方法,突出了实际操作过程中的关键步骤和注意事项。 文章还对传统的数据库设计方法进行了对比,指出了基于领域模型的数据库设计方法相对于传统方法的优势,包括更好地与业务专家对齐领域知识、避免违反数据库设计范式、统一静态数据和动态逻辑等方面的优势。此外,文章还提出了两个思考题,引发读者对数据库设计中的一些常见问题进行思考。 总的来说,本文通过对数据库设计方法的详细介绍和与传统方法的对比,为读者提供了深入了解和思考数据库设计的方法和原则的机会。
《手把手教你落地 DDD》,新⼈⾸单¥59

全部留言(32)
- 最新
- 精选
 Jxin置顶
Jxin置顶 以下内容,仅个人补充,不一定正确。与大家探讨。 1.POJO(Plain Old Java Object) 和 POCO(Plain Old CLR Object)以及 PI(Persistence Ignorance)。在ddd里,持久化对象与具体的持久化实现机制之间应该是隔离的,虽然这可能是过度设计,但思路并没有毛病。所以,可能不需要特别关心。 2. not null 这个事,部分公司dba很可能会强制限制默认都是not null, 用def处理 null场景。 道理大家应该也懂。 数据库存储承载模型关系?第一次见,有新意,就是感觉载体不大稳定(存储随意,与领域模型本就没有1:1的必然性)。 3.表命名,有些公司规范可能要 xxx团队_xxx项目_xxx模块_xxx表名。图省事,因为CDC的时候表可能是打散的(比如,ODPS),这时候需要做去重+定位。(当然,你也可以CDC映射时转名字,就是可能要做多次,毕竟CDC不一定就到一个平台,手工多次重复操作?很容易出问题《墨菲定律》) 课后题: 1.没有业务含义的 id 作为主键?不确定是指主键名叫id,还是指主键值没有业务含义。两个都回答下,前者部分low的orm框架的插件限制(不叫id没法自动生成代码);后者是从数据库的性能(B+树要维护有序性)和内存空间占用(其他索引叶子节点空间大小)考虑,但事无绝对,例如 单索引 kv场景。(减少一次回表,抵消写时索引树排序, 无其他索引,无叶子节点空间浪费)。 2.避免了数据冗余并不意味着代码能支持重用,遵守与否都不解决核心问题,所以不用太纠结。更何况存储不见得一直都是关系性数据库。把它当成持久化的一种实现手段,大胆干有问题就改就是。过度在意反而可能影响模型设计,毕竟关系性数据库的范式包含性能等一系列考虑并不是很适应代码模型的设计。2023-01-03归属地:福建54
以下内容,仅个人补充,不一定正确。与大家探讨。 1.POJO(Plain Old Java Object) 和 POCO(Plain Old CLR Object)以及 PI(Persistence Ignorance)。在ddd里,持久化对象与具体的持久化实现机制之间应该是隔离的,虽然这可能是过度设计,但思路并没有毛病。所以,可能不需要特别关心。 2. not null 这个事,部分公司dba很可能会强制限制默认都是not null, 用def处理 null场景。 道理大家应该也懂。 数据库存储承载模型关系?第一次见,有新意,就是感觉载体不大稳定(存储随意,与领域模型本就没有1:1的必然性)。 3.表命名,有些公司规范可能要 xxx团队_xxx项目_xxx模块_xxx表名。图省事,因为CDC的时候表可能是打散的(比如,ODPS),这时候需要做去重+定位。(当然,你也可以CDC映射时转名字,就是可能要做多次,毕竟CDC不一定就到一个平台,手工多次重复操作?很容易出问题《墨菲定律》) 课后题: 1.没有业务含义的 id 作为主键?不确定是指主键名叫id,还是指主键值没有业务含义。两个都回答下,前者部分low的orm框架的插件限制(不叫id没法自动生成代码);后者是从数据库的性能(B+树要维护有序性)和内存空间占用(其他索引叶子节点空间大小)考虑,但事无绝对,例如 单索引 kv场景。(减少一次回表,抵消写时索引树排序, 无其他索引,无叶子节点空间浪费)。 2.避免了数据冗余并不意味着代码能支持重用,遵守与否都不解决核心问题,所以不用太纠结。更何况存储不见得一直都是关系性数据库。把它当成持久化的一种实现手段,大胆干有问题就改就是。过度在意反而可能影响模型设计,毕竟关系性数据库的范式包含性能等一系列考虑并不是很适应代码模型的设计。2023-01-03归属地:福建54 ╭(╯ε╰)╮自从入行,有四件事阻止了我在技术上的发展 一是数据库范式 二是单元测试 三是领域驱动设计 四是docker 这些东西我甚至比极客时间上的老师接触到的还要早,但是奇妙的事情是我的同事没有一个支持这四个概念,大部分都是持反对态度。同事的“阻挠”让我起了个大早,赶了个晚集。现在看着老师们布道,回想当年同事们看我的眼神,好像我是异教徒,伤感自己生不逢时,好人所恶。自己越是执念越会被社会教育。 随波逐流crud到现在,终于觉得自己熬出头,见到自己曾经执着并放弃的东西又回到了自己的身边。自己没有能力做到的事情看着别人做到,事实挺开心的。 希望老师的课程能让更多的人有所收获。
╭(╯ε╰)╮自从入行,有四件事阻止了我在技术上的发展 一是数据库范式 二是单元测试 三是领域驱动设计 四是docker 这些东西我甚至比极客时间上的老师接触到的还要早,但是奇妙的事情是我的同事没有一个支持这四个概念,大部分都是持反对态度。同事的“阻挠”让我起了个大早,赶了个晚集。现在看着老师们布道,回想当年同事们看我的眼神,好像我是异教徒,伤感自己生不逢时,好人所恶。自己越是执念越会被社会教育。 随波逐流crud到现在,终于觉得自己熬出头,见到自己曾经执着并放弃的东西又回到了自己的身边。自己没有能力做到的事情看着别人做到,事实挺开心的。 希望老师的课程能让更多的人有所收获。作者回复: 其实我和你有过类似的感受呀
2022-12-22归属地:广东414 老狗问题1: 有以下几个因素: 首先由业务含义的字段虽然业务上不允许重复,但有些时候会出现意料之外的场景,比如拿学生的名字作为主键就会遇到重名的问题,我父亲就是因为重名问题考虑把我名字里的一个字改了,避免了很多困扰。 其次业务主键一般都为字符型,考虑到数据库优化,有的时候递增主键会带来一些效率 再次业务上的唯一主键有些时候为联合主键,维护起来难度更加提升 再再次,解耦业务需求和技术实现。 问题2: 一致性问题是冗余字段必须要考虑的首要问题,就是冗余字段和冗余来源之间的一致性,另外就是性能问题了
老狗问题1: 有以下几个因素: 首先由业务含义的字段虽然业务上不允许重复,但有些时候会出现意料之外的场景,比如拿学生的名字作为主键就会遇到重名的问题,我父亲就是因为重名问题考虑把我名字里的一个字改了,避免了很多困扰。 其次业务主键一般都为字符型,考虑到数据库优化,有的时候递增主键会带来一些效率 再次业务上的唯一主键有些时候为联合主键,维护起来难度更加提升 再再次,解耦业务需求和技术实现。 问题2: 一致性问题是冗余字段必须要考虑的首要问题,就是冗余字段和冗余来源之间的一致性,另外就是性能问题了作者回复: 回答得很全面了 👍🏻
2022-12-31归属地:广东37 leesper前面阳了几天休息了一下,今天可以继续学习了,思考题: 1. 用没有业务含义的id作为主键我觉得是一种分离关注点的设计方式;业务是在变化的,今天适合用来做主键的业务字段,未来未必,索性约定俗成用id算了 2. 符合范式的数据库设计是为了写操作的高效(没有冗余就没有重复的写,同时避免疏忽大意造成漏写),适当的冗余是为了读操作的高效(不必join很多张表才能拿到自己想要的数据)。所以做冗余设计的数据主要用来读,而不是写,比如一些历史的交易流水数据什么的,经常变的数据就不适合做这种冗余设计了 钟老师我有个问题请教下:我记得前面几节课说过,员工和项目之间的“项目成员”关系、“工时记录”关系,不都是多对多吗?为啥不用联合主键的方式设计,而仍然采用id呢?
leesper前面阳了几天休息了一下,今天可以继续学习了,思考题: 1. 用没有业务含义的id作为主键我觉得是一种分离关注点的设计方式;业务是在变化的,今天适合用来做主键的业务字段,未来未必,索性约定俗成用id算了 2. 符合范式的数据库设计是为了写操作的高效(没有冗余就没有重复的写,同时避免疏忽大意造成漏写),适当的冗余是为了读操作的高效(不必join很多张表才能拿到自己想要的数据)。所以做冗余设计的数据主要用来读,而不是写,比如一些历史的交易流水数据什么的,经常变的数据就不适合做这种冗余设计了 钟老师我有个问题请教下:我记得前面几节课说过,员工和项目之间的“项目成员”关系、“工时记录”关系,不都是多对多吗?为啥不用联合主键的方式设计,而仍然采用id呢?作者回复: 两个思考题都回答得很到位。 关于您的问题,“项目成员”确实是“项目”和“员工”之间的多对多关系,但是项目和员工两者的关键字组合,并不能唯一确定一条项目成员。这是因为成员可以加入项目,再退出,再加入。也就是说,至少要在“项目”和“员工”的关键字基础上,再加一个“开始时间”才能做联合主键。这样在理论上是可以的,但不够简洁,而且未来可能还有变化,搞不好又要再加一个字段做主键。所以在这种情况下,干脆用一个ID算了。
2022-12-29归属地:广东25- Geek_8ac303表的主键不使用xx_id而是id,往往是被代码框架约束了,在很多orm模型里,save方法中是按照id不存在就插入,存在就更新 关于违反第三范式,主要还是看表关系和业务需要,如果一个表在搜索的时候可能用到外键表的数据,如果俩个表关联还好,多于俩表,性能会严重下降。在项目初期一般都是冗余字段,来提升搜索和查询数据的性能。业务发展起来有钱有人了,就要考虑搜索引擎了。 但是冗余了字段就要考虑,冗余字段是否会被更新,如果更新了是否要更新冗余字段,在大部分情况下都是些不经常更新的字段才冗余,为了效率,对这种不经常更新的字段就不考虑更新冗余字段
作者回复: 写得挺好👍🏻
2022-12-22归属地:广东3 - Geek_c33f40老师您好, 审计字段是否应该显示在领域模型上面? 因为有时候审计字段也是有业务含义的, 例如发起人, 群主. 我觉得分开会更好一些. 一方面领域模型和数据模型映射更加清晰一些. 一方面避免业务改动导致审议字段逻辑有变, 例如最后更新时间, 对于某些业务来说, 某些关联的变更不会影响到最后更新时间, 但对于审计来说可能对这条记录的任何修改都需要变更更新时间. 缺点是有部分会有重复
作者回复: 是的,感觉分开好些,看具体情况吧
2023-02-11归属地:广东2  aoe两个思考题: 1. 规则通俗易懂,一下就能掌握规律;降低认知复杂度; 2. 当冗余字段更新时,要更新所有相关数据,不然可能产生不可思议的 Bug。
aoe两个思考题: 1. 规则通俗易懂,一下就能掌握规律;降低认知复杂度; 2. 当冗余字段更新时,要更新所有相关数据,不然可能产生不可思议的 Bug。作者回复: 1,您说的是合理的一个点,另外,有业务含义的主键很难保证永远不会改变,但主键不应该改变。还有,复合主键在外键参照情况下可能造成主键膨胀
2022-12-26归属地:广东22
 escray有了前面的领域模型的分析和设计,再加上词汇表的加持,数据库设计看上去似乎水到渠成。 create_at、created_by、last_updated_at、last_updated_by 这四个审计字段确实好用。 文中对于外键约束的说法我比较赞同,就是清楚外键的逻辑关系,但是在实施的时候不使用数据库中的外键约束,而采用程序代码来保证。另外就是,可以考虑一定的数据冗余,这样保证查询的效率。 对于思考题: 1. 采用没有业务含义的 id 做主键应该已经是业界标准了吧,有业务含义的字段很难保证始终不会发生变化。另外,就是倾向于使用整型数字做主键,而不是那种很长的 UUID 字符串 2. 在反规范化设计的时候,同样需要清楚哪些部分是冗余;这些数据冗余甚至可以采用一定的步骤进行统一的清洗和更新。
escray有了前面的领域模型的分析和设计,再加上词汇表的加持,数据库设计看上去似乎水到渠成。 create_at、created_by、last_updated_at、last_updated_by 这四个审计字段确实好用。 文中对于外键约束的说法我比较赞同,就是清楚外键的逻辑关系,但是在实施的时候不使用数据库中的外键约束,而采用程序代码来保证。另外就是,可以考虑一定的数据冗余,这样保证查询的效率。 对于思考题: 1. 采用没有业务含义的 id 做主键应该已经是业界标准了吧,有业务含义的字段很难保证始终不会发生变化。另外,就是倾向于使用整型数字做主键,而不是那种很长的 UUID 字符串 2. 在反规范化设计的时候,同样需要清楚哪些部分是冗余;这些数据冗余甚至可以采用一定的步骤进行统一的清洗和更新。作者回复: 写得好👍🏻
2022-12-22归属地:广东22- ╭(╯ε╰)╮课后思考题 id这个名字算是一种约定大于配置,看到这个名字大家一眼就能识别出来它是表中的主键,背后的逻辑也会被本能的浮现在脑海里。沟通时,丢给对方一个id无需多言,如果使用有业务含义的字段名,那就不好意思了,大家坐下来互相battle一下,从设计到实现,各种细节扯皮一遍,别嫌麻烦 冗余的数据我个人观点是跟回表息息相关,两方面:一是如果数据库足够高级,我们能轻易得到自己需要的数据自然就不需要冗余;二是软件建模不同,结果数据是否冗余也不同,面向对象设计的好,映射到数据库上自然而然的是符合范式的。不需要花额外的功夫。
作者回复: 关于id给了一个新角度。关于冗余说得好,尤其最后一个点
2022-12-22归属地:广东2  py
py 1. id无感业务,不会被频繁变更;主键一般设为自增长,业务一般不符合;业务字段可能是string等非int字段,性能不高 2. 充分评估必要性;控制度,非必要不违反
1. id无感业务,不会被频繁变更;主键一般设为自增长,业务一般不符合;业务字段可能是string等非int字段,性能不高 2. 充分评估必要性;控制度,非必要不违反作者回复: 不错
2023-02-03归属地:上海21

