

13 | 实时统计:链路跟踪实时计算中的实用算法
徐长龙

该思维导图由 AI 生成,仅供参考
你好,我是徐长龙。
前几节课我们了解了 ELK 架构,以及如何通过它快速实现一个定制的分布式链路跟踪系统。不过 ELK 是一个很庞大的体系,使用它的前提是我们至少要有性能很好的三台服务器。
如果我们的数据量很大,需要投入的服务器资源就更多,之前我们最大一次的规模,投入了大概 2000 台服务器做 ELK。但如果我们的服务器资源很匮乏,这种情况下,要怎样实现性能分析统计和监控呢?
当时我只有两台 4 核 8G 服务器,所以我用了一些巧妙的算法,实现了本来需要大量服务器并行计算,才能实现的功能。这节课,我就给你分享一下这些算法。
我先把实时计算的整体结构图放出来,方便你建立整体印象。
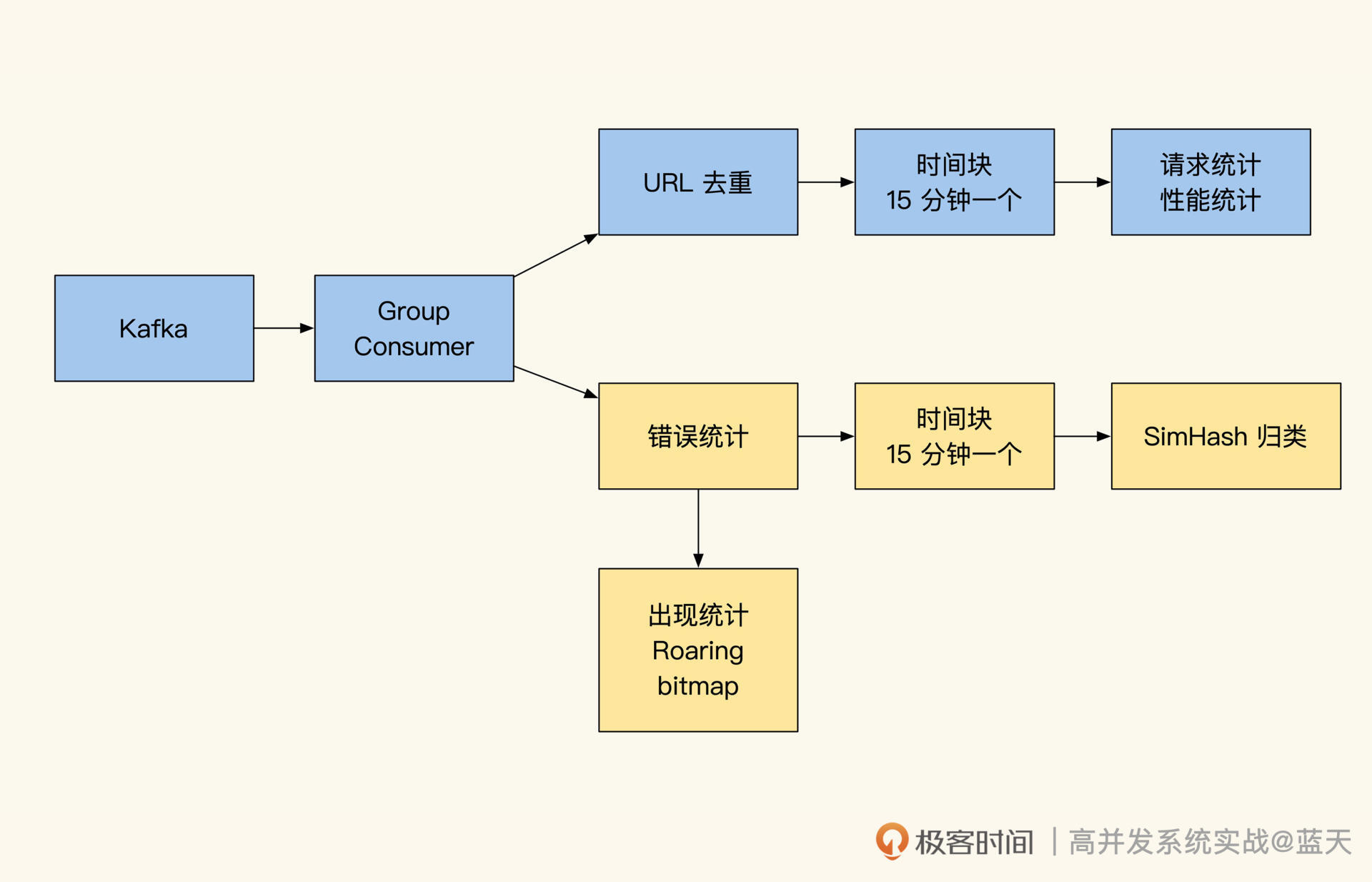
实时计算的整体结构图
从上图可见,我们实时计算的数据是从 Kafka 拉取的,通过进程实时计算统计 Kafka 的分组消费。接下来,我们具体看看这些算法的思路和功用。
URL 去参数聚合
做链路跟踪的小伙伴都会很头疼 URL 去参数这个问题,主要原因是很多小伙伴会使用 RESTful 方式来设计内网接口。而做链路跟踪或针对 API 维度进行统计分析时,如果不做整理,直接将这些带参数的网址录入到统计分析系统中是不行的。
同一个 API 由于不同的参数无法归类,最终会导致网址不唯一,而成千上万个“不同”网址的 API 汇总在一起,就会造成统计系统因资源耗尽崩掉。除此之外,同一网址不同的 method 操作在 RESTful 中实际也是不同的实现,所以同一个网址并不代表同一个接口,这更是给归类统计增加了难度。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

本文介绍了在实时计算中使用的一些实用算法,包括对URL去参数聚合、时间分块统计、错误日志聚类和bitmap实现频率统计。作者分享了在资源匮乏的情况下,如何通过巧妙的算法实现性能分析统计和监控。针对RESTful接口设计中的参数问题,提出了两种常用的解决方式:人工配置替换模板和数据特征筛选。通过将一段时间内的请求数据在内存中汇总统计,实现了对不同接口的性能统计。文章还提到了监控系统对细微问题的重要性,强调了对细微故障的排查和处理的必要性。此外,介绍了使用simhash算法进行错误日志聚类和bitmap实现频率统计的方法。通过这些算法和方法,读者可以更好地了解在资源匮乏情况下如何实现性能分析统计和监控,为实时计算提供了实用的技术参考。文章内容涵盖了实用的技术算法和方法,为读者提供了解决实时计算中性能分析统计和监控问题的思路和工具。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《高并发系统实战课》,新⼈⾸单¥59
《高并发系统实战课》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(2)
- 最新
- 精选
 Spoon还是以Restful API举例说明 GET geekbang.com/user/1002312/info => geekbang.com/user/*num*/info_GET PUT geekbang.com/user/1002312/info => geekbang.com/user/*num*/info_PUT DELETE geekbang.com/user/1002312/friend/123455 => geekbang.com/user/*num*/friend/*num*_DEL method: GET/PUT/DELETE url:geekbang.com/user/1002312/info geekbang.com/user/1002312/friend/123455 time: 请求时间,秒 可以用大数据HIVE或者阿里的MaxCompute进行离线分析,这里以我司MaxCompute为例: caoncat/regexp_replace参考文档 https://help.aliyun.com/document_detail/48973.html SELECT processed_url ,COUNT(*) As total_cnt ,MEDIAN(time) AS tp50_time ,AVG(time) As avg_time FROM ( SELECT concat(regexp_replace(url,"\d","*num*"),"_",method) AS processed_url ,time FROM soure_data ) as temp_statistics GROUP BY processed_url; 这里用离线数据分析的SQL举例,如果实时的类似 还有一种可以使用小时表同步方案做离线统计
Spoon还是以Restful API举例说明 GET geekbang.com/user/1002312/info => geekbang.com/user/*num*/info_GET PUT geekbang.com/user/1002312/info => geekbang.com/user/*num*/info_PUT DELETE geekbang.com/user/1002312/friend/123455 => geekbang.com/user/*num*/friend/*num*_DEL method: GET/PUT/DELETE url:geekbang.com/user/1002312/info geekbang.com/user/1002312/friend/123455 time: 请求时间,秒 可以用大数据HIVE或者阿里的MaxCompute进行离线分析,这里以我司MaxCompute为例: caoncat/regexp_replace参考文档 https://help.aliyun.com/document_detail/48973.html SELECT processed_url ,COUNT(*) As total_cnt ,MEDIAN(time) AS tp50_time ,AVG(time) As avg_time FROM ( SELECT concat(regexp_replace(url,"\d","*num*"),"_",method) AS processed_url ,time FROM soure_data ) as temp_statistics GROUP BY processed_url; 这里用离线数据分析的SQL举例,如果实时的类似 还有一种可以使用小时表同步方案做离线统计作者回复: 你好,目测这是另外一个方式了,很有趣,具体效果我还没有操作验证,maxcomputer这个需要云离线计算服务的支持。另外,如果是阿里云另外补充一个:阿里的日志中心支持聚类,也可以自动识别重复部分格式,聚合类似格式日志,不过有一定误判,比较简单方便,只是不能指定聚合字段和格式。
2023-04-02归属地:浙江 若水清菡对SQL不是很了解,接触到的SQL语句大致分为:增insert、删delete 、改update、查select这四类。其中查 select 的操作存在重复的可能性,如果是多人同时查询一个时间或者一个条件的数据,可以考虑根据select的参数聚合归类去重;增insert、删delete 、改update 都是原子操作,这三类操作都具有唯一性,可以提供语句操作模块,然后日志这边通过人工配置替换模板来聚合归类去重。
若水清菡对SQL不是很了解,接触到的SQL语句大致分为:增insert、删delete 、改update、查select这四类。其中查 select 的操作存在重复的可能性,如果是多人同时查询一个时间或者一个条件的数据,可以考虑根据select的参数聚合归类去重;增insert、删delete 、改update 都是原子操作,这三类操作都具有唯一性,可以提供语句操作模块,然后日志这边通过人工配置替换模板来聚合归类去重。作者回复: 你好,若水清菡,这里要注意如果查询语句条件参数不一样,但是语句一样是需要聚合成一条这样更好管理
2023-01-23归属地:北京
收起评论

