

12|引擎分片:Elasticsearch如何实现大数据检索?

该思维导图由 AI 生成,仅供参考
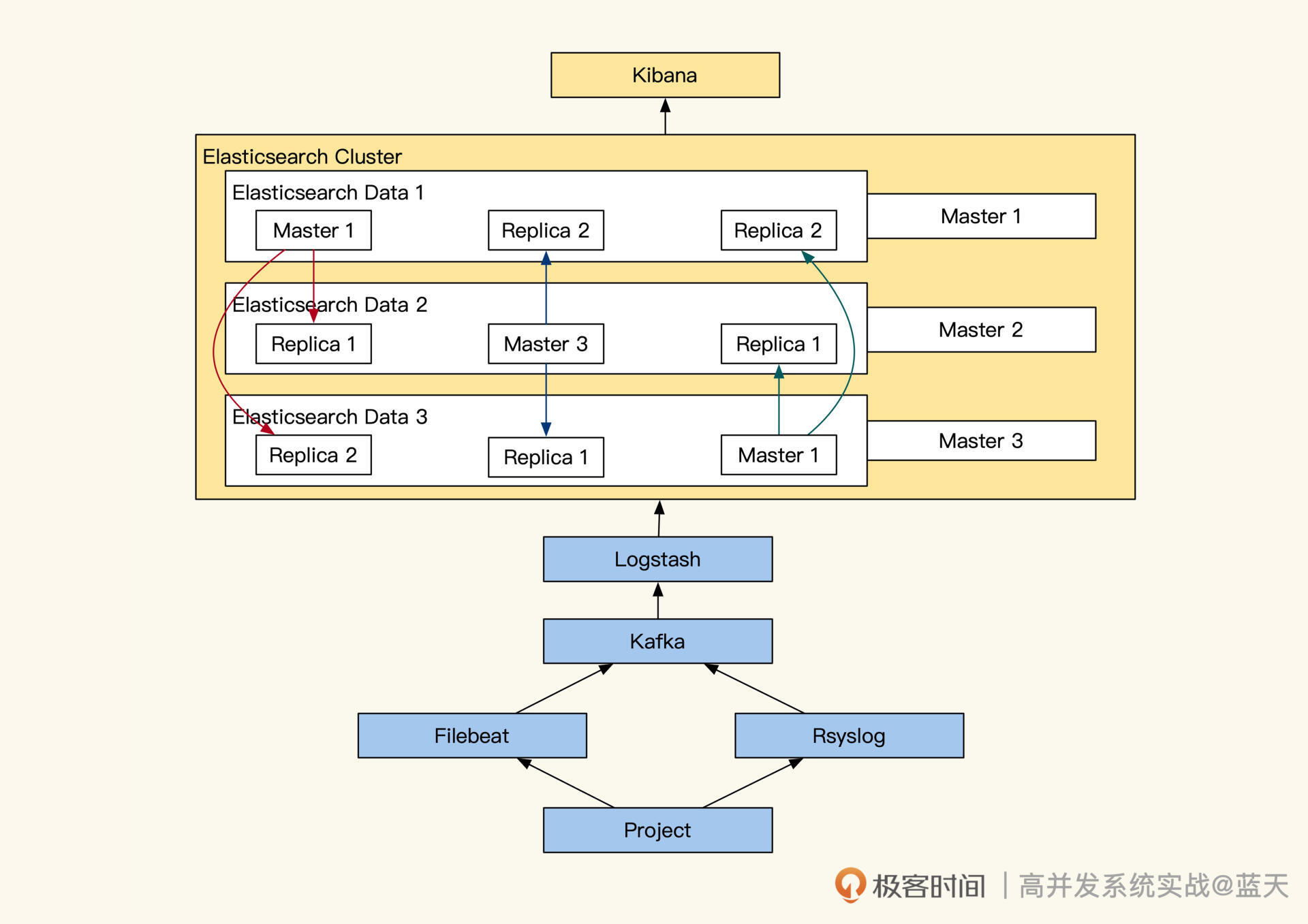
Elasticsearch 架构
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

Elasticsearch架构及其实现的大数据检索机制是本文的重点。文章深入介绍了ELK架构,包括数据流向、各节点角色及其作用,以及实际部署时的最佳实践。此外,详细解释了Elasticsearch的写存储机制,包括分片、索引、数据存储优化等方面的内容。文章还介绍了Elasticsearch的两次查询过程,包括查询请求的负载均衡、结果汇总排序等细节。通过对Lucene的具体实现,阐述了Elasticsearch通过组合小Lucene的服务实现大型分布式数据的全文检索。文章强调了Elasticsearch在分布式设计思路和算法优化方面的突出表现,如分布式共识算法、倒排索引、词权重、匹配权重、分词、异步同步、数据一致性检测等。总的来说,本文对于想要深入了解Elasticsearch的读者来说,是一篇值得阅读的文章。
《高并发系统实战课》,新⼈⾸单¥59

全部留言(5)
- 最新
- 精选
- Geek4892老师好,答疑课堂后续还会更新吗
作者回复: 你好,如果有问题可以直接在文章下面询问,等问题足够多后会和小编一起看看做合集
2023-10-19归属地:江苏  王建坤es是先获取到shardid集合然后再去请求这些shard来获取数据(https://jiankunking.com/elasticsearch-search-source-code-analysis.html); 文中说的,请求所有data节点是指到shardid集合获取数据?
王建坤es是先获取到shardid集合然后再去请求这些shard来获取数据(https://jiankunking.com/elasticsearch-search-source-code-analysis.html); 文中说的,请求所有data节点是指到shardid集合获取数据?作者回复: 你好,建坤,这个页面是白页。另外这个如何工作的方式是取决于配置的不是固定的。具体有几种方式,这里单独拿出他做例子只是为了破冰,打破固定思维
2023-05-22归属地:山东 Spoon文章:Elasticsearch 每次查询都是请求所有索引所在的 Data 节点,查询请求时协调节点会在相同数据分片多个副本中,随机选出一个节点发送查询请求,从而实现负载均衡 问题: 1.请求所有索引所在的 Data 节点,这个Data节点是什么?和普通数据节点有什么区别? 2.如果所有索引放在一个Data节点,是不是会有容量限制? 3.如果将索引分片,放在多个节点,是不是又陷入了数据定位的问题?
Spoon文章:Elasticsearch 每次查询都是请求所有索引所在的 Data 节点,查询请求时协调节点会在相同数据分片多个副本中,随机选出一个节点发送查询请求,从而实现负载均衡 问题: 1.请求所有索引所在的 Data 节点,这个Data节点是什么?和普通数据节点有什么区别? 2.如果所有索引放在一个Data节点,是不是会有容量限制? 3.如果将索引分片,放在多个节点,是不是又陷入了数据定位的问题?作者回复: 你好,spoon,这个请求偷懒的方式是请求所有data节点,如果没有则不返回,精致一点的方式是获取到data分布在哪几组服务器上。1、data节点是存储节点,同时也可以设置拥有计算查询服务能力。2、会有容量限制同时还会存在性能不能扩展问题。3、数据定位必然存在,文中提及会请求所有data节点就是因为这个问题。
2023-04-02归属地:浙江
 徐石头来公司做的第一件事就是把搜索从mysql迁移到Elasticsearch,然后用CQRS架构解析binlog写入,Elasticsearch,用Elasticsearch做app内的内容搜索功能,我猜测极客时间的搜索功能也是用的Elasticsearch。 在做搜索相关的业务首选的便是Elasticsearch,所以如果我来实现Elasticsearch最先解决的功能便是分词和倒排索引设计,至于链路追踪和日志采集相关的组件,从业务角度我觉得地位没有搜索重要,优先级没有那么高。
徐石头来公司做的第一件事就是把搜索从mysql迁移到Elasticsearch,然后用CQRS架构解析binlog写入,Elasticsearch,用Elasticsearch做app内的内容搜索功能,我猜测极客时间的搜索功能也是用的Elasticsearch。 在做搜索相关的业务首选的便是Elasticsearch,所以如果我来实现Elasticsearch最先解决的功能便是分词和倒排索引设计,至于链路追踪和日志采集相关的组件,从业务角度我觉得地位没有搜索重要,优先级没有那么高。作者回复: 你好,感谢你的分享!
2022-12-16归属地:内蒙古 John老师能否列一下相关的扩展阅读资料,比如词频统计,search_type 详解之类的,不胜感激
John老师能否列一下相关的扩展阅读资料,比如词频统计,search_type 详解之类的,不胜感激作者回复: 你好,John,在文章中有提及,我认为有帮助的可以先看:分布式共识算法、倒排索引、词权重、匹配权重、分词、异步同步、数据一致性检测,看完这些后,如果还有兴趣再深入挖掘一下其他方面
2022-11-20归属地:北京

