

08|系统隔离:如何应对高并发流量冲击?

该思维导图由 AI 生成,仅供参考
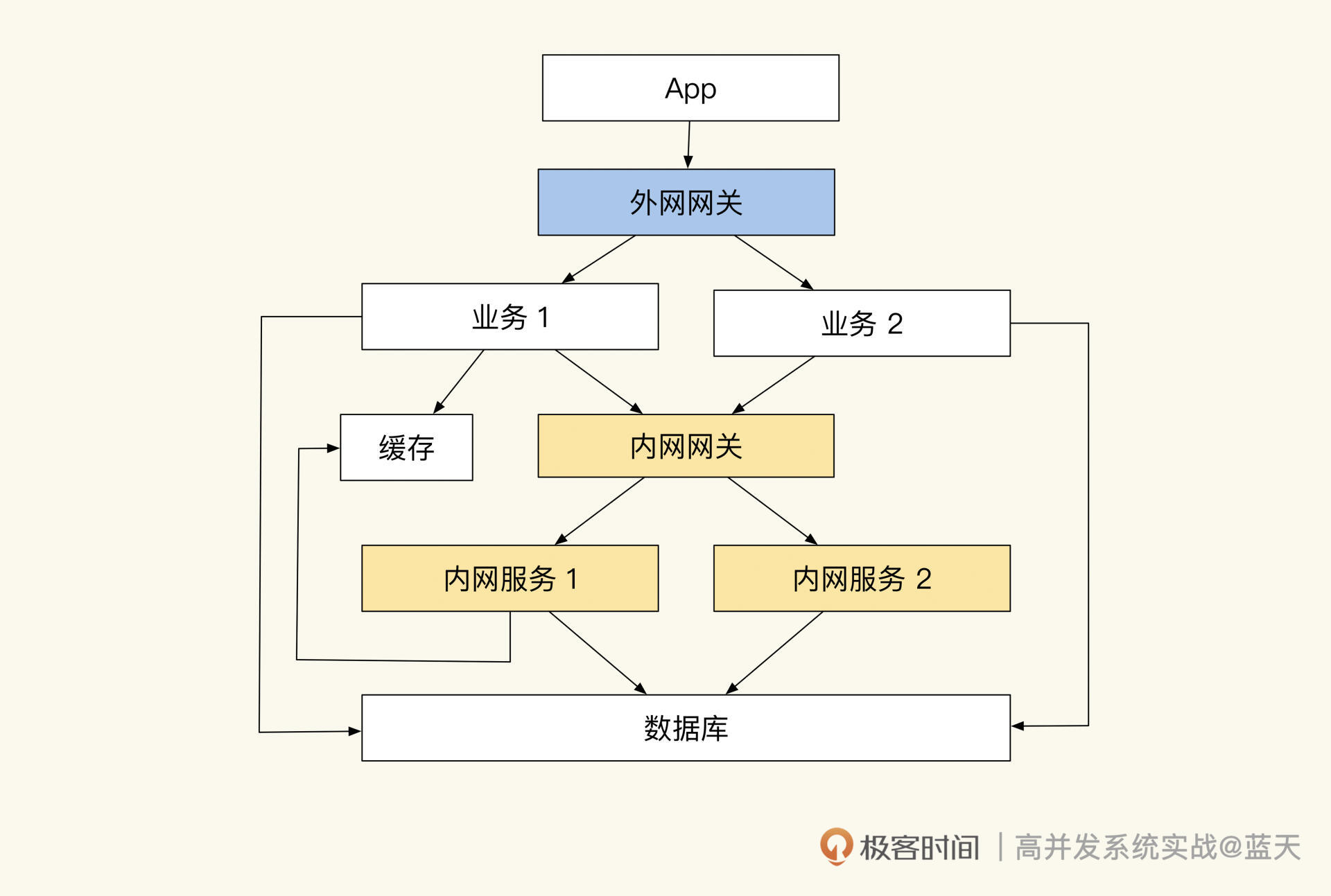
拆分部署和物理隔离
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

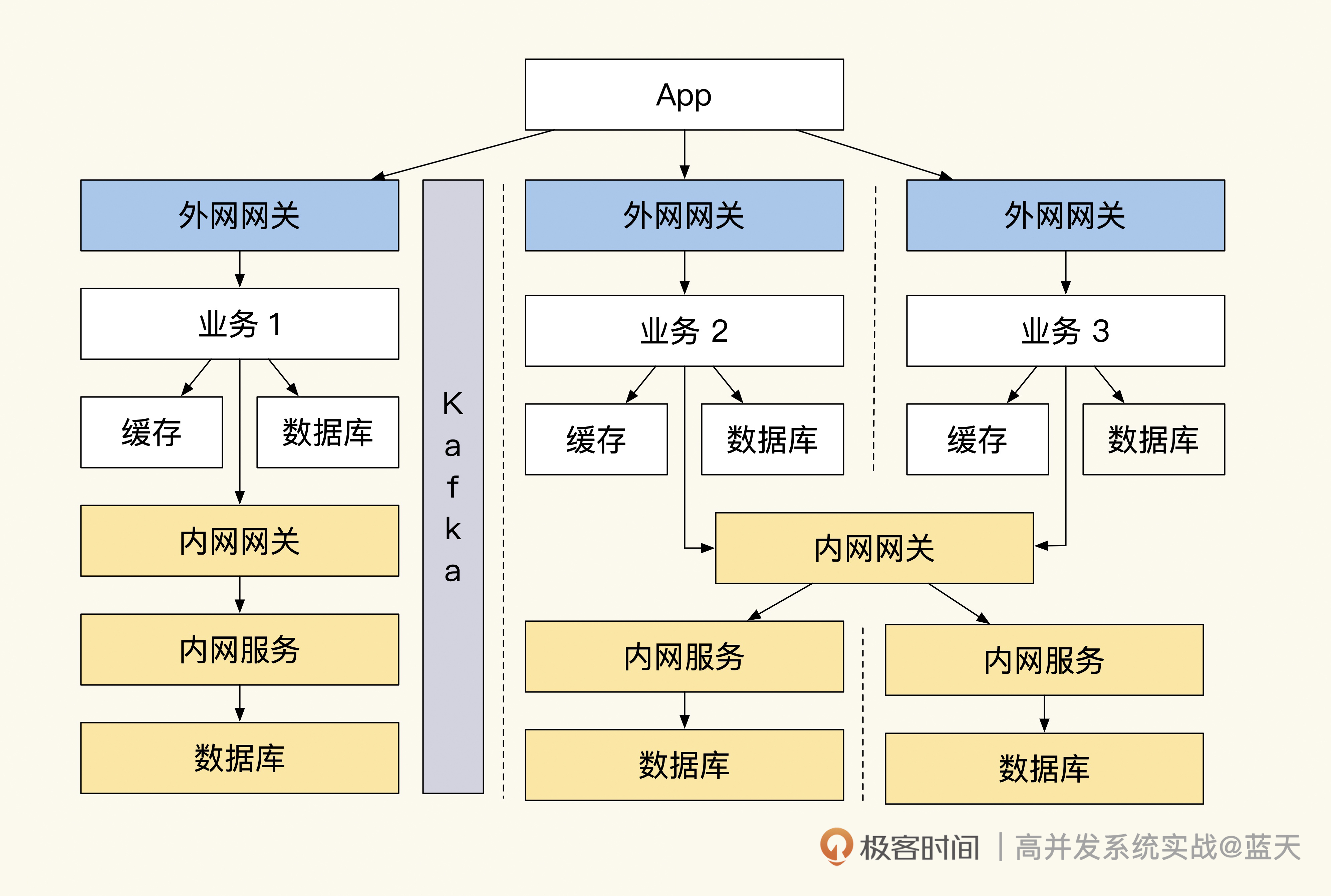
本文介绍了如何应对高并发流量冲击的系统隔离方法。作者分享了在教育培训公司系统崩溃的经历,并指出系统隔离性不足导致业务相互影响。为提高系统稳定性,作者提出了拆分部署和物理隔离、网关隔离和随时熔断、减少内网API互动等改造方案。其中,拆分部署和物理隔离通过独立集群和数据库实现内外网服务隔离;网关隔离和随时熔断则通过外网和内网网关限流和鉴权,以及外网服务断开内网网关后仍能独立运转来保证系统独立性;减少内网API互动则通过数据推送和锁定、外网业务决策库存等方式实现内外网隔离。最后,作者强调了保证数据同步单向性的重要性,并介绍了使用队列同步数据的方法。整体而言,本文通过实际案例和具体方案,深入浅出地介绍了系统隔离的重要性和实施方法,对于需要应对高并发流量冲击的技术人员具有一定的借鉴意义。文章通过介绍Kafka分布式队列的优点和数据同步的复杂性,强调了保证数据顺序性的重要性,以及如何利用Kafka实现数据同步和流量控制。同时,文章还总结了系统隔离的关键特性,包括接口网关、熔断内网接口、数据推送和消息队列投递等。这些方法和技术特点为读者提供了在实际生产过程中实践系统隔离方案的指导和思路。
《高并发系统实战课》,新⼈⾸单¥59

全部留言(11)
- 最新
- 精选
 LecKey外网与没网的区别: 外网是一般是针对用户端,直接对接用户使用,需要做公网解析; 内网一般是公司技术服务节点,不需要公网解析且不对外服务,都是外网服务上做单独解析才能访问内网服务,访问内网会比公网获取数据速度更快,减少了一层解析。 一般大点的公司都会做外网和内网隔离,以保障服务安全和稳定。
LecKey外网与没网的区别: 外网是一般是针对用户端,直接对接用户使用,需要做公网解析; 内网一般是公司技术服务节点,不需要公网解析且不对外服务,都是外网服务上做单独解析才能访问内网服务,访问内网会比公网获取数据速度更快,减少了一层解析。 一般大点的公司都会做外网和内网隔离,以保障服务安全和稳定。作者回复: 你好,这个思考没毛病
2022-11-09归属地:北京23 dk.wu“不同步”是否应该调整为“没同步”? 这块可以理解为数据同步场景的一个警示牌,如何做到数据同步完整性的检测机制和补偿机制? 没同步的数据可以识别为三种情况:(1)外网服务端推送异常(2)内网服务消费异常(3)还在队列排队(4)其他。 从隔离性出发,可以独立一个审计检测服务,对比内外网已同步服务,识别到的未同步数据,可以触发重新走kafka同步。至于识别的方法,是traceId还是其他业务Id,还得看抽象通用性。
dk.wu“不同步”是否应该调整为“没同步”? 这块可以理解为数据同步场景的一个警示牌,如何做到数据同步完整性的检测机制和补偿机制? 没同步的数据可以识别为三种情况:(1)外网服务端推送异常(2)内网服务消费异常(3)还在队列排队(4)其他。 从隔离性出发,可以独立一个审计检测服务,对比内外网已同步服务,识别到的未同步数据,可以触发重新走kafka同步。至于识别的方法,是traceId还是其他业务Id,还得看抽象通用性。作者回复: 不错,这里补充一句,如果是单方向的数据同步可以给数据都带上一个通用的版本号,要同步的数据如果有变更就+1这个版本号,这样很方便对比筛选。这样做通用服务可以更抽象一些
2023-02-25归属地:广东1 Spoon用户在外网业务系统下单购买一个商品时,外网服务会扣减本地缓存中的库存。库存扣减成功后,外网会创建一个订单并发送创建订单消息到消息队列中 针对这段有以下疑问 1.库存扣减+订单创建应该是一个事务操作,创建订单消息并发送是在事务内还是在事务外? 2.针对问题1,如果在事务内,因为消息发完,下游收到这个消息(此时事务未提交),下游并没有查到该订单,此时的解决方案有哪些? 3.针对问题1,如果在事务外,消息发送失败怎么办(事务已经提交,怎么回滚)?
Spoon用户在外网业务系统下单购买一个商品时,外网服务会扣减本地缓存中的库存。库存扣减成功后,外网会创建一个订单并发送创建订单消息到消息队列中 针对这段有以下疑问 1.库存扣减+订单创建应该是一个事务操作,创建订单消息并发送是在事务内还是在事务外? 2.针对问题1,如果在事务内,因为消息发完,下游收到这个消息(此时事务未提交),下游并没有查到该订单,此时的解决方案有哪些? 3.针对问题1,如果在事务外,消息发送失败怎么办(事务已经提交,怎么回滚)?作者回复: 同步必然会有代价的。推荐在事务外。一般来说降低发送失败概率更划算,我这采用的是落盘后扫描发送队列,最后如果发送失败,每天晚上还有脚本核对,发现差异人工分析对比。补下相关遗漏漏洞
2023-03-29归属地:浙江- walle斌这里边的kafka换成rocketmq 没有任何问题还多了更多的特性。。
作者回复: :)分布式队列思路都是类似的,有很多特性是雷同的,实际用起来后会发现总需要放弃一些特性
2023-03-29归属地:北京  👽“同时,我们在开发期间要时刻注意,内网网关在流量增大的时候要做熔断,这样可以避免外网服务强依赖内网接口,保证外网服务的独立性,确保内网不受外网流量冲击。并且外网服务要保证内网网关断开后,仍旧能正常独立运转一小时以上。” 内网断网后,仍然可访问一小时,解决方案,是把所有的操作记录缓存到外网服务内部,然后等着内网服务上线后,再推送给内网服务么?这部分细节本文没有体现,有点疑惑。
👽“同时,我们在开发期间要时刻注意,内网网关在流量增大的时候要做熔断,这样可以避免外网服务强依赖内网接口,保证外网服务的独立性,确保内网不受外网流量冲击。并且外网服务要保证内网网关断开后,仍旧能正常独立运转一小时以上。” 内网断网后,仍然可访问一小时,解决方案,是把所有的操作记录缓存到外网服务内部,然后等着内网服务上线后,再推送给内网服务么?这部分细节本文没有体现,有点疑惑。作者回复: 你好,这里是有讲到的,主要是用队列将结果推送到内网,将数据的一些决策放到外网服务去决策
2023-03-24归属地:广东 ARM“这个特性让我们可以做很多灵活的操作,甚至可以在流量高峰期,暂时停掉内网消费服务,待系统稳定后再开启,落地用户的交易” 那订单的状态流转会不会出问题,因为消息都在kafka没落库。比如我买东西,创建订单,我支付的时候,怎么显示已支付?退费怎么退费?
ARM“这个特性让我们可以做很多灵活的操作,甚至可以在流量高峰期,暂时停掉内网消费服务,待系统稳定后再开启,落地用户的交易” 那订单的状态流转会不会出问题,因为消息都在kafka没落库。比如我买东西,创建订单,我支付的时候,怎么显示已支付?退费怎么退费?作者回复: 你好,ARM,所有操作都在外网服务决策,内网只是同步结果
2023-01-08归属地:北京
 Layne老师,在上面说到数据指定到Kafka某个分区上,这样会出现数据倾斜问题吧,导致Kafka的集群性能出问题吧?
Layne老师,在上面说到数据指定到Kafka某个分区上,这样会出现数据倾斜问题吧,导致Kafka的集群性能出问题吧?作者回复: 你好,Layne,你说到了关键点,所以分区依据最好是能保证一定随机性,一般常见使用自增id或者某些比较分散的数据,如uid及订单id是snowflake算出来的,并且hash分区的算法足够发散
2022-12-01归属地:北京5 RiseL外网服务要保证内网网关断开后,仍旧能正常独立运转一小时以上,数据都是内网来的,内网挂了,外网功能还怎么正常运行呢
RiseL外网服务要保证内网网关断开后,仍旧能正常独立运转一小时以上,数据都是内网来的,内网挂了,外网功能还怎么正常运行呢作者回复: 你好,risel,这就是隔离的关键,业务用数据都推送到业务内了
2022-11-24归属地:北京3 花花大脸猫可以通过给数据打tag或者版本号,然后周期性的对比同一笔数据的tag或者版本号是否一致,如果不一致,以tag或者版本号新的那一条为准
花花大脸猫可以通过给数据打tag或者版本号,然后周期性的对比同一笔数据的tag或者版本号是否一致,如果不一致,以tag或者版本号新的那一条为准作者回复: 你好,大脸猫,这个数据量会大一些并且全局要有tso服务才行
2022-11-11归属地:北京- LecKey课后思考:每条数据都有唯一的数据标识(一般是自增id,或者有规律一串数字唯一id),而且一般都是小到大,根据这个最大值应该就能判断出来。 如果数据不同步应该找到对应数据节点做补偿操作
作者回复: 你好,加深下问题:那么更新操作同一条数据如何避免
2022-11-09归属地:北京5

