

21|模型测评:如何评估大模型的表现?
独行

你好,我是独行。
这一节课我们来聊聊模型测评,和我们软件测试一样,模型训练完也需要进行测试。软件测试我们一般会关注功能完整性、性能水平、运行稳定性等。大模型也一样,它会关注推理效率、性能等等。我们先来了解下各个厂商为什么要做模型测评。
背景
一方面,不论是软件还是大模型,厂商都需要对其功能有效性进行测试,通过业界相对标准的方式去测,可以看清楚自己产品的真正实力以及和其他竞争产品的差距。另一方面,一些大厂希望通过刷新一些著名榜单,来提升自己产品的知名度和竞争力,比如在大模型之前,比较出名的就是各个数据库厂商,像 TiDB、阿里云的 PolarDB 等等,都会在自己的官方网站上介绍其性能指标,比较出名的基准像 TPC-C、TPC-C、Sysbench 等,最后结论就是比 MySQL 性能提升多少多少这种。不可否认,这确实是一种好的方式。
如果你关注各个大模型厂商的网站,一定会经常看到下面这样的评测数据,这是阿里云通义千问介绍页面上放出的一组评测数据。
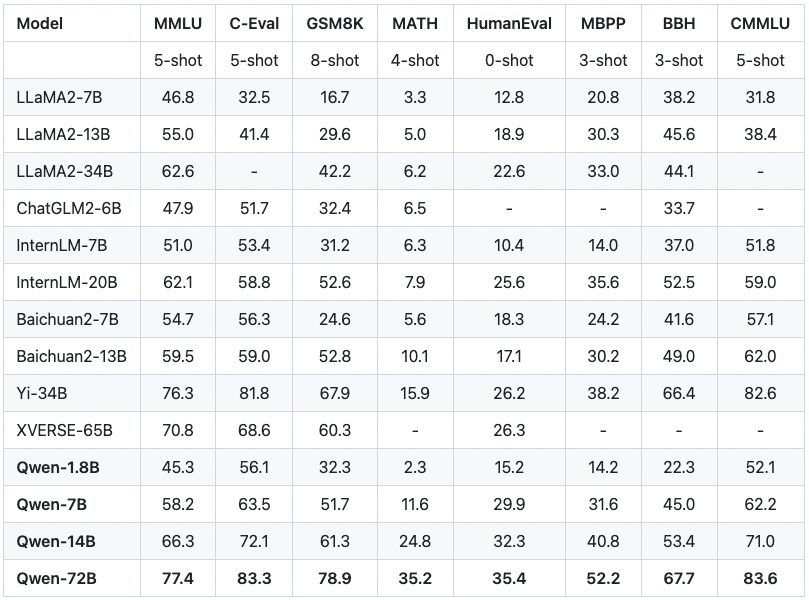
Qwen 系列模型相比同规模模型均实现了效果的显著提升。我们评测的数据集包括 MMLU、C-Eval、 GSM8K、 MATH、HumanEval、MBPP、BBH 等数据集,考察的能力包括自然语言理解、知识、数学计算和推理、代码生成、逻辑推理等。Qwen-72B 在所有任务上均超越了 LLaMA2-70B 的性能,同时在 10 项任务中的 7 项任务中超越 GPT-3.5*。*
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

1. 模型测评是对大模型功能有效性进行测试的重要环节,厂商通过业界标准的方式进行测评,以展示产品实力和竞争力。 2. 数据集对于大模型的训练至关重要,如C-Eval包含13948个多项选择题,保证数据质量需要手工处理,特别是对于Latex类型的数学公式及推理过程。 3. 通用大语言模型主要关注的测评维度包括自然语言理解、知识、数学计算和推理、代码生成、逻辑推理等,评测维度的细分不断更新和迭代。 4. 基准测试是用于评估系统性能的标准化测试方法,通过定义一套测试方法和配套测试数据集,保证公平性,展示系统的性能。 5. 榜单猫腻存在于大厂公布的榜单中,厂商宣称自己的模型是最强的,但实际使用下来,还没有哪个大模型已经超越GPT-4,因此榜单需要谨慎参考。 6. 少样本和零样本是针对prompt提出的两种模式,在测评模型能力时需要考虑这两种情况,少样本和零样本分别对应给模型打样和直接问答。 7. SOTA是描述机器学习中取得某个任务上当前最优效果的模型,用于形容在某一方面达到业界领先的技术或方法。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《AI 大模型实战高手课》,新⼈⾸单¥59
《AI 大模型实战高手课》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
精选留言
由作者筛选后的优质留言将会公开显示,欢迎踊跃留言。
收起评论