

19|深入理解DeepSpeed,提高大模型训练效率
独行

你好,我是独行。
前面第 16 课,我们从 0~1 手敲了 Transformer,并且进行了一次完整的训练,当时我用的 A10-24G 显卡,准备了 500M 的训练文本,结果预估需要 1 个月时间才能跑完,可见训练对机器的要求有多么高,我们使用的数据集大小才 500M,一般训练一个大模型,绝对不止这么点数据,而且参数规模也会更大。
据我所知,GPT-3 和 GLM-130B 这种千亿规模的大模型,训练周期基本在 3 个月左右,所以按照我们目前的这种做法,肯定是不行的。那在实际的训练过程中,如何才能提高训练速度呢?
答案是使用分布式训练,目前比较流行的训练框架有微软的 DeepSpeed 和 NVIDIA 的 NCCL 等,这节课我们就主要聊聊微软的 DeepSpeed。
DeepSpeed
DeepSpeed 是由微软开发的一个非常优秀的分布式训练库,专为大规模和高效的深度学习训练设计,在分布式训练领域提供了多项创新的技术,比如并行训练、并行推理、模型压缩等。你可以看一下官方说明的 4 个创新点。

简单整理下:
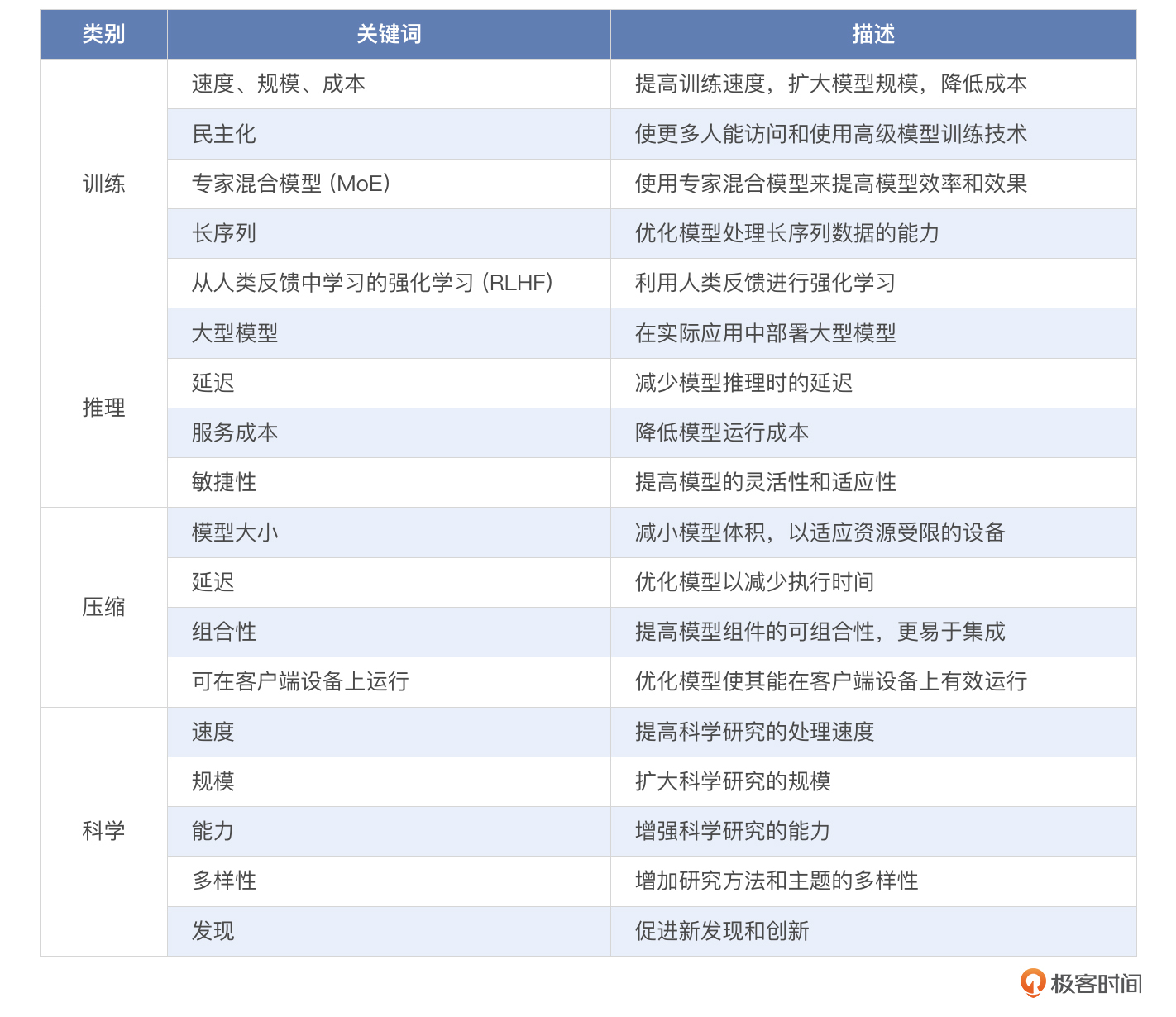
下面我就向你依次介绍 DeepSpeed 在这几方面的能力。
训练
对于复杂的深度学习模型,除了模型设计具有挑战性之外,使用先进的训练技术也尤为重要,比如分布式训练、混合精度、梯度累积和检查点等。DeepSpeed 在这些方面比较擅长,可灵活组合三种并行方法:数据并行性、管道并行性和模型并行性,简称 3D 并行性,可适应不同工作负载的需求。目前已经支持超过一万亿超大参数的模型,实现了近乎完美的内存扩展和吞吐量扩展效率。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

1. DeepSpeed是微软开发的分布式训练库,提供了多项创新的技术,包括数据并行性、模型并行性和管道并行性,以适应不同工作负载的需求。 2. DeepSpeed通过Dynamic SplitFuse技术提高了推理速度和吞吐量,同时保证语义的完整性。 3. DeepSpeed Compression库可以轻松压缩模型,提供更快的速度、更小的模型大小,并显著降低压缩成本,包括量化、修剪和减少层数等技术。 4. 微软DeepSpeed团队推出了DeepSpeed4Science计划,旨在通过人工智能系统技术创新构建独特的能力,帮助领域专家解开科学谜团。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《AI 大模型实战高手课》,新⼈⾸单¥59
《AI 大模型实战高手课》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
精选留言
由作者筛选后的优质留言将会公开显示,欢迎踊跃留言。
收起评论