

14|以Llama 3为例讲透QLoRA量化+微调
黄佳

你好,我是黄佳。
在上节课中,我们以 Qwen 模型为例,探讨了一下大语言模型参数高效微调的基本方法,重点介绍了当下最热门的 LoRA 技术,并通过 PEFT 框架实际操作了一把用 Alpaca 风格的中文数据微调 Qwen 模型。
不过上节课还有些地方没有讲透彻,比如 LoRA 的数学原理究竟是什么?在微调的同时,还有哪些压缩大模型的技巧?这一次,我们就换一个模型——LLM 开源之王 Llama 3,来继续讨论一下微调和量化的话题。
Llama 3 模型介绍
Llama 是由 Meta AI 最新发布的一个大语言模型家族,其中 Llama 3 是截至目前(2024 年 7 月)的最强开源模型。
Llama 系列模型开启了大语言模型(真正能用的、具有商用价值这个级别的)开源的先河,它的发展历程简单总结如下:
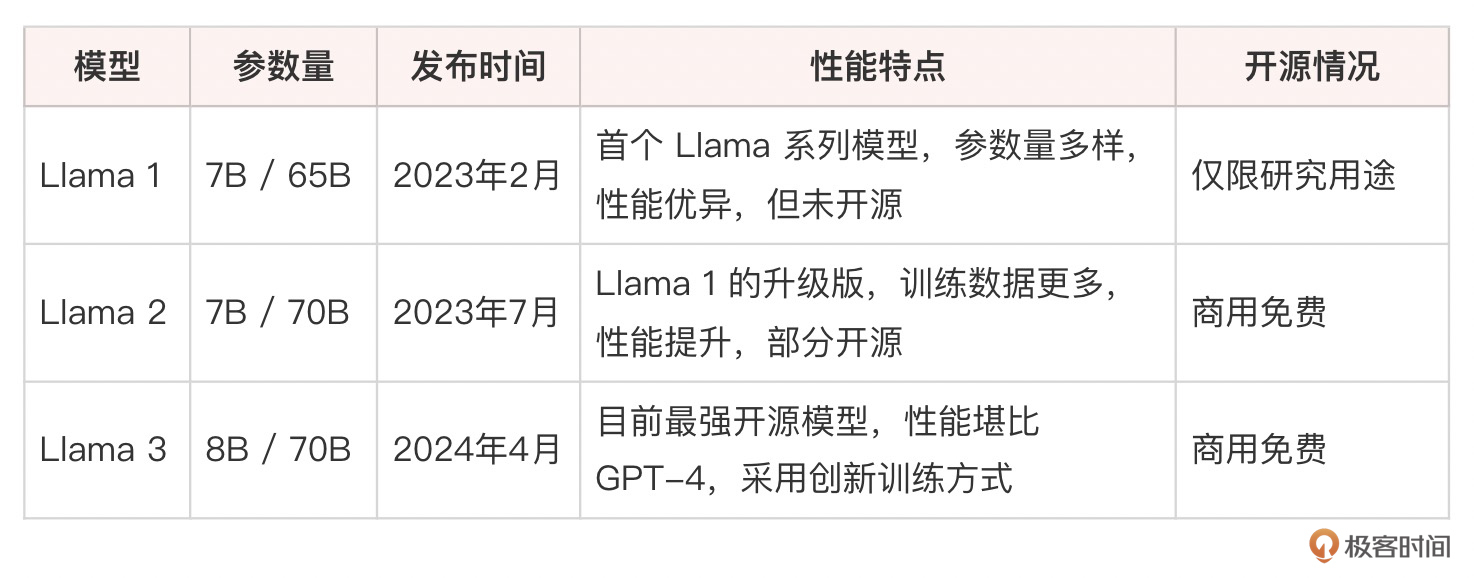
Llama 3 拥有两个版本,一个是 8B(80 亿)参数模型,另一个是 70B(700 亿)参数模型。这两个版本都相较于之前的迭代有了显著的性能提升,在多项基准测试中表现出色,与 GPT-4 和 Claude 等领先模型相比同样具有竞争力。
Llama 3-8B:具有非常好的性价比,性能在同级别的模型中很突出。测试显示它在问答、摘要和指令执行等任务中表现良好。
Llama 3-70B:70B 模型在更复杂的任务中表现卓越。在 MMLU(一般知识)和 HumanEval(编码)等基准测试中表现优异。这个模型特别擅长理解和生成细致入微的回应,在某些任务中可以与 GPT-4 等更大模型竞争。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

1. Llama 3是Meta AI最新发布的大语言模型家族,拥有8B(80亿)参数模型和70B(700亿)参数模型两个版本,其中Llama 3是目前最强的开源模型。 2. QLoRA是LoRA和量化相结合的变体,使用低精度表示增量矩阵,大幅降低了存储和带宽需求,使其更容易在资源受限的环境中部署。 3. 量化是用较低的数值精度表示原本的浮点数,可以在模型训练完成后进行(Post-training Quantization,PTQ),也可以在训练过程中同步进行(Quantization-aware training,QAT)。 4. Llama 3的训练数据主要来自于与人类助手的对话互动,这些数据被称为“自我指导”数据,更贴近实际应用场景,有助于减少有害内容的出现。 5. QLoRA通过瘦身模型、提升推理速度,但以损失一部分精度为代价。 6. Alpaca数据集包含52K个由Llama自己生成的指令-输出对,引起了开发者社区的广泛兴趣,催生出一系列基于Llama的微调项目。 7. Meta在训练Llama时采用了一种创新的方式来收集和筛选训练数据,更贴近实际应用场景,有助于减少有害内容的出现。 8. PEFT是一个强大的参数高效微调框架,集成了各种微调技术,包括Adapter、Prefix Tuning、P-Tuning、LoRA、QLoRA等。 9. bitsandbytes是一个优化库,主要用于加速和优化大规模机器学习模型的训练和推理,在资源受限的环境下进行深度学习任务。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《大模型应用开发实战》,新⼈⾸单¥59
《大模型应用开发实战》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
精选留言
由作者筛选后的优质留言将会公开显示,欢迎踊跃留言。
收起评论